Dear TVM community,
We, at Marvell, like to continue the discussion on Quantization within TVM. As starting point, we take Masahi’s response to the question by JosseVanDelm (Dec 2021): status on quantization in TVM https://discuss.tvm.apache.org/t/status-on-quantization-in-tvm/11668
We agree that pre-quantized models utilizing DL frameworks is the preferred way to quantize network. In particular we embrace the QDQ ONNX representation of quantized networks.
However there is a need to have a wider quantization support within a TVM flow, beyond the current support.
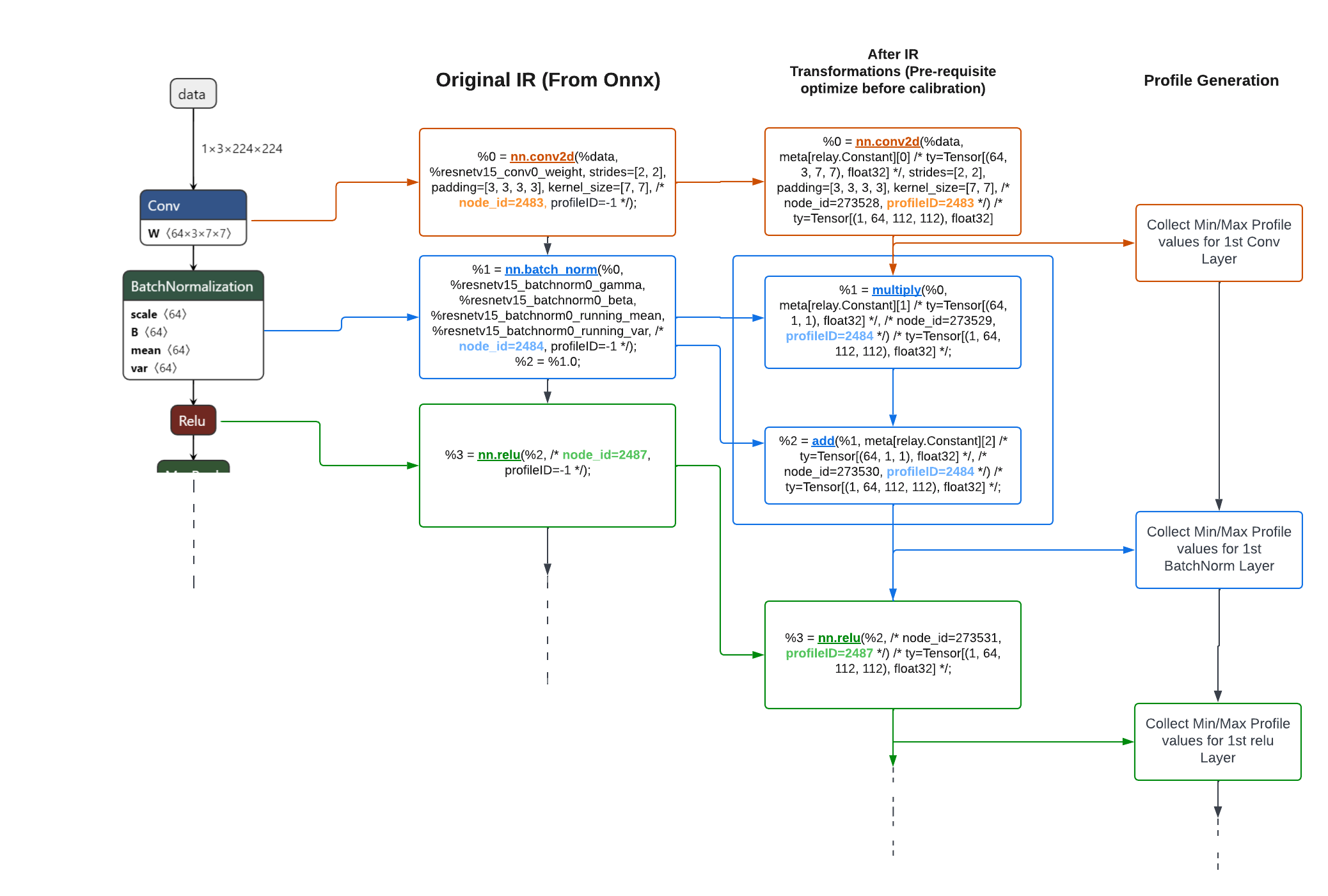
To enable HW vendors within their BYOC TVM flow, we propose, and are committed to deliver to the TVM community, a tensor range profiling functionality within the TVM flow that generates the needed profile information of intermediate tensors at each layer of the initial IR within the TVM flow. The resulting profile information can then be used during the network quantization within a BYOC flow. This is an extension of the relay quantization work https://github.com/dmlc/tvm/blob/master/python/tvm/relay/quantize. Noticing, that the current annotation by TVM quantization is for specific layers only, as seen in /dmlc/tvm/blob/master/python/tvm/relay/quantize/_annotate.py, we propose to instrument all layers and generate a profile data file which at a later stage can be parsed and selectively utilized. Our proposed profiling stage is near the beginning of the TVM flow and is instrumenting the initial IR. The profiling results are stored in a json file which contains for each layer the min and max values of each tensor. Currently we are limiting profiling to tensor ranges of a fp32 precision model run within TVM only, however it can be extended to other parameters, such as histograms and scales. As the profiling is done at initial IR, and TVM is transforming this initial IR into many consecutive IRs, it is required to have a linkage between IR representations. We propose to introduce a profileID that is added to each layer of the initial IR and being propagated along each IR transformation. The profileID is identical to the customID that was propose as tvm_custom_dict in our pre-RFC ( /apache/tvm/pull/9730). We propose this profileID, as we did not identify any tracking mechanism in TVM which could be used to create this explicit linkage. If there is such mechanism, which we missed to identify, please let us know and we will adopt.
It is our belief, that splitting up the profile generation from the actual quantization and code generation stage, and providing a general profiling support will serve the wider community well, and will allows HW specific methods in the BYOC flow, including selecting which layer to quantize and how.
We look forward to discuss this further with the TVM community and to provide a RFC for the extended profiling functionality.
Best regards,
Ulf Hanebutte Senior Principal Architect, Machine Learning Marvell