Hi all, This post is a continuing discussion from Use all cores in a big.LITTLE architecture:
I am working on Hiker 970 which contains 4 A73 big cores and 4 A53 small cores. I used “module.module.time_evaluator(“run”, dev, number=1, repeat=repeat)” to benchmark BERT models from huggingface and use config_threadpool to set the number of thread.
However, I found out two weird behaviors as the following figures show:
- running with 4 small (42.57ms) outperforms running with 4 big cores (56.21ms).
- running with 4 big and 4 small at the same time (37.12ms) outperforms running only with either 4 big or 4 small only (42.57ms).
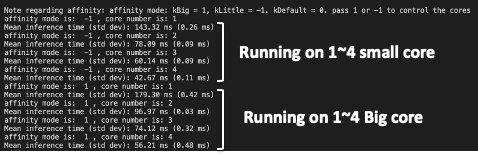
Therefore, I referred to tvm benchmark wiki to see what other networks behave. I got a similar result in sqeueezet and mobilenet: Running with 4 small even outperform running with 4 big cores and running with 4 big and 4 small outperform running only with either 4 big or 4 small only.
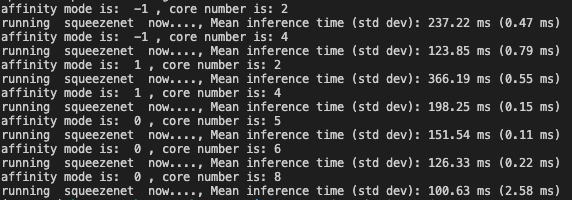
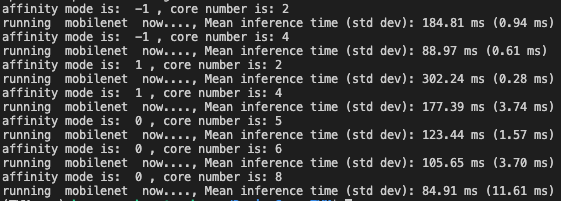
The only exception is benchmarking “simple multilayer perception” whose behavior is more reasonable.
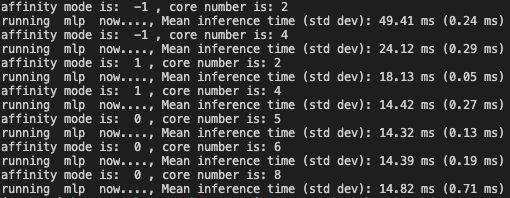
In simple multilayer perception, running with 4 big (14.42ms) outperforms running with 4 small cores (24.12ms). Running with 4 big and 4 small at the same time (14.82ms) barely outperforms running only with either 4 big or 4 small only (14.42ms) due to the communication cost of cores and cores.
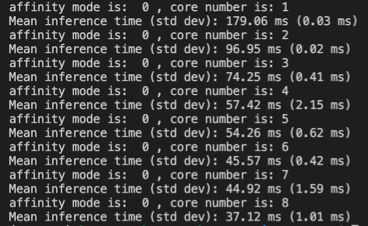
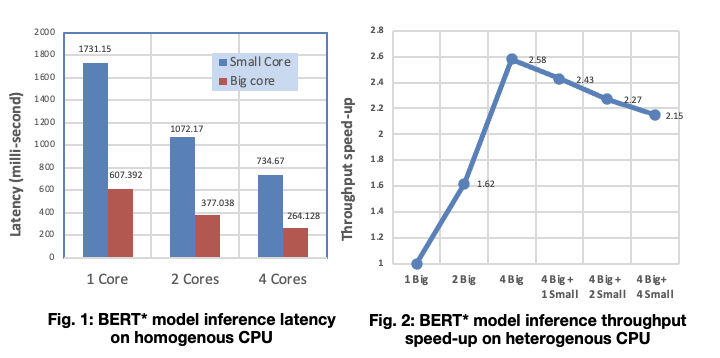
Other info: I have run some simulations on TensorFlow lite benchmark and see the performance degrade when using all cores at the same time. (Fig2)
Does anyone have any thoughts on that? Thanks for your input in advance:)
 Thanks, community.
Thanks, community.