Hi community:
We would like to propose a Pre-RFC to enhance the debugging ability of TVM. This Pre-RFC will describe the details of how do we enhance the current functionality. On the other hand we will mention about what visualization can we get from TVM Explorer, which is another web GUI project based on this RFC.
- Feature Name: TVM Explorer Infrastructure
- Start Date: Sep 1, 2022
- RFC PR: apache/tvm-rfcs#0092
- GitHub Issue: apache/tvm/#10072
- Authors: @chunit , @haowhsu-quic, Zack Chen.
Summary
The goal of this RFC is to extend the capability of tracing source information between different IRs for the debugging uses. Three features get benefit from this change as following:
- Map Layer name from ML frontend IR to Relay IR.
- Record source expressions to the transformed ones during pass optimizations.
- Queue the snapshots of schedule after changes made by primitives
These changes provide users a clear backtrace of an IR in CLI text format. Furthermore, paired with our on-going project
TVM Explorer, a colorful and convenient GUI can improve the user experience even better. We will demonstrate the use
cases of TVM Explorer with examples in the following sections.
Motivation
We aim to ease debugging process by enhancing and creating the features to carry source information. TVM performs
numbers of transformations to optimize and deploy a ML frontend IR to a targeted device. However, currently modules
which record source information between IRs are not fully used. It makes users hard to trace the source of a transformed
IR. Usually an investigation to source code should be done so as to understand details of a transformation.
We provide the following enhancements to mitigate users’ effort by recording source information between IR and schedules
of op implementation:
Frontend span filler: Fill the layer name to Relay IR during the frontend conversion.Pass source information builder: ConstructSequentialSpanfromSpanandSIBuilderto handle source information for both Relay IR and TIR.Schedule/Stage visualization enhancement: Record and propagate op’s schedule snapshots with primitives applied in regular build flow.
After these modifications, user can obtain the source information simply by a glance or via debugger.
Finally, inspired by Compiler Explorer, we build a web-GUI, TVM Explorer
for TVM. Based on the infrastructures above, TVM Explorer provides a batter user experience when comparing IRs or
analyzing schedules (the code base of TVM Explorer is maintained in another git repository and not included in this
RFC).
TVM Explorer
Guide-level explanation
TVM infrastructures
Frontend span filler
Based on the ExprMutator, we implement set_span to recursively fill the source information to Relay IR during the op
conversion. We could obtain the Relay IR with span even in an one-to-many conversion. Take Pack op from TF for example,
it inserts multiple expand_dims during conversion:
# implement of pack TF conversion
def _pack():
def _impl(inputs, attr, params, mod):
axis = int(attr["axis"])
inputs_reshaped = [_op.expand_dims(i, axis=axis, num_newaxis=1) for i in inputs]
return _op.concatenate(inputs_reshaped, axis)
return _impl
# After convert an op from frontend
ret = self.convert_map[op_code_str](op)
ret = set_span(ret, frontend_layer_name)
'''
The result after set_span of a pack op conversion
def @main (%input: Tensor[(?, ?, 3, 1), float32]) {
%0 = shape_of(%input, dtype="int32") /* Shape */;
%1 = strided_slice(%0, …) /* strided_slice */;
%2 = squeeze(%1) /* strided_slice */;
}
======>
def @main (%input: Tensor[(?, ?, 3, 1), float32]) {
%0 = shape_of(%input, dtype="int32") /* Shape */;
%1 = strided_slice(%0, …) /* strided_slice */;
%2 = squeeze(%1) /* strided_slice */;
%3 = expand_dims(%2, axis=0) /* stack */;
%4 = expand_dims(3, axis=0) /* stack */;
%5 = expand_dims(3, axis=0) /* stack */;
%6 = (%3, %4, %5) /* stack */;
%7 = concatenate(%6) /* stack */;
}
'''
Pass source information builder
To manage the span propagation in passes, we extend SequentialSpan from Span, and create a new class SIBuilder.
First, we construct a container class, SequentialSpan to carry a set of source spans in its member variable for those
many-to-n (n>=1) conversion, which is common in transformations between passes:
// C++
SequentialSpan new_span{expr_1->span, expr_2->span}
# Python
relay.SequentialSpan([expr_1, expr_2])
Take the IfNode condition in FoldConstant pass for example. When the condition is a constant, FoldConstant extracts
the expression of the triggered path as the result. We create a SequentialSpan to keep the existent span from the
selected branch and the span from discarded If expression.
Expr VisitExpr_(const IfNode* if_node) final {
If new_if = Downcast<If>(ExprMutator::VisitExpr_(if_node));
if (const auto* const_node = AsIgnoringOnDevice<ConstantNode>(new_if->cond)) {
Expr ret;
if (reinterpret_cast<uint8_t*>(const_node->data->data)[0]) {
ret = new_if->true_branch;
} else {
ret = new_if->false_branch;
}
ret->span = SequentialSpan({ret->span, new_if->span});
return ret;
}
return std::move(new_if);
}
On the other hand, SIBuilder aims to ease the developers’ workload when filling span in the pass transformation.
Based on our experiences when filling span to existing passes, we provide two functionalities in SIBuilder. First,
RecursivelyFillSpan provides an easy way to automatically fill up source span to those conversions which result
in multiple expressions. Given a source span, RecursivelyFillSpan applies DFS traversal from “start_expression”
and fill the source span until it encounters any of those given inputs.
SIBuilder si_builder(source_span);
sibuilder->RecursivelyFillSpan(start_expression, {inputs_of_the_first_new_generated_expr});
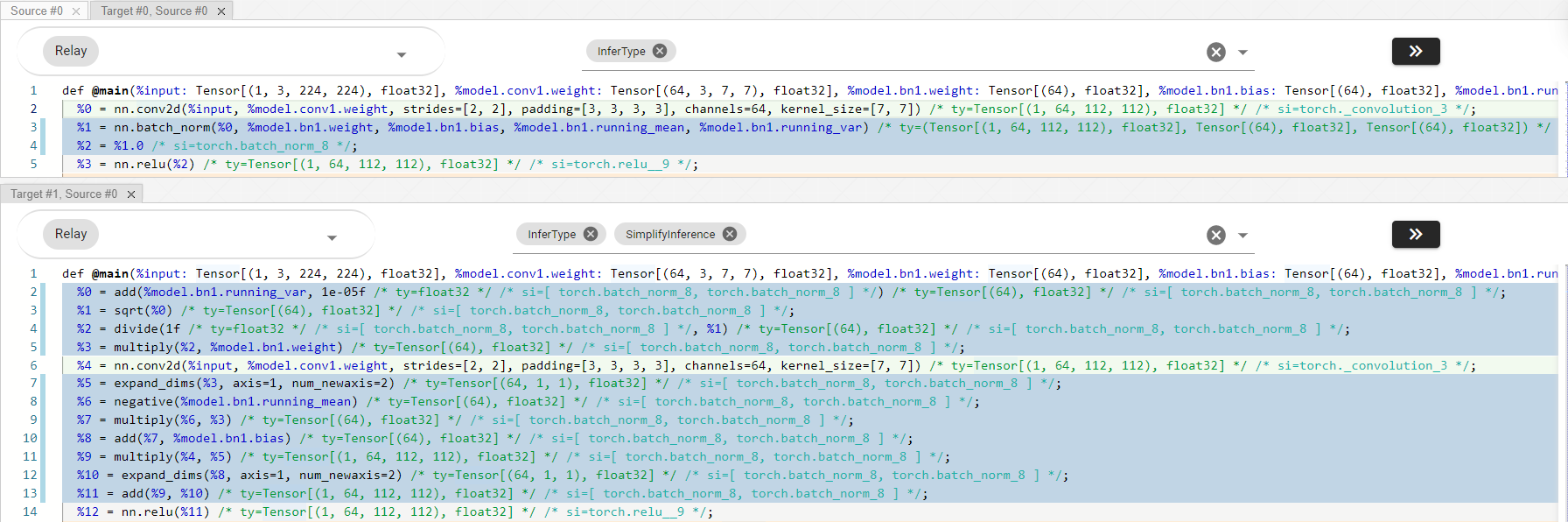
An use case of RecursivelyFillSpan is SimplifyInference. This pass simplifies certain operators during inference.
Take BatchNorm for example, SimplifyInference unpacks the Call of BatchNorm and its TupleGetItem indexed at 0 to
several simplified expressions. In this case we can invoke RecursivelyFillSpan to fill span to those new generated
expressions once for all.
Expr BatchNormToInferUnpack(const Attrs attrs, Expr data, Expr gamma, Expr beta, Expr moving_mean,
Expr moving_var, Type tdata, Span span) {
auto ttype = tdata.as<TensorTypeNode>();
ICHECK(ttype);
const auto param = attrs.as<BatchNormAttrs>();
Expr epsilon = MakeConstantScalar(ttype->dtype, static_cast<float>(param->epsilon));
Expr var_add_eps = Add(moving_var, epsilon);
Expr sqrt_var = Sqrt(var_add_eps);
Expr scale = Divide(MakeConstantScalar(ttype->dtype, 1.0f), sqrt_var);
//...
Expr out = Multiply(data, scale);
out = Add(out, shift);
SIBuilder si_builder(span);
si_builder.RecursivelyFillSpan(/* entry */ out,
/* inputs */ {data, gamma, beta, moving_mean, moving_var});
return out;
}
Second, SIBuilder provides a constructor to collect a continuous sequence of source spans. Starts from entry, it puts
the span of an Expr to its array member variable, and continues the traversal until hits the inputs. Finally, invoke
CreateSpan from the created SIBuilder instance to obtain the source span.
SIBuilder si_builder(entry_expr, {inputs});
new_span = si_builder.CreateSpan();
This constructor works properly in SimplifyExpr pass. A pattern of SimplifyExpr is SimplifyReshape, one of its
patterns is an expression followed by two consecutive rehsapes or contrib_reverse_reshapes. In this case we can use the
constructor of SIBuilder above to obtain all source spans of the matched pattern.
class SimplifyReshape : public DFPatternRewrite {
public:
SimplifyReshape() {
x_ = IsWildcard();
auto reshape1 = IsOp("reshape") || IsOp("contrib_reverse_reshape");
auto reshape2 = IsOp("reshape") || IsOp("contrib_reverse_reshape");
pattern_ = reshape1({reshape2({x_})});
}
Expr Callback(const Expr& pre, const Expr& post,
const Map<DFPattern, Array<Expr>>& node_map) const override {
//...
if (const_shape) {
auto x = node_map[x_][0];
auto ret = MakeReshape(x, newshape);
SIBuilder si_builder(/* entry */ node_map[pattern_][0], /* inputs */ {x});
ret->span = si_builder.CreateSpan();
return ret;
//...
};
Based on the classes above, we have filled span to all relay passes in the build flow.
Schedule/Stage Visualization Enhancement
Tensor Expressions are scheduled with primitives, it becomes complicated quickly with the increasing number of applied
primitives. Although TEDD(Tensor Expression Debug Display) already provides a mechanism to visualize different kinds
of schedule diagrams(Schedule Tree, Itervar Relationship and Dataflow). The resulting information still seems hard to
recognize the effect of each applied primitive.
We propose a change to record the snapshot of schedule after each new primitive is applied by introducing some
modifications to the interface of Schedule/Stage class. In order to inspect the schedules created inside TVM build flow,
new APIs will also be added.
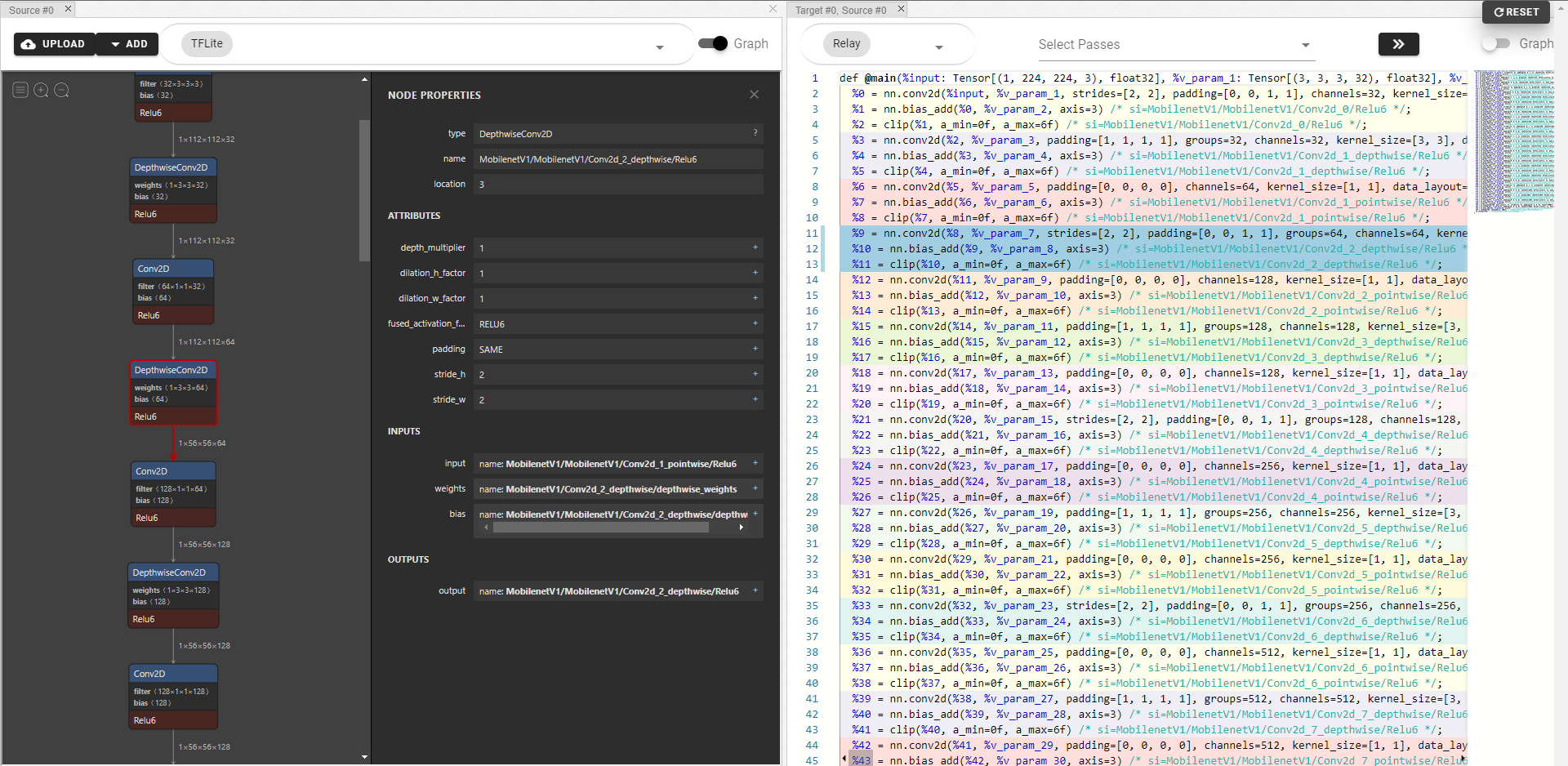
By doing so, we can leverage TEDD to display a sequential schedule diagrams, the followings are the snippet of driving
code and the corresponding result:
# load TFLite model
tflite_model_buf = open('mobilenet.tflite', "rb").read()
model = tflite.Model.GetRootAsModel(tflite_model_buf, 0)
input_shape = {'input': (1, 224, 224, 3)}
mod, params = relay.frontend.from_tflite(model, input_shape)
# invoke build process
with tvm.transform.PassContext(opt_level=3):
lib = relay.build(mod, 'llvm', params=params)
# (new API) get schedule from 17th node in TVM graph
sch = lib.build_module.get_node_schedule(17)
# (new API) get schedule record (snapshots of schedule)
schs = sch.schedule_record
# the second to last schedule
ori_dot = tedd.viz_schedule_tree(schs[-2].normalize(), dot_file_path="ori.dot")
# the last schedule with all the optimization strategies
cmp_dot = tedd.viz_schedule_tree(schs[-1].normalize(), dot_file_path="cmp.dot")
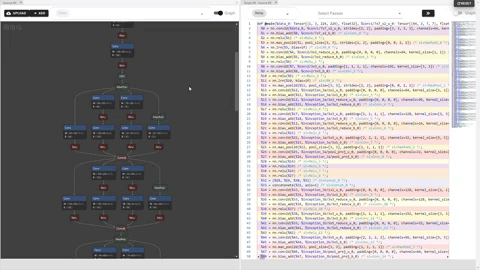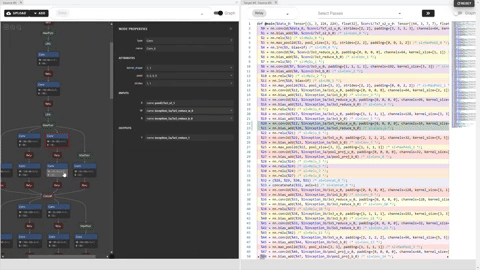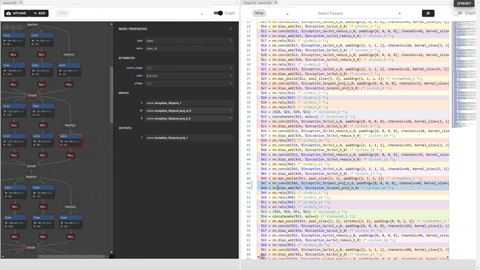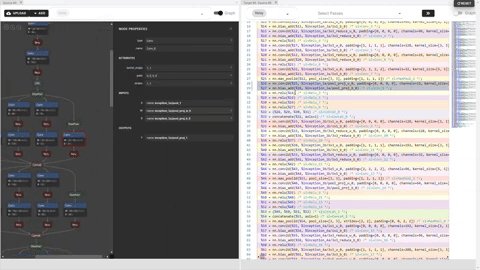
Ori.png
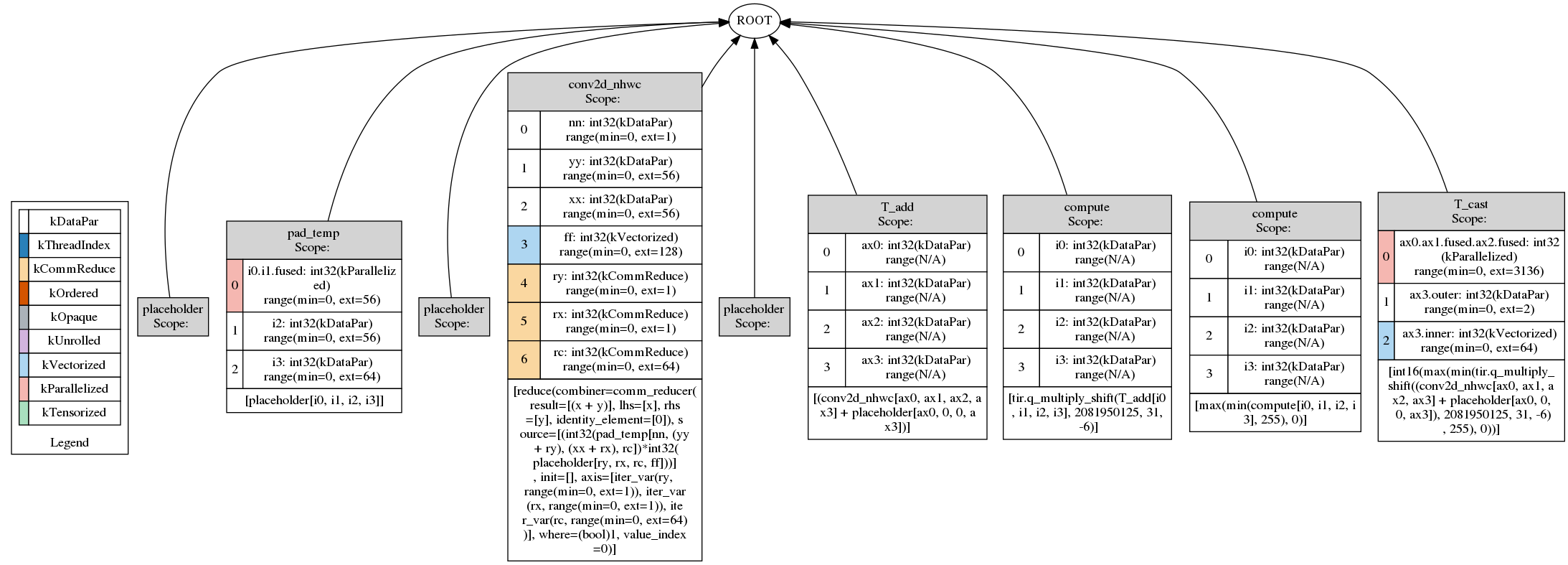
We could see the effect of applied primitive “compute_at”, which moved the computation scope of “conv2d” inside
the outter loop of “cast” stage:
Cmp.png
TVM Explorer preview
Inspired by Compiler Explorer, TVM Explorer is our on-going project which is a web-GUI to
investigate TVM behaviors. Based on the infrastructures above, TVM Explorer achieves the following goals:
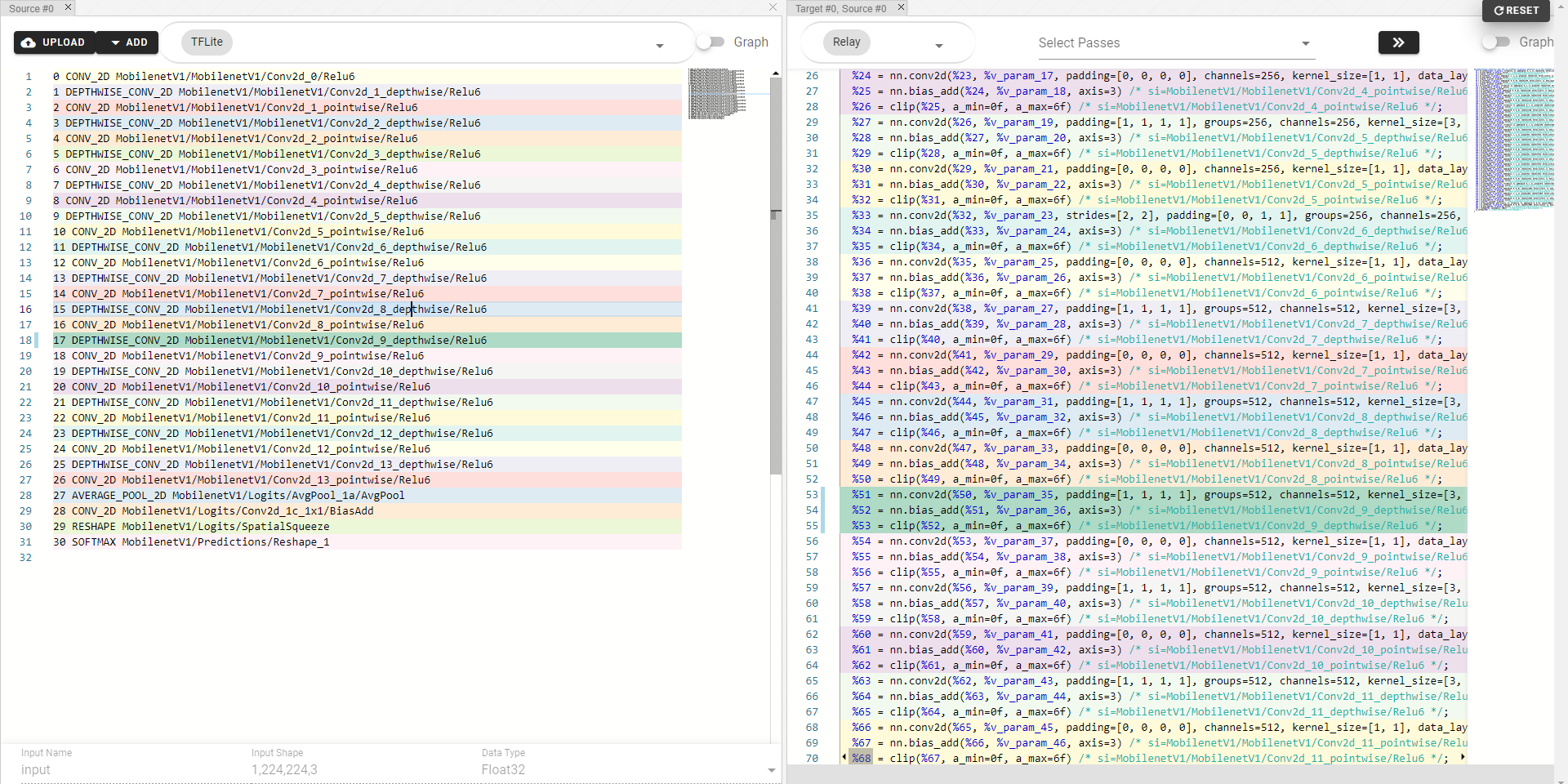
- Frontend span filling: Link and interact converted Relay IR with Frontend IR.
Frontend mapping based on Span (Netron)
Frontend mapping based on Span (Pretty-print)
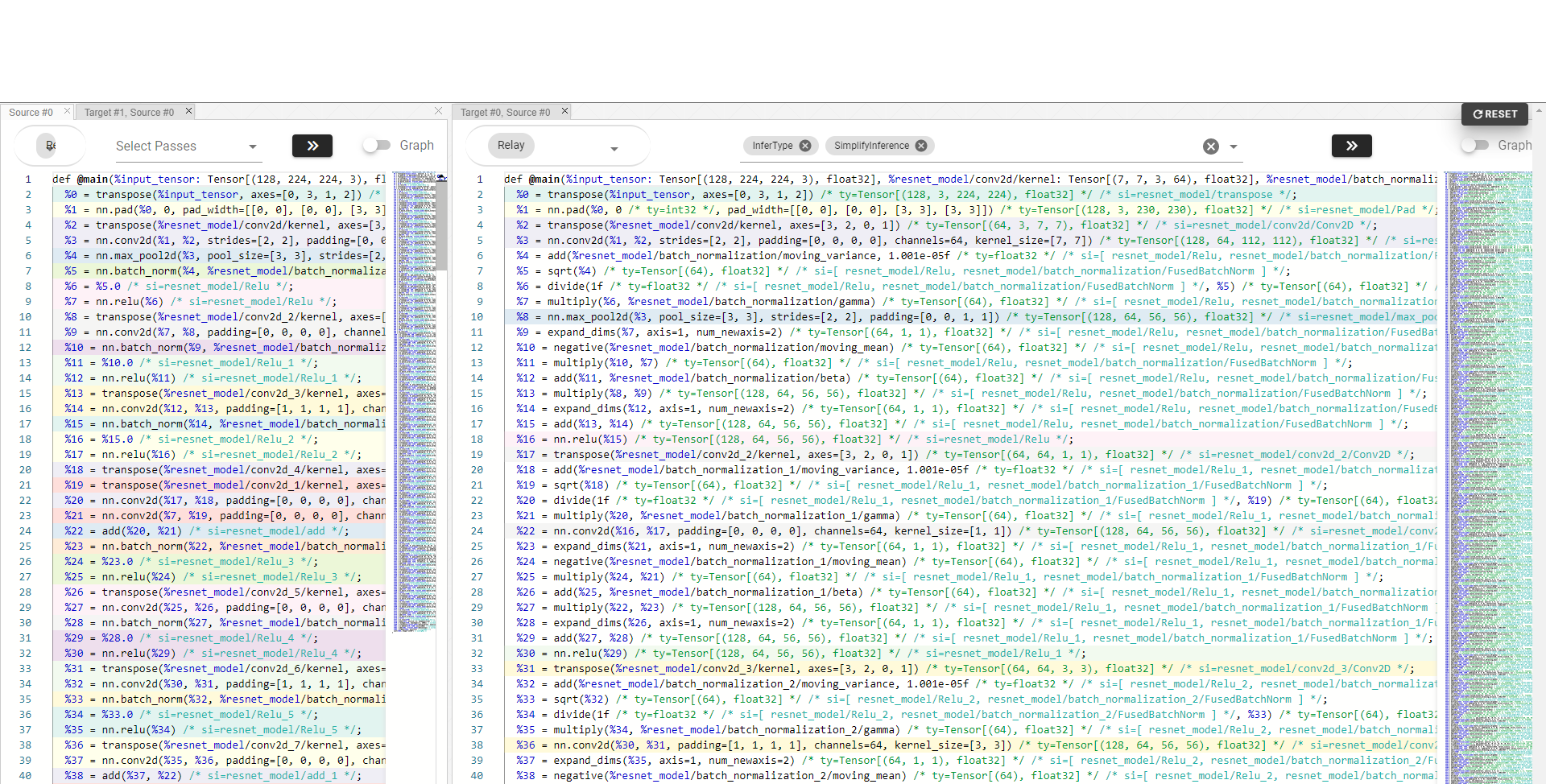
- Source information builder: Find the source expressions between transformations of passes
Pass conversion (Unpack batchnorm)
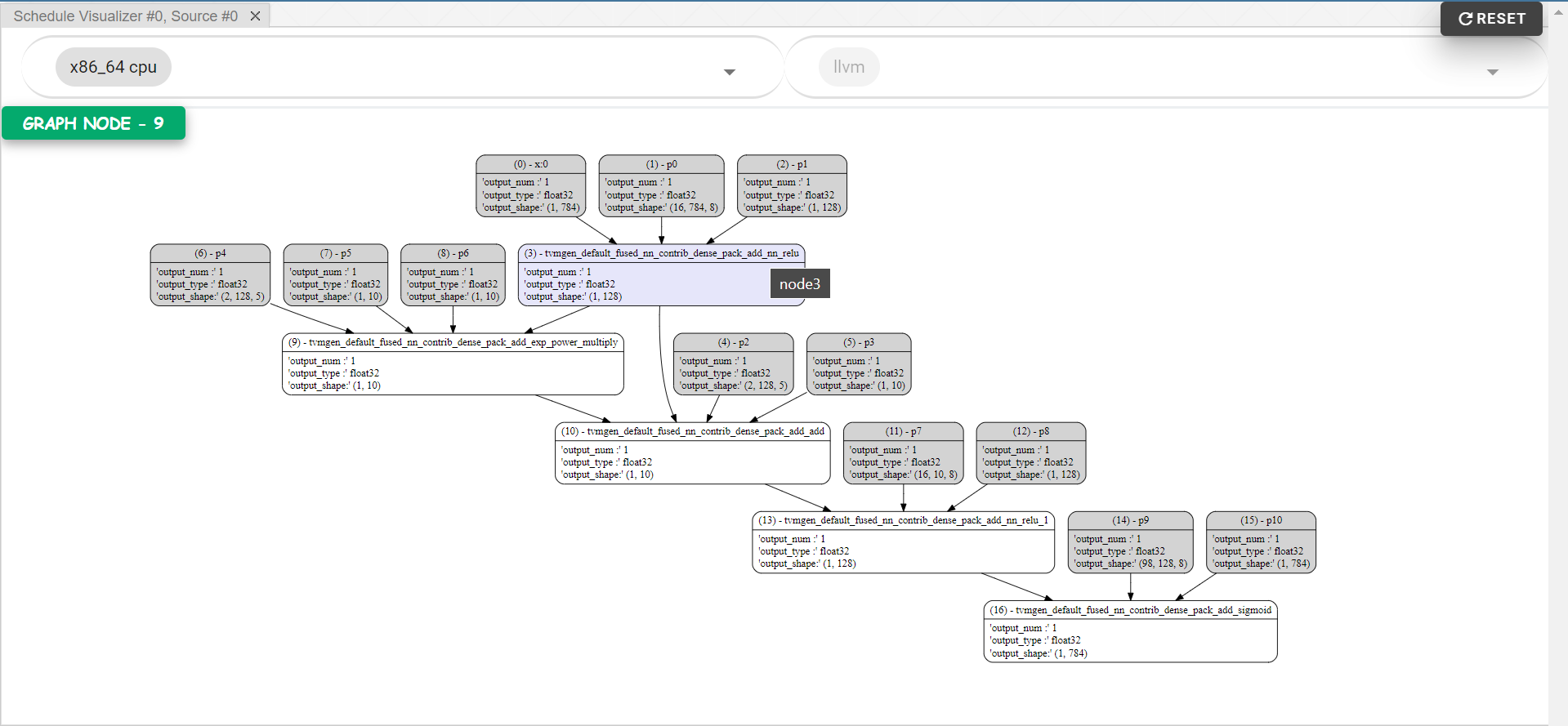
- Schedule/Stage visualization enhancement
TVM Explorerprovides mechanism to visualize the computation graph generated fromGraphExecutor. With the proposed changes, the data structure ofSchedulewill be kept inside each graph node where users are able to visualize the implementation details:
Computation graph.png
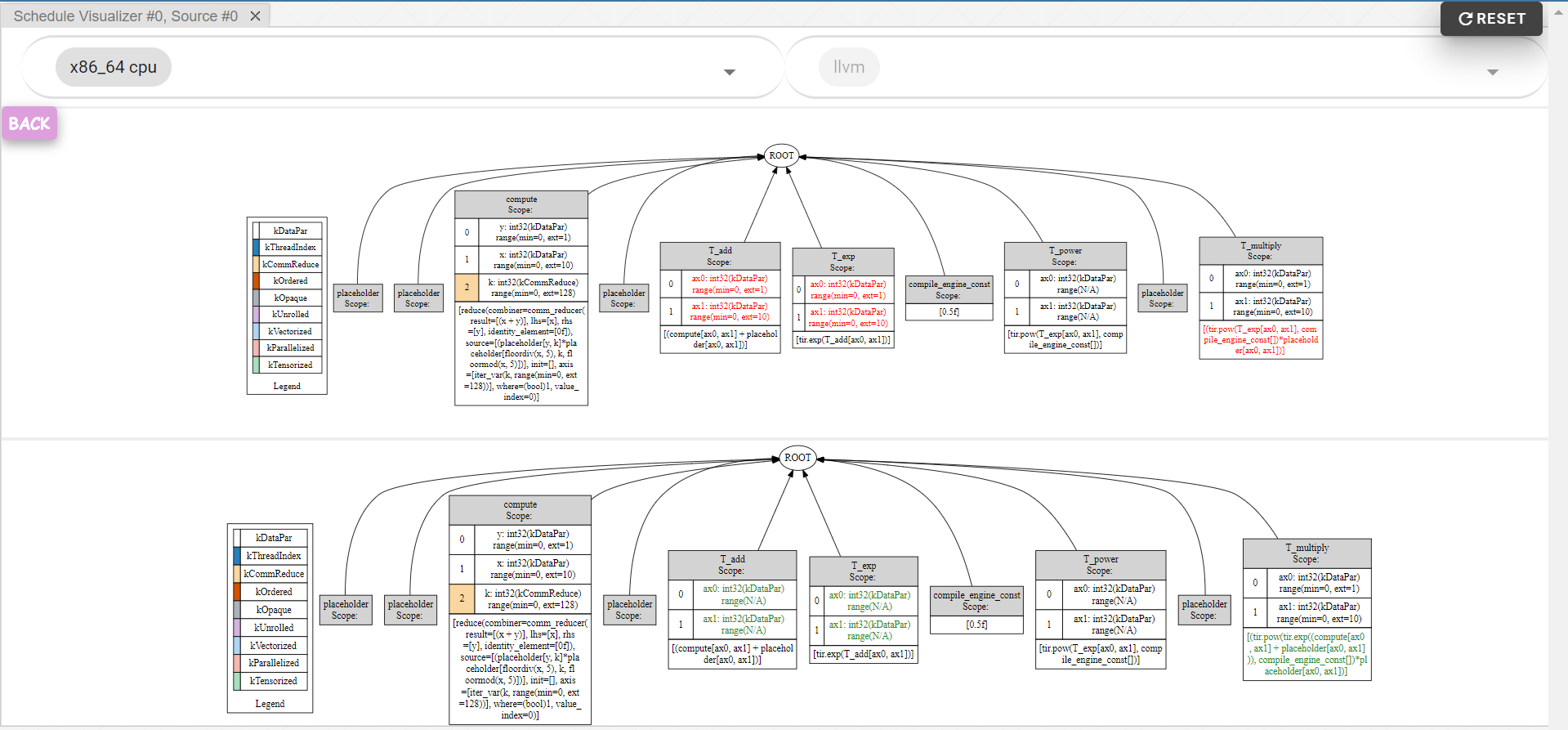
Click into the graph nodes to see further comparisons, like highlighting the difference between two schedules
after applying a primitive:
Schedule comparison.png
Reference-level explanation
Frontend span filling
This feature had been introduced previously in PR-9723, but was reverted because the unexpected duplicated expressions problem in PR-10072. We fix the issue in PR-10072 and propose a modified version with the following differences:
- Fix the problem of duplicated expressions in PyTorch conversion:
Previously we did not invokeset_spanin each required condition, and did not handle tuple/list type properly during PyTorch conversion. It resulted in duplicated expressions were generated. After the investigation, we insertset_spanto each required place to avoid duplication. - Remove the suffix in source information:
Because in the stage of pass transformation, suffix seems to mess up the source information of an expression. We remove the _PART_N for concision. - Redesign PyTorch source information:
Since a representative PyTorch source information might not exist, we introduce a method to reconstruct a new one. - Use environment variable
TVM_SPANFILLINGto disable/enable span filling:
If span filling is not required, set the environment variable withexport TVM_SPANFILLING=0to disable the procedure.
def set_span(sym, span):
"""Set up the sapn of relay expression(s) while converting OP"""
class SpanFiller(ExprMutator):
"""SpanFiller"""
return SpanFiller(span).fill(sym) if _should_fill_span() else sym
The following is the details of set_span. The constructor now accepts both string and span format as its source
information. The function fill accepts types in the whitelist to prevent unexpected symbol. The function visit
stop traversal deeper once the flow hits an expression with span. In the dispatched visit function like visit_call,
SpanFiller reconstructs and returns a new expression with the given span.
class SpanFiller(ExprMutator):
"""SpanFiller"""
def __init__(self, span):
ExprMutator.__init__(self)
if isinstance(span, tvm.relay.Span):
self._span = span
elif isinstance(span, str):
self._span = tvm.relay.Span(tvm.relay.SourceName(span), 0, 0, 0, 0)
else:
assert False, f"unsupported span type: {type(span)}"
def visit(self, expr):
if hasattr(expr, "span") and expr.span:
return expr
def visit_call(self, call):
new_args = [self.visit(arg) for arg in call.args]
return _expr.Call(call.op, new_args, call.attrs, call.type_args, self._span)
#...
def fill(self, sym):
if isinstance(sym, _expr.TupleWrapper):
return _expr.TupleWrapper(self.visit(sym.tuple_value), sym.size)
elif isinstance(sym, _expr.RelayExpr):
return self.visit(sym)
elif isinstance(sym, list):
assert all(
isinstance(expr, _expr.TupleGetItem) for expr in sym
), f"unexpected relay expressions in {sym}"
return [self.visit(expr) for expr in sym]
elif isinstance(sym, tuple):
assert all(
isinstance(expr, _expr.RelayExpr) for expr in sym
), f"unexpected relay expressions in {sym}"
return tuple(self.visit(expr) for expr in sym)
assert False, f"unsupported type {type(sym)}"
Pass source information builder
-
SequentialSpan:
Inherits fromSpan,SequentialSpancan accept and put a sequence ofSpanto itstvm::Array. For those many-to-n (n>=1) transformations,SequentialSpanis a good container to carry their source. When comparing the equalness between twoSequentialSpan, simply fall back to the equalness of each span to obtain the result iteratively.UML of SequentialSpan
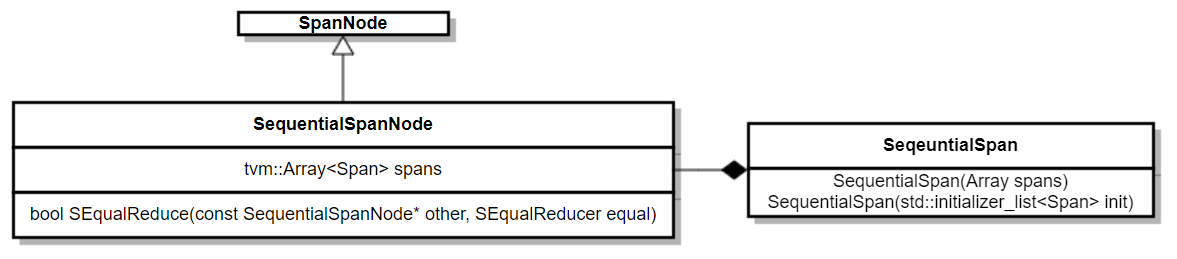
class SequentialSpanNode : public SpanNode {
public:
/*! \brief A list of spans that used to compose a sequential span. */
tvm::Array<Span> spans;
static constexpr const char* _type_key = "SequentialSpan";
bool SEqualReduce(const SequentialSpanNode* other, SEqualReducer equal) const;
TVM_DECLARE_FINAL_OBJECT_INFO(SequentialSpanNode, SpanNode);
};
class SequentialSpan : public Span {
public:
TVM_DLL SequentialSpan(Array<Span> spans);
TVM_DLL SequentialSpan(std::initializer_list<Span> init);
};
-
SIBuilder:
SIBuilderprovides two functionalities for both Relay/TIR pass transformations. One is recursively filling spans to those new generated expressions without span. Another is collecting source spans from a contiguous sequence of expressions. The following UML demonstrates the overview ofSIBuilder:UML of SIBuilder
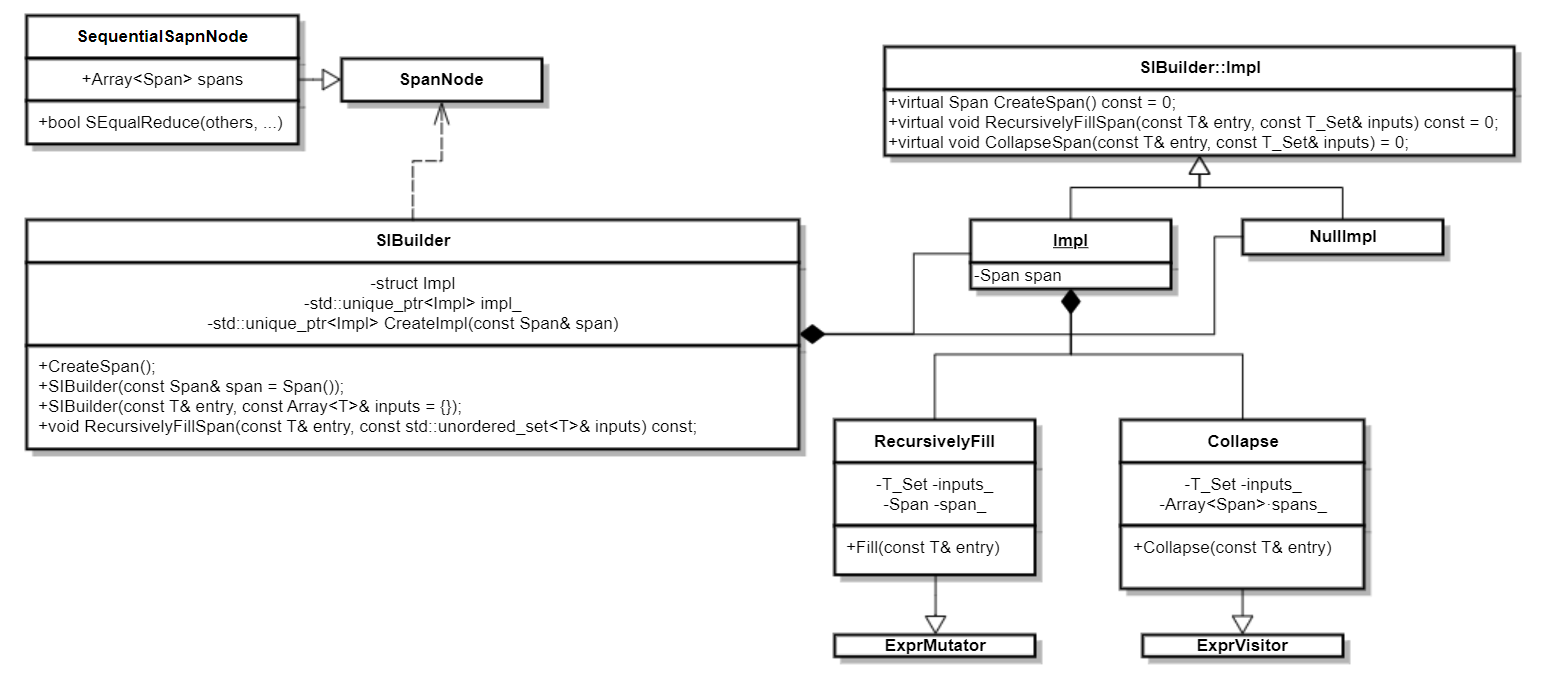
class SIBuilder {
public:
explicit SIBuilder(const Span& span = Span());
/*!
* \brief Create SIBuilder via a subgraph,
* will construct span based on the exprs falls in the subgraph
*
* \param entry Entry expr for subgraph
* \param inputs End exprs for subgraph
*/
template <typename T, typename = std::enable_if_t<std::is_base_of<BaseExpr, T>::value>>
explicit SIBuilder(const T& entry, const tvm::Array<T>& inputs = {});
explicit SIBuilder(const tir::Stmt& entry, const tvm::Array<PrimExpr>& inputs = {});
explicit SIBuilder(const tir::Stmt& entry, const tvm::Array<tir::Stmt>& inputs = {});
~SIBuilder();
SIBuilder(const SIBuilder&) = delete;
SIBuilder& operator=(const SIBuilder&) = delete;
/*!
* \brief create new source info based on span_buffer_.
*
* \return The span.
*/
Span CreateSpan() const;
/*!
* \brief Recursively fill subgraphs exprs' span
*
* \param entry Entry expr for subgraph
* \param inputs End exprs for subgraph
*/
template <typename T, typename = std::enable_if_t<std::is_base_of<BaseExpr, T>::value>>
void RecursivelyFillSpan(const T& entry, const std::unordered_set<T, ObjectPtrHash, ObjectPtrEqual>& inputs) const;
void RecursivelyFillSpan(const tir::Stmt& entry, const std::unordered_set<PrimExpr, ObjectPtrHash, ObjectPtrEqual>& inputs) const;
void RecursivelyFillSpan(const tir::Stmt& entry, const std::unordered_set<tir::Stmt, ObjectPtrHash, ObjectPtrEqual>& inputs) const;
private:
struct Impl;
std::unique_ptr<Impl> impl_;
std::unique_ptr<Impl> CreateImpl(const Span& span);
};
Start from the RecursivelyFillSpan we will describe how to fill a given span to those new generated expressions.
Take the RelayRecursivelyFill for Relay type as an example, it inherits from ExprMutator to traverse the given
expressions. If the visited expression is one of the inputs, it stops the traversal. Otherwise RecursivelyFillSpan
dispatches to the corresponding type, sets up the span, and traverses deeper.
class RelayRecursivelyFill : public relay::ExprMutator {
public:
RelayRecursivelyFill(const Span& span, const RelayExprSet& inputs = {})
: span_(span), inputs_(inputs) {}
void Fill(const relay::Expr& entry);
relay::Expr VisitExpr(const relay::Expr& expr) final;
relay::Expr VisitExpr_(const relay::CallNode* call_node) final;
// other types...
private:
const Span& span_;
const RelayExprSet& inputs_;
};
relay::Expr RelayRecursivelyFill::VisitExpr(const relay::Expr& expr) {
//...
if (inputs_.find(expr) != inputs_.end()) {
return expr;
}
//...
}
relay::Expr RelayRecursivelyFill::VisitExpr_(const relay::CallNode* call_node) {
call_node->span = span_;
return relay::ExprMutator::VisitExpr_(call_node);
}
On the other hand, the constructor of SIBuilder accepts an entry and a set of inputs to collect all of the source
information. The core functionality for Relay is implemented by the class RelayCollapse, which inherits from ExprVisitor.
Visitor function Collapse acts in a similar way to RecursivelyFill, it starts from the entry, put the span of an
expression to its array member variable, and continues the traversal until hits the inputs. The collected spans can be
produced by invoking the CreateSpan function from the SIBuilder instance.
class RelayCollapse : public relay::ExprVisitor {
public:
RelayCollapse(const RelayExprSet& inputs = {}) : inputs_(inputs) {}
Span Collapse(const relay::Expr& entry);
void VisitExpr(const relay::Expr& expr) final;
private:
tvm::Array<Span> spans_;
const RelayExprSet& inputs_;
};
void RelayCollapse::VisitExpr(const relay::Expr& expr) {
// ...
if (expr->span.defined()) {
spans_.push_back(expr->span);
}
if (inputs_.find(expr) != inputs_.end()) {
visit_counter_.emplace(expr.get(), 1);
return;
}
// ...
}
Span RelayCollapse::Collapse(const relay::Expr& entry) {
VisitExpr(entry);
return SequentialSpan(spans_);
}
Finally, SIbuilder can be disabled by the setting of ir.enable_si_builder in the config of PassContext:
TVM_REGISTER_PASS_CONFIG_OPTION("ir.enable_si_builder", Bool);
Schedule/Stage visualization enhancement
-
Schedule Record:
To inspect the series ofScheduletransformations, new member variables are introduced to store the objects.// ${TVM}/include/tvm/te/schedule.h class ScheduleNode : public Object { public: ... /*! * \brief list of all schedules during primitives applied to stages. */ Array<Schedule> schedule_record; /*! * \brief Flag to keep schedule record or not. */ bool keep_schedule_record; ... };For every
Stageinside aSchedule, it needs to know what currentScheduleis and appends the snapshot ofScheduleafter a primitive applied.// ${TVM}/include/tvm/te/schedule.h class Stage : public ObjectRef { public: ... explicit Stage(Operation op, Schedule& sch); ... /*! * \brief Not functional currently. */ TVM_DLL void EnterWithScope(); /*! * \brief Store current schedule after primitive being applied. */ TVM_DLL void ExitWithScope(); ... };Semantic “With” is used here:
// ${TVM}/src/te/schedule/schedule_lang.cc void Schedule::EnterWithScope() {} void Schedule::ExitWithScope() { ScheduleNode* sch_node = operator->(); if (sch_node->keep_schedule_record) { sch_node->schedule_record.push_back(copy()); } }All primitives could leverage the mechanism above to record the status of
Schedule, take “parallel” primitive as an example:Stage& Stage::parallel(IterVar var) { // NOLINT(*) + With<Schedule> sch_scope(operator->()->attach_sch); SetAttrIterType(operator->(), var, kParallelized); return *this; }The effect can be explained in the following snippet:
def schedule_record_with_gemm(): M, K, N = 1024, 1024, 1024 k = te.reduce_axis((0, K), "k") A = te.placeholder((M, K), name="A") B = te.placeholder((K, N), name="B") C = te.compute((M, N), lambda m, n: te.sum(A[m, k] * B[k, n], axis=k), name="C") s = te.create_schedule(C.op) # currently there are no other applied primitives # size of schedule record is expected to be 1 (vanilla schedule) assert len(s.schedule_record) == 1 # let's apply sequential optimization primitives block_size, factor = 32, 8 # tile -> split + split + reorder mo, no, mi, ni = s[C].tile(C.op.axis[0], C.op.axis[1], block_size, block_size) ko, ki = s[C].split(k, factor=factor) s[C].reorder(mo, ko, no, mi, ki, ni) s[C].vectorize(ni) s[C].parallel(mo) # the primitives inside schedule record are (primitive type and its store order): # vanilla(1), split(2), split(3), reorder(4), split(5), reorder(6), vectorize(7), parallel(8) assert len(s.schedule_record) == 8 -
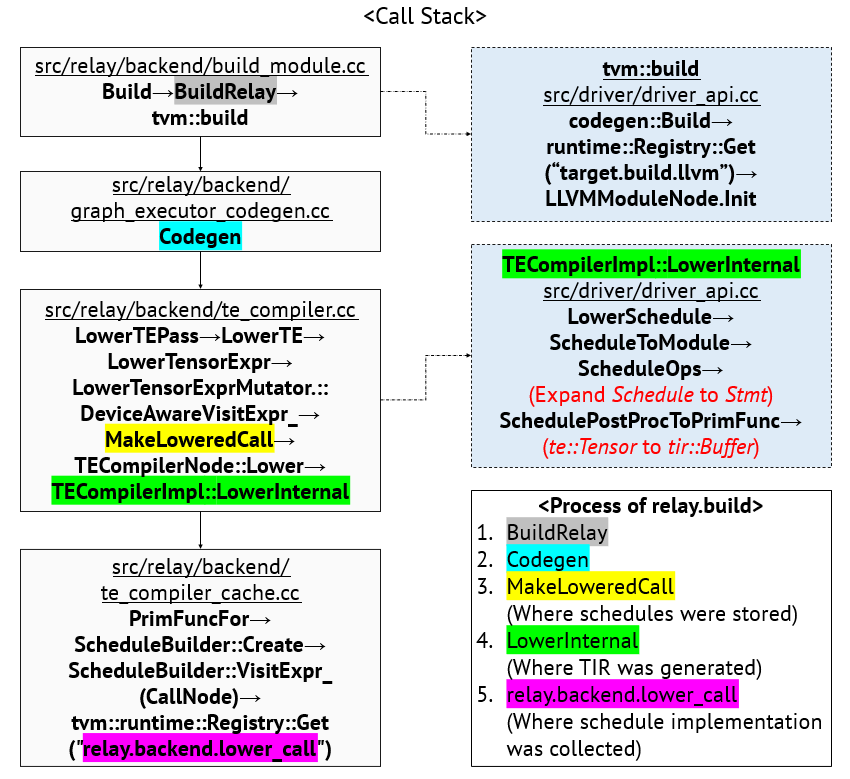
Schedule Propagation:
By investigating the TVM build flow (Relay to a target executable), theScheduleinstance will be stored in the attribute ofCallNodeinsideMakeLoweredCalland retrieved inGraphExecutorCodegenprocess (i.e. schedules will finally be kept in corresponding graph nodes)Callstack of build flow.png
Finally, a series of APIs will be created accordingly for user to access the
Scheduleinstance from Relay build module.
Drawbacks
- Process extra debug information would cause longer compilation time:
- The cost of span filling when converting deep learning model to Relay expression.
- The cost of handling span propagation when applying passes to IR.
- Store extra debug information would cause larger memory consumption in compile time:
- The cost of keeping string information coming from source name of deep learning model.
- The cost of saving snapshots of schedule when primitives applied.
- Currently only the
source_namemember inside Span is used to achieve source mapping mechanism, how to leverage other members likelineorcol? - Engage more unit tests to validate the proposed changes.
The collection of extra debug information can be controlled by environment variable to minimized the effect on performance.
Rationale and alternatives
- The proposed changes are based on existent features, we hope these enhancements could make TVM more comprehensive:
- Source mapping mechanisms to help user quickly identify the relationship of different IR.
- Leverage existent tool like
TEDDto visualize the effect of every schedule primitive.
Prior art
Frontend span filling
A fundamental set_span function has been introduced to TVM repo in TensorFlow frontend. The new implementation we proposed can resolve the following problems:
- Support TensorFlow 1 only.
- Only Call Expr is dealt.
- Not able to handle one-to-many conversion.
After investigations, we can support multiple frontends and resolve the problem 1. Based on the set_span derived from
ExprMutator, we can properly handle the problem 2 and 3.
Pass source information builder
The SequentialSpan extends the capability of Span so as to handle those multiple source transformations.
The SIBuilder is a new helper class for the developers when they are tagging span in a pass.
Schedule/Stage visualization enhancement
This functionality extends original design with some interface changes, so as to the existent tool, TEDD, which will
also be modified slightly. With this new feature, users could have better understanding on op implementation by visualizing
the effect of primitives.
Unresolved questions
- The standard of the line number definition for different IR.
It’s intuitive to do the source mapping by matching the literal information from different frontends, which also provide more readability. However, the span information could gradually get messy when expressions are merged together during optimizations. The situation might be mitigated by mapping IRs via line numbers. - Proper way to generate unique source information for ONNX frontend.
The source information relies on user’s annotation when making models. There remains some research to figure out a robust way of generating unique identifier once the source information is missing. - Concat suffix to the span to indicate the computation output expression.
Currently we have no strategy on highlighting expressions with special functions(e.g. input/output/parameter…). It would be helpful for user to categorize expressions at first glance.
Future possibilities
- This RFC would be a good reference for other frontends to add their span filling mechanism.
- Extend the span propagation scope from TIR to backend IR.
- Perhaps it is possible to have text format pretty print for
Scheduledata structure rather than usingTEDDonly. - Currently only the passes used by regular build flow are able to handle span propagation. We hope every pass could be well supported in the future to provide better debuggability.
Upstream milestone
We plan to have following PRs with corresponding test cases:
- Span filling for following popular frontends
- TFLite (PR)
- PyTorch (PR)
- TensorFlow (PR)
- ONNX (PR)
- Span propagation of Relay passes (passes within regular build flow will be covered)
- Source information builder (PR)
- Series of passes (PRs)
- Schedule/Stage visualization enhancement
- Schedule record and API changes (PR)
TEDDmodification (PR)
- Span propagation of TIR passes (WIP, passes within regular build flow will be covered)