I’ve got 4 LITTLE cores and 4 big cores. In other code I’ve written for these platforms, I’ve been able to use all 8 cores, to observe interesting behaviour.
I’ve looked at this thread, and opinion seems to be mixed, though @eqy seems to think it’s possible. A linked thread suggests that having code such as:
if self.big_little:
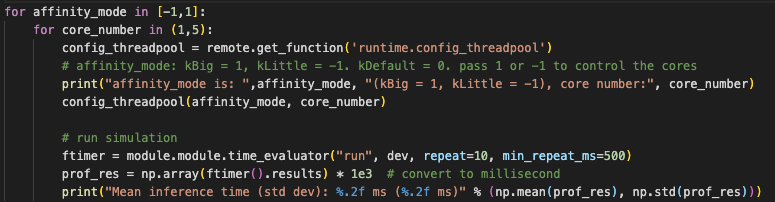
config_func = self.session.get_function('runtime.config_threadpool')
# config_func(1, 1) # use 1 big core
# config_func(1, 2) # use 2 big cores
#config_func(-1, 1) # use 1 small core
# config_func(-1, 2) # use 2 small cores
config_func(4, 4)
Might work, however it has not for me.
This thread discusses binding of threads, but playing around with the environment variables has not changed my behaviour.
As the APIs have developed since prior threads, is there now a more canonical way of doing this? I’m not worried about clever load balancing for now, I would just like to run with 8 threads.
But I am wondering how can I adjust the numbers of the thread. I have checked tvm/src/runtime/threading_backend.cc file and find out the default setting is using 4 big cores.
I have tried to adjust the numbers of the thread (e.g. only using 1 small core, or only using 3 big cores.)
but it seems the inference still using 4 cores.
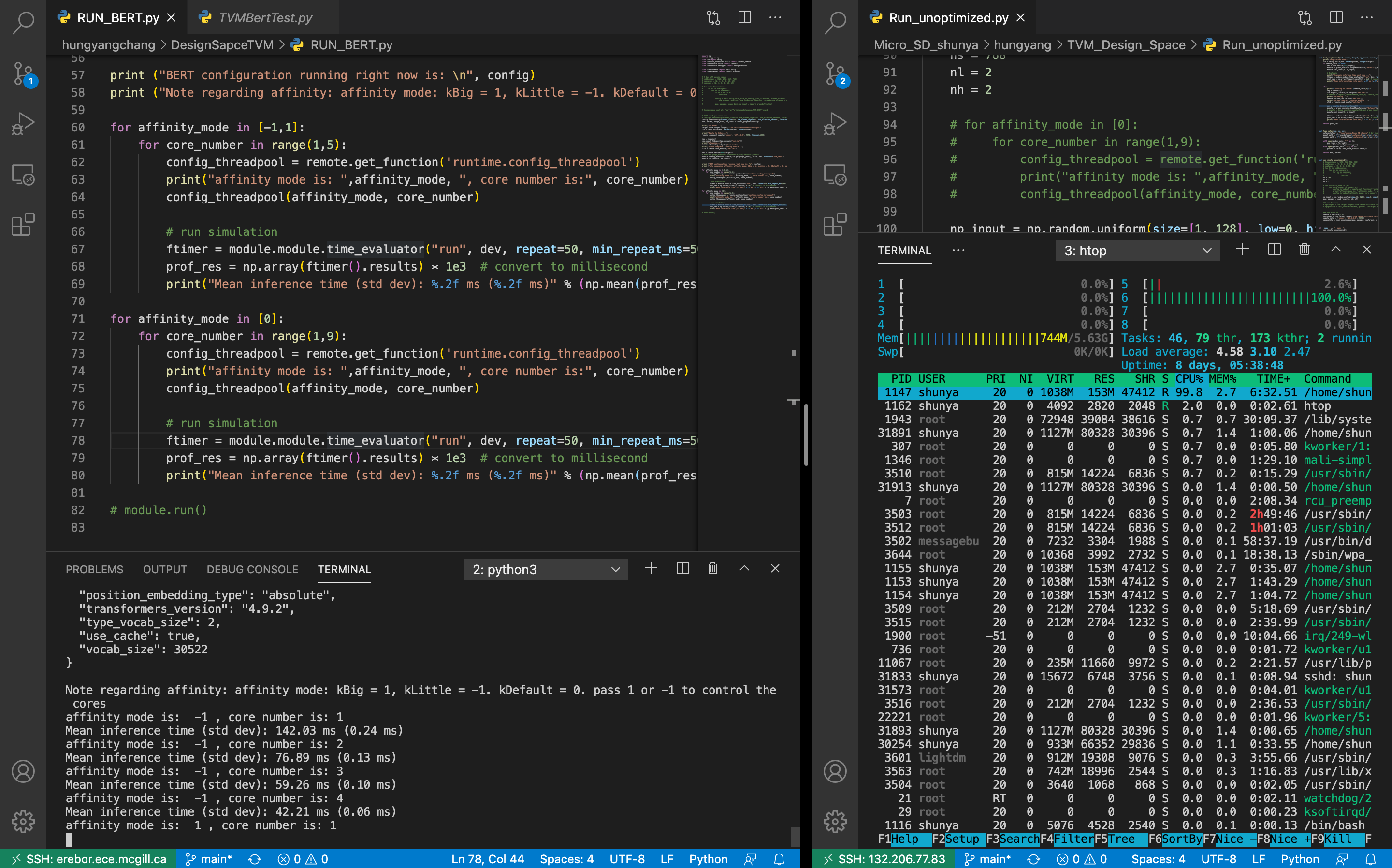
Thanks for your answering, I was able to set the numbers of the thread through remote now. (I use my own desktop and use the remote command to send the network to Hikey970, then I used “htop” to check the corresponding CPU assignment in hikey 970 and all is good)
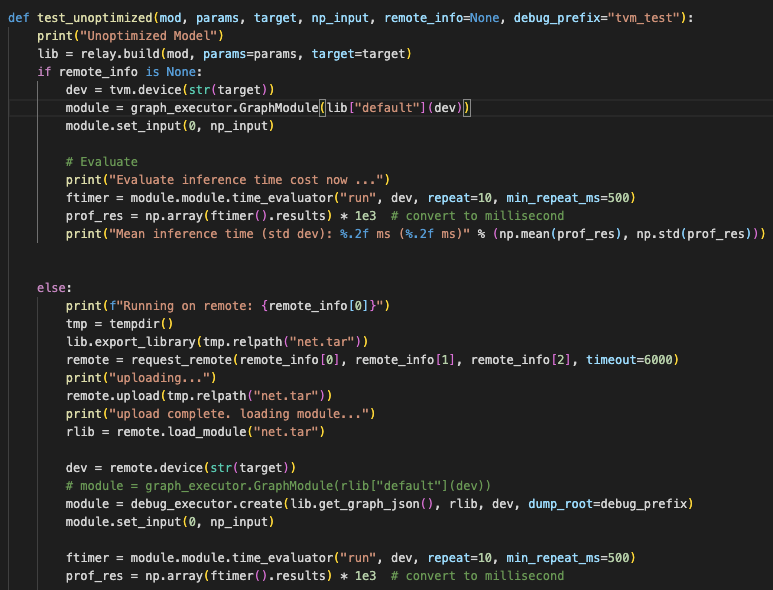
However, I am wondering if it is possible to set the number of cores in Hikey970 locally without using remote. (i.e. running locally with remote_info = None in the following function)
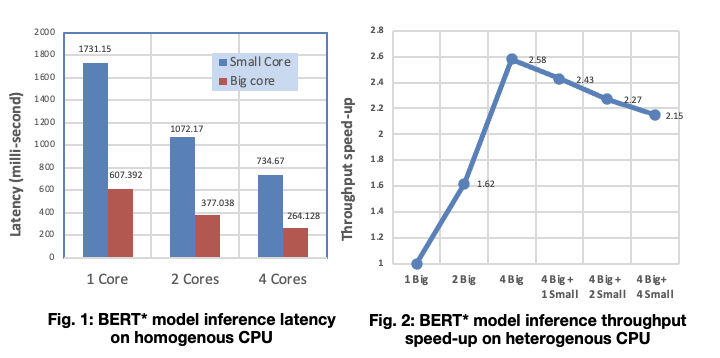
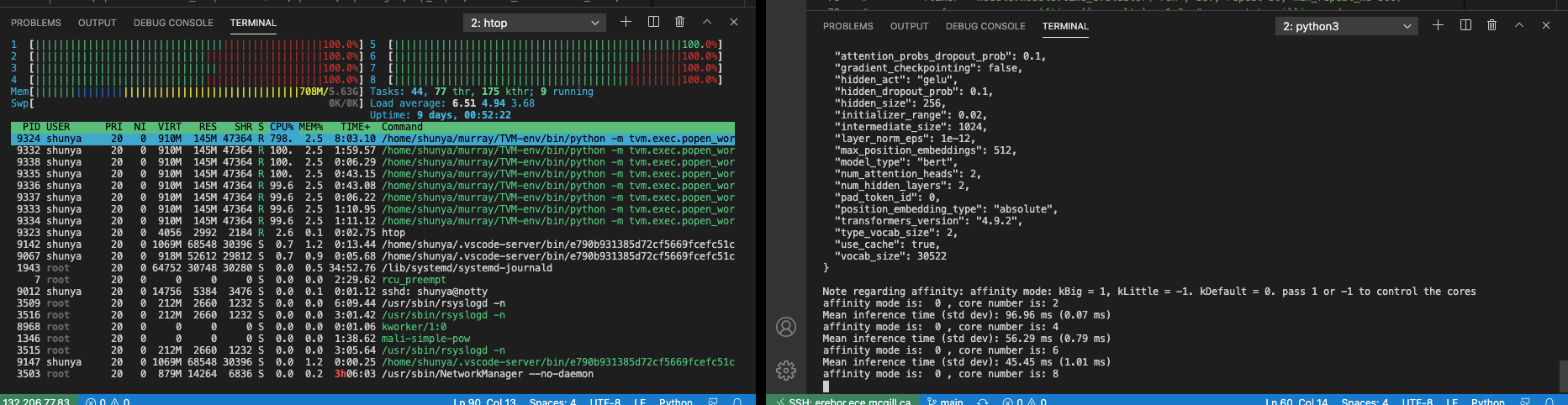
Also, I found the performance is actually getting better when using big and small cores at the same time. During the simulation, I use “htop” to check the number of threads, and
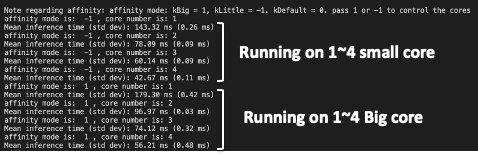
Here are the simulation results with [1/2/3/4 big cores] and [4 big +1/2/3/4 small cores]
No. Because runtime is in the remote and default bahaviour is run all big cores, you should use it to control the cores. When you deploy it in devices in C++ if in production, you could use C++ api in the app to control it.
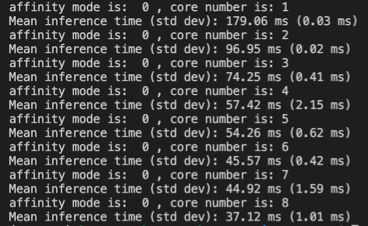
Please make sure you are using 8 cores, because our thread pool will check core numbers. When affinity mode is default (0), if your board only have 4 cores, when you set 5, 6 or what else great than 4, we should only use 4 cores. The inference time is different maybe because of unstable measurement for example other apps using cores or you are running inference too few times. Consider running 200 times. We have time_evaluator function utility to do it.
I am using hikey 970 which contains 8 cores (4 big cores and 4 small cores), so I think I did have 8 cores. Also, I used “htop” to check the number of threads and make sure my setting is correct. For example, on the left-hand side (my own desktop) I am running with remote with only 1 big core, on the left-hand side (hikey 970) receive the command and doing the benchmark, I am using htop to show hikey 970 indeed only using one big core number (core number 6, which is a big core)
I have already using time_evaluator and setting repeat =50 (I think it’s big enough, which is the same setting as what I set when I did inference in the TensorFlow lite), but I still got the following result.
affinity mode is: 1 , core number is: 4
Mean inference time (std dev): 56.44 ms (0.36 ms)
affinity mode is: 0 , core number is: 1
Mean inference time (std dev): 179.23 ms (0.23 ms)
affinity mode is: 0 , core number is: 2
Mean inference time (std dev): 97.08 ms (0.14 ms)
affinity mode is: 0 , core number is: 3
Mean inference time (std dev): 74.11 ms (0.04 ms)
affinity mode is: 0 , core number is: 4
Mean inference time (std dev): 56.69 ms (0.90 ms)
affinity mode is: 0 , core number is: 5
Mean inference time (std dev): 54.50 ms (0.63 ms)
affinity mode is: 0 , core number is: 6
Mean inference time (std dev): 45.72 ms (1.45 ms)
affinity mode is: 0 , core number is: 7
Mean inference time (std dev): 45.23 ms (2.40 ms)
affinity mode is: 0 , core number is: 8
Mean inference time (std dev): 37.28 ms (2.27 ms)
As the result shows, running with 4 big and 4 small outperform than running only with 4 big cores.
Sorry, I am using the following python code to run my simulation and I am not quite familiar with the backend settings with C++. I did go over thread_pool.cc and threading_backend.cc, but I am still wondering is it possible to utilize or call “TVM_REGISTER_GLOBAL(“runtime.config_threadpool”)” or “Configure(AffinityMode mode, int nthreads, bool exclude_worker0)” function in python as we did in the remote setting. (i.e. remote.get_function(‘runtime.config_threadpool’))
Hello @FrozenGene,
Yes, I knew there is “MaxConcurrency()” function in the backend.cc to control the max number of cores we could use.
What I did: export TVM_NUM_THREADS =8 in Hikey 970 since it has 8 cores.
Afterwards, I run with following code:
config_threadpool(0, 8)ftimer = module.module.time_evaluator(“run”, dev, repeat=50, min_repeat_ms=500)
I use htop and indeed the benchmark is using all of 8 cores (CPU utilization ~=800%)