Hi @areusch
Sorry for late reply. Now I am able to grasp the whole concept of Relay Var porposal much better. Thank you for your
patience! ![]() We have some intuitive thoughts about it. But just like what you said, it deserves to have its own RFC if
we want to introduce this tracing map. I would put the discussion of it at the end of this post.
We have some intuitive thoughts about it. But just like what you said, it deserves to have its own RFC if
we want to introduce this tracing map. I would put the discussion of it at the end of this post.
Before that may I know would it be fine to prepare our PRs in this RFC if they look good to you? We can categorize the PRs to three independent parts:
- Frontend span filling
- Schedule recorder
- Pass sapn filling*
Currently most of discussions are about the pass span part. We can continue our discussions for it, and at the same time, if frontend span filling and schedule recorder look good to you, we will prepare their PR and submit them recently. On the other hand, if pass span filling is a good enough midterm solution we can also submit its PR later. Finally, based on our conclusion, we can create a new RFC about the Relay Var tracing map. Would this plan look good to you?
About the Var tracing map, I think it is a good mechanism. Because we can always find where is an IR expression from. Based on this idea we try to find what obstacles we need to break through. To me it is really a challenging topic. I totally agree to make a new preRFC for it. Haha
Data structure and what function to be called
-
Tracing map should be a <var, Array<var>> form.
To serve those n-to-n (n=>1) conversion, we need an array to preserve their relations.
-
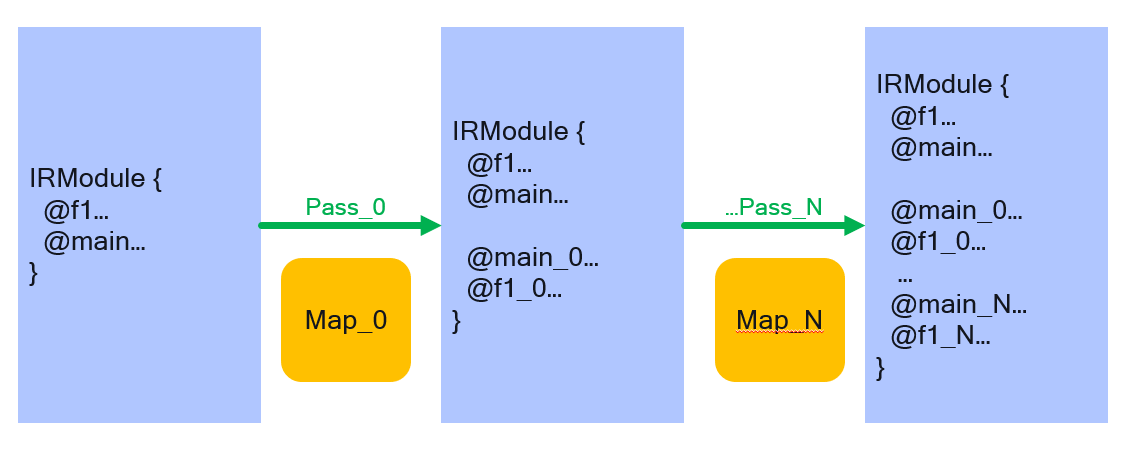
IRModule includes the historical map and functions during transformation
Therefore it might look like:
-
SIBuilder might not be necessary in this scenario
Since we could get expression mapping relationship through traversing tracing map. We can assign the span to an expr directly, no need to find the input/output of a transformation expression.
Obstacles we might encoutner
-
We might need to construct a new data sturcture according to the index of var.
I haven’t fully read the Doc Printer. But if there is an example look like this:
@fn () { %0 = ... } @main () { %0 = ... }Then we need to make our map be able to recognize which %0 we are talking about.
-
Annotating original expr to the transformed expr is time consuming
Basically it seems to me that this is the most doable way, but it is almost the same as what we are doing for the span filling. It would not be automatic enough, but at least it might be more easily to achieve.
-
Modify mutate_ of Mutator, Rewriter would invoke a big number of changes.
Almost all passes inherit from the Mutator or Rewriter, we would need to check them carefully.
-
Difficulty of make an analyzing pass
So far I have not figured out a workable method. It becomes hard to do analysis for those multiple source/results pass.
-
Should be aware of the performance impact:
Once we have a sequence of maps, and original Relay functions. We need to do a map traversing for each of expr in the end. The time complexity would be O(N*M), N is the number of expr and M is the number of maps.
That’s all we can come up currently. For the long term solution, we think a tracing map would be a necessary mechanism. Yet it should be planned carefully in case we encounter too much trouble. Currently the pass span filling can provide a roughly mapping after transformation. Perhaps we can still consider using this feature for now, and try to complete the tracing map for a better result.
Thank you again for reading this. We will stay tune with you! ![]()

 So far we cannot provide a precise date for it. Yet at least I would say it will happen after the features in this RFC are ready and stable in the TVM main branch.
So far we cannot provide a precise date for it. Yet at least I would say it will happen after the features in this RFC are ready and stable in the TVM main branch.
