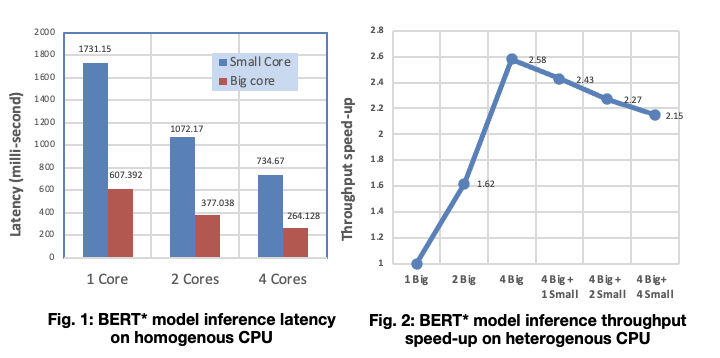
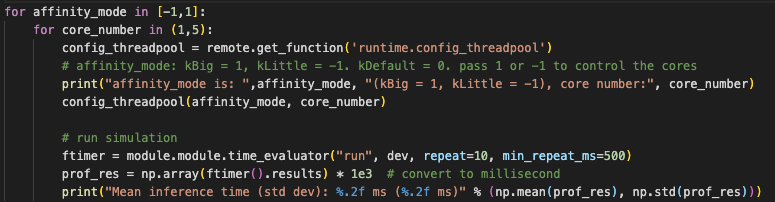
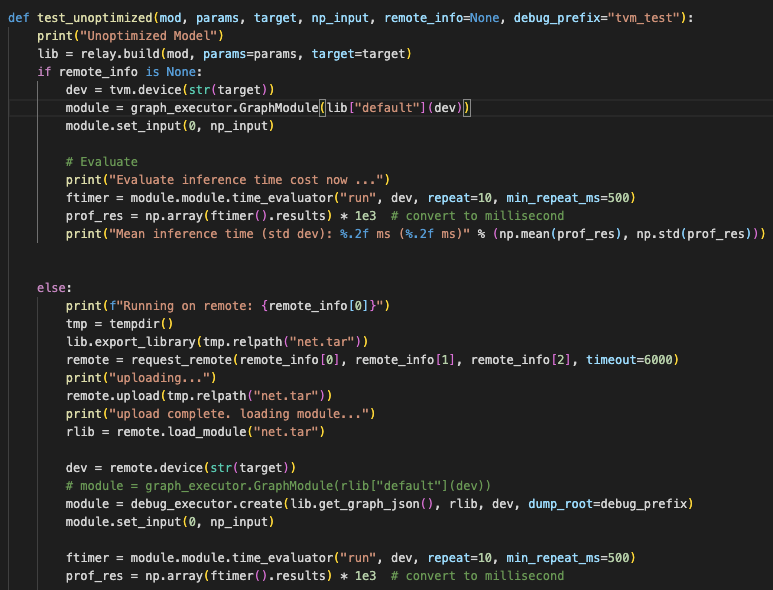
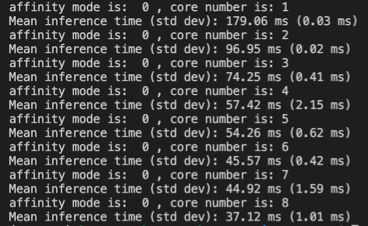
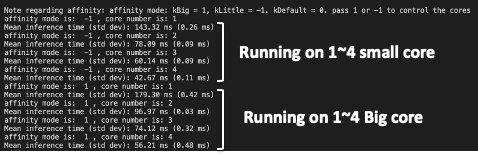
I’ve got 4 LITTLE cores and 4 big cores. In other code I’ve written for these platforms, I’ve been able to use all 8 cores, to observe interesting behaviour.
I’ve looked at this thread, and opinion seems to be mixed, though @eqy seems to think it’s possible. A linked thread suggests that having code such as:
if self.big_little:
config_func = self.session.get_function('runtime.config_threadpool')
# config_func(1, 1) # use 1 big core
# config_func(1, 2) # use 2 big cores
#config_func(-1, 1) # use 1 small core
# config_func(-1, 2) # use 2 small cores
config_func(4, 4)
Might work, however it has not for me.
This thread discusses binding of threads, but playing around with the environment variables has not changed my behaviour.
As the APIs have developed since prior threads, is there now a more canonical way of doing this? I’m not worried about clever load balancing for now, I would just like to run with 8 threads.