Background
It is a great and challenging time to be in the field of AI/ML. Over the last year, we have witnessed a great number of innovations with the arrival of foundational models, including stable diffusion models for image generation, whisper for voice recognition, GPT, and open LLMs(llama2, MPT, Falcon, RedPajama).
We have learned a lot of lessons throughout our attempts to support the ML/AI ecosystem over the past five years. The opportunity is great for us if we act swiftly in the right time window. This post aims to capture our lessons over the past five years and discuss core strategies moving forward to support continuous innovation and emerging needs, such as dynamic shape modeling, stable diffusion, and large-language models.
High-level Goals
- G0: Enable innovation and growth to support emerging needs, such as new strategies of compilation, structured optimization, distributed settings.
- G1: Integrate components organically with clear core abstraction.
- G2: Connect to and amplify existing ML engineering ecosystems, including libraries like cutlass/CoreML and frameworks like PyTorch.
Past Lesson: Build centric approach is not sufficient
In the past, most of our approach has been a build flow centric view. The high-level model compilation is organized in a build flow, and presented to the users as a closed box. This approach serves us to some extent in optimizing our past needs.
The main issue of this approach comes when we start to support emerging needs over the past few years. As we work to solve challenges, we start to introduce new mechanisms into the build flow, such as BYOC, memory planning, shape handling, and library dispatching. The following figure depicts the build-centric approach we took in the past.
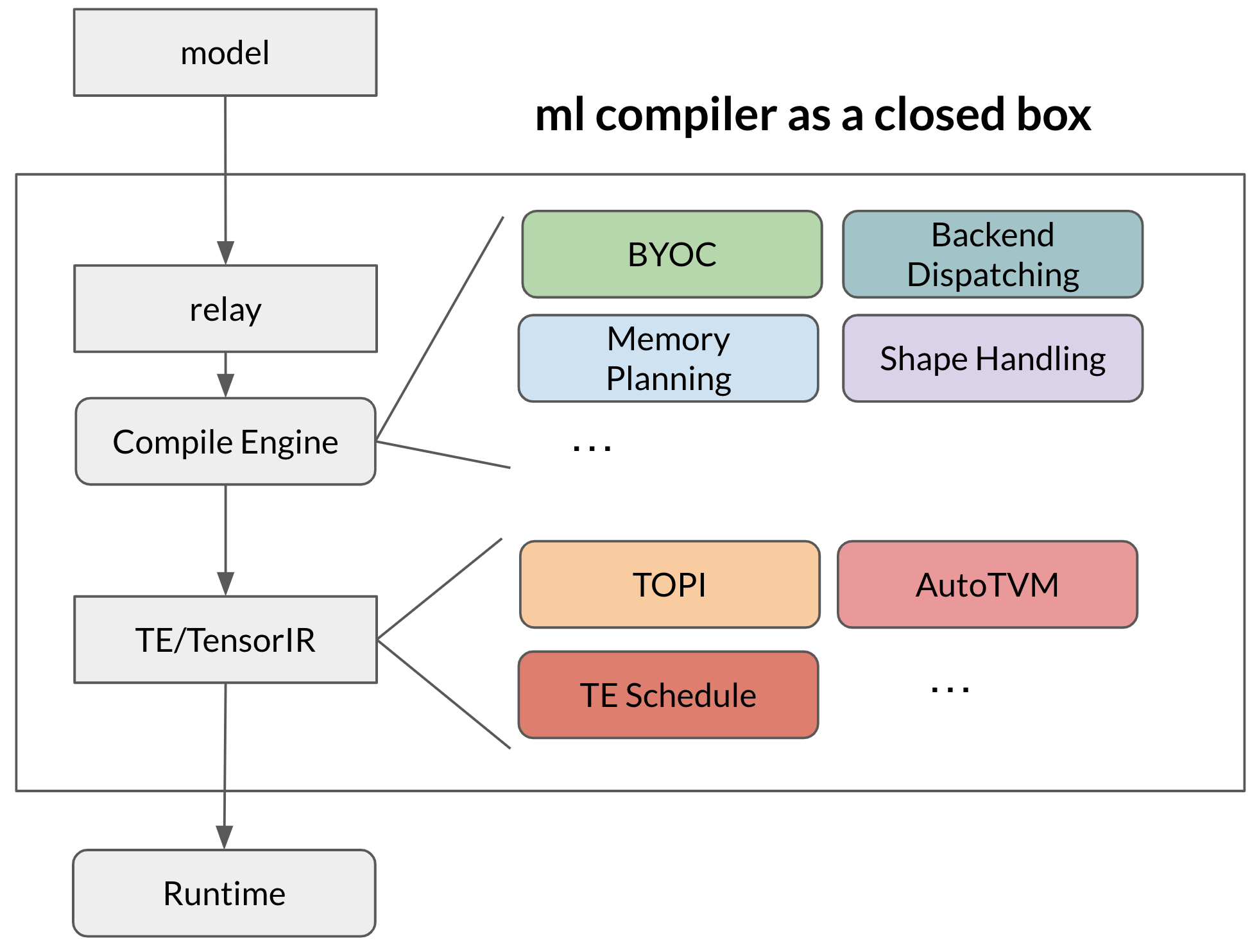
There are several limitations when we use this approach to tackle growing emerging needs:
- Each new mechanism are coupled with the build flow in a fixed way. We often need to manage the interaction between mechanisms(e.g., te scheduling, backend dispatching, and shape handling).
- It takes time to try out quick changes, such as dispatching a single layer to a new op library.
- Customizing new operators involves touching all the mechanisms along the build flow, including graph operator, lowering, and sometimes runtime.
The primary source of complexity comes from two factors: (a) The necessity grow set of mechanisms to support emerging needs. (b) Implicitly assumption of each mechanism imposed on the build flow and complexity of their interactions. Each mechanism can come with its own set of data structures and configurations and serves a subset needs of the community. One possible attempt to tackle the problem is to freeze the overall build flow as much as possible and avoid introducing new mechanisms. This could be a fine approach for some of the existing needs. However, as discussed in the beginning, AI/ML ecosystem evolves much faster and the key to success is to come up with infra that not only works for today’s needs, but is extensible to new demands coming up.
Unity Core Abstraction Centric Strategy
As discussed in the previous section, our primary concern is to capture our past lessons and bring a unified approach for emerging needs. We list the design principles as follows:
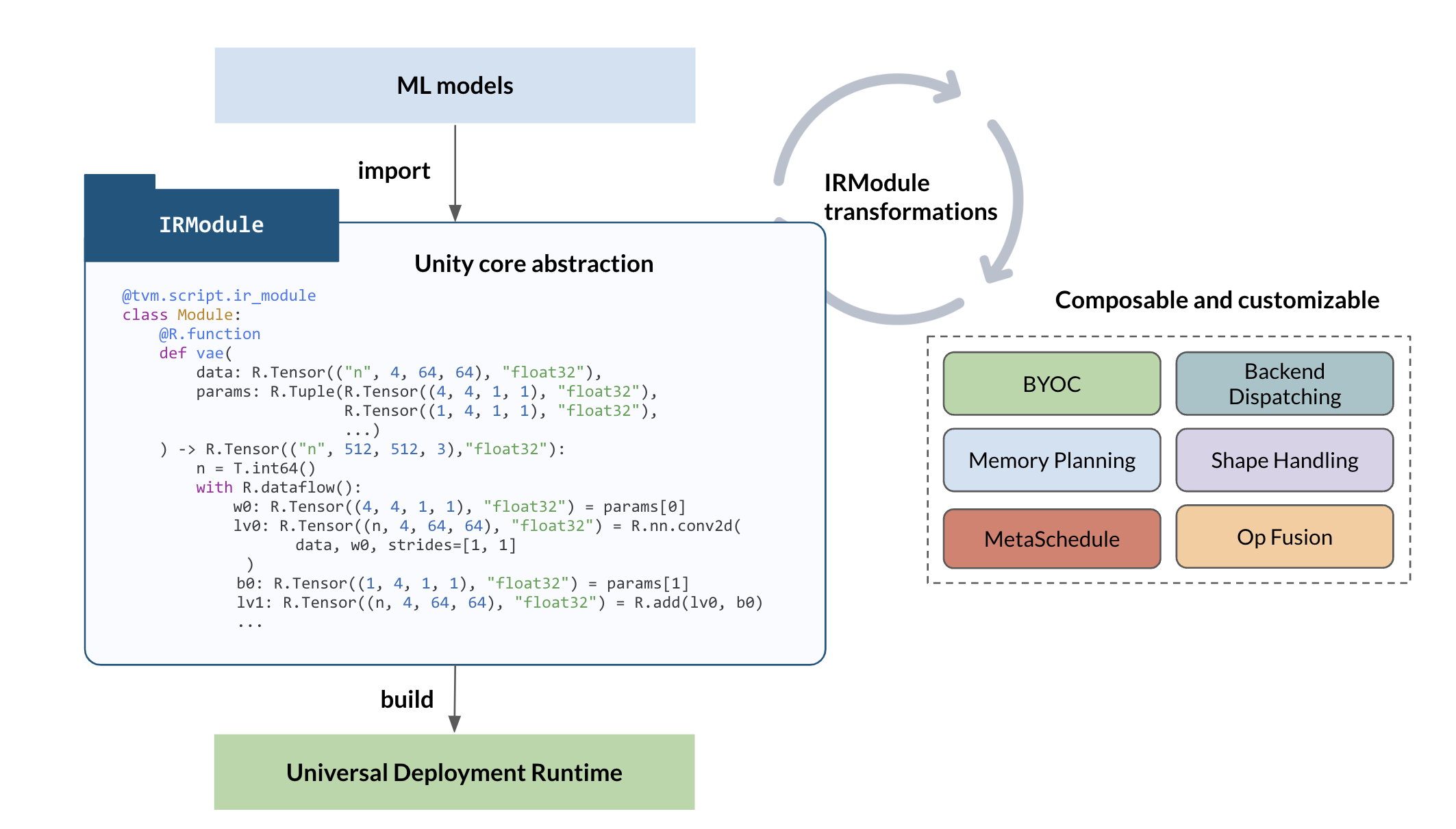
- D0: Core abstraction that serves as bridge for all emerging needs.
- D1: Universal deployment runtime that works with IR abstraction for general library extension.
- D2: Each new mechanisms are built on top of the core abstraction and runtime.
- D3: Specific flow composition on top of the core, enabling quick evolution.
D0 means that the compilation is not tied to a specific set of pipelines. Instead, we will focus on a core abstraction (unity core) that can capture the input/output of most optimizations. The particular abstraction would be representable through TVMScript. With D0 and D1 in mind, the overall key feature of TVM unity becomes more “flat”. Every state of IRModule has a reasonably “minimal” build — if modA contains unoptimized loops, building it will simply result in a module that runs the unoptimized loops; if modB contains something that does not tie the memory allocation together, the resulting build will simply dynamically allocate tensor during runtime. Instead, the additional mechanisms, such as memory planning or loop optimization (scheduling), are all part of the IRModule transformation.
The main benefit here is a great improvement in compositionally and development productivity — we will be able to apply BYOC and different approaches to TensorIR transformations and compose them together. We will also be able to use the same mechanism to integrate different library and compilation approaches together.
Finally, not every transformation needs to be aware of each other since the IRModule and the core abstraction are the common ground among the transformations. We can build customized transformations outside the main repo for a specific workload to gain quick experimentation, then bring some of the lessons back to a common set of utilities.
To realize these goals, we need the core abstraction to be able to represent and optimize the following key elements for emerging needs:
- N0: First-class symbolic shape support: ability to track and analyze shape relations.
- N1: Ability to represent computational graph, tensor program and libraries together.
- N2: Ability to extend to bring first-class structural information support, including first-class support for multiGPU/distributed setting and structured sparsity patterns.
Based on our past lessons and current technical state, we pick relax and TensorIR to form the core abstraction, with additional first-class support for universal deployment runtime, which we will discuss in the next section.
Relax naming interpretation. We know that there are some different background about how to interpret the namespace relax. Base on the current state of the community, we use the name relax to refer to “computational graph abstraction with relaxed assumptions for emerging needs”. Specifically, N0, N1, and N2 all align this with perspective. This is an evolved view of our previous computational graph designs (nnvm and relay) that come with a stronger set of assumptions for a build centric approach. Next, we will also list a few examples of how the unity abstraction-centric approach plays out for emerging needs.
E0: BYOC and Library Dispatch
Library dispatch or more general BYOC refers to approach where we replace a local function or sequence of operators into library calls.
@tvm.script.ir_module
class Before:
@R.function
def main(x: R.Tensor(("n", 4096), "float16"),
w: R.Tensor((4096, 4096), "float16"):
with R.dataflow():
lv0 = R.mm(x, w)
gv0 = R.relu(lv0)
return gv0
@tvm.script.ir_module
class After:
@R.function
def main(x: R.Tensor(("n", 4096), "float16"),
w: R.Tensor((4096, 4096), "float16"):
with R.dataflow():
lv0 = R.call_dps_packed(
"cutlass_matmul", [x, w], R.Tensor((4096, 4096), "float32")
)
gv0 = R.relu(lv0)
return gv0
call_dps_packed enables us to call into the cutlass_matmul function, which can be generated by BYOC, or simply registered to the runtime if there is a fixed signature.
E1: TensorIR Scheduling
The original TE operator scheduling is done in a coupled fashion between compute and loop scheduling. The set of autotvm templates, or topi schedules, is tied to each of the operators. Additionally, TE scheduling is a separate mechanism. Following the abstraction centric approach. We instead build scheduling and optimization functions as IRModule transformations.
These transformation scheduling rule contains two steps:
- Analysis of loops to detect related patterns, such as reduction and tensor contraction.
- Apply (possibly target dependent) transformations based on the analysis, and create targeted search space that is derived from workload/target, or a few tunnables expressed in MetaSchedule.
- If necessary, we can also have block specific tags that enables a more customized rule that do not depend on overall.
By default, we favor out of box rules that gives good performance. The tunable can be defined to further improve performance exploration. In such cases, we separate tuning from application of the tuned logs. Specifically, the build flow will contain a ApplyHistoryBest that will look up and transform the related TIR functions and such application works in the same way as out of box heuristic transformation passes.
E2: TensorIR and Graph Co-optimization
Importantly, the core abstraction needs to enable co-optimization across loop level and computational graph operations.
import tvm.script
from tvm.script import tir as T, relax as R
@tvm.script.ir_module
class IRModule:
@T.prim_func
def mm(
X: T.Buffer(("n", 128), "float32"),
W: T.Buffer((128, 64), "float32"),
Y: T.Buffer(("n", 64), "float32")
):
n = T.int64()
for i, j, k in T.grid(n, 64, 128):
Y[i, j] += X[i, k] * W[k, j]
@R.function
def main(
X: R.Tensor(("n", 128), "float32"),
W: R.Tensor((128, 64), "float32")
):
n = T.int64()
with R.dataflow():
lv0 = R.call_tir(mm, (X, W), R.Tensor((n, 64), "float32"))
gv0 = R.relu(lv0)
R.output(gv0)
return gv0
The above code examples shows how we can mix computational graph and TensorIR program(mm) together. We will be able to build transformations that co-evolve both parts. Including, but not limited to:
- Enable TensorIR to suggest certain preprocessing decisions(e.g. layout) back to graph level.
- Analyze the TensorIR for possible fusion opportunities.
- Lift allocations in TensorIR into the graph level to enable global planning.
Universal Deployment Runtime
Besides the core abstraction, the runtime plays an equally important role to enable emerging needs. The TVM core runtime contains the following elements:
- R0: A set of first-class core data structure (objects, function, ndarray) that can be universally embedded and accessed in the users’ languages of choice, including c++, javascript, python
- R1: PackedFunc convention that enables generated code, and libraries to call into each other.
We believe that such minimum and universal runtime is critical to our approach. Looking at the high-level approaches, we can see there are roughly two kinds of ways to think about compilation.
A0: fully internalized approach If we look at traditional use of languages like gcc, runtime is less as important, as everything is internalized. The result of compilation is a simple executable that handles everything in the deployment flow
gcc -o main input.cc
./main
A1: open interpolated and integrated approach If we look at a more interpolated approach, the result of compilation is different. The result of compilation is a module, that contains a collections of functions that are directly accessible in different environment languages like python. Each of those functions can take and return advanced in-memory data structures such as GPU NDArray, or even torch.Tensor(via dlpack). The application is usually build around these compiled functions, but also have supported mechanism around to compose these compiled functions (e.g. make them work with torch.Tensor).
import tvm.script
from tvm.script import tir as T, relax as R
@tvm.script.ir_module
class IRModule:
@R.function
def prefill(
X: R.Tensor(("n", 128), "float32"),
params: R.Object
):
...
@R.function
def decode(
X: R.Tensor((1, 128), "float32"),
params: R.Object
):
...
mod = mlc_compiler.build(IRModule)
res0 = mod["prefill"](input_array, params)
res1 = mod["decode"](decode_input, params)
Recap of approaches listed above
- A0: fully internalized approach
- A1: open interpolated and integrated approach
Additionally, the philosophy of A1 also means we need to enable first-class integration of functions from different languages, such as customized torch code, or cutlass cuda kernels depending on user needs.
While both A0 and A1 could be a fine approach in a traditional setting. Most of the traditional compilation stack would starts with A0. However, in the context of ML/AI, we find that it is important for us to take A1 to be successful.
This remark is based on our observation that ML ecosystem benefit from collaborations from various fronts, where compilation and integration can happen organically at different levels. A1 also places a less restrictions on the developer, as they would be able to take the language of their choice for deployment (and sometimes optimizing part of the workloads) and we can bring the infrastructure to them.
Finally, taking A1 enables an incremental development path — we can always start with custom defined data structure and code for key optimizations such as KV-cache, while gradually evolving to advanced code generation techniques with the same interface.
Going through A1 do place a stronger needs on the runtime, as the runtime would need to have R0 and R1 elements. We had a strong TVM runtime design that can serve as the as the foundation.
We remark that A1 is in generally a must have for emerging applications like LLM applications, where the application layer needs to have a broad set of interactions with the generated model (such as prefill, decode, or advanced batching updates).
For special scenarios, e.g. when the runtime env have very limited resource, we might enable a more restricted set of features of A1 (e.g. limit kinds of dynamic data structures). Such decision can be left to community members to bring scoped modules that interacts with the core abstraction.
Enabling the Core Strategy for the Community
This section talks about the mechanisms to bringing the unity core abstraction centric approach for emerging needs. We acknowledge that the build centric approach can handle some of the existing needs. So we would enable the unity core abstraction to co-exist first with the existing modules. Existing modules will continue to function in their respective namespaces and support some of the existing needs.
With the unity-core abstraction centric view in mind, we anticipate future usages of the TVM stack can involve customizations and improvements for different verticals (such as LLM, stable diffusion) while sharing the common abstraction principle as the bridge and common ground.
The complexity of emerging needs will go into the unity core abstraction centric approach and being managed in a unified fashion. As the abstraction centric design enables great rooms for continuous innovation in areas such as structured sparsity, distributed and other settings.
The adoption of approach can depends on vertical and the the interest of the community. We anticipate the new foundational models (LLM, stable diffusion, distributed workloads) will start from unity core abstraction.
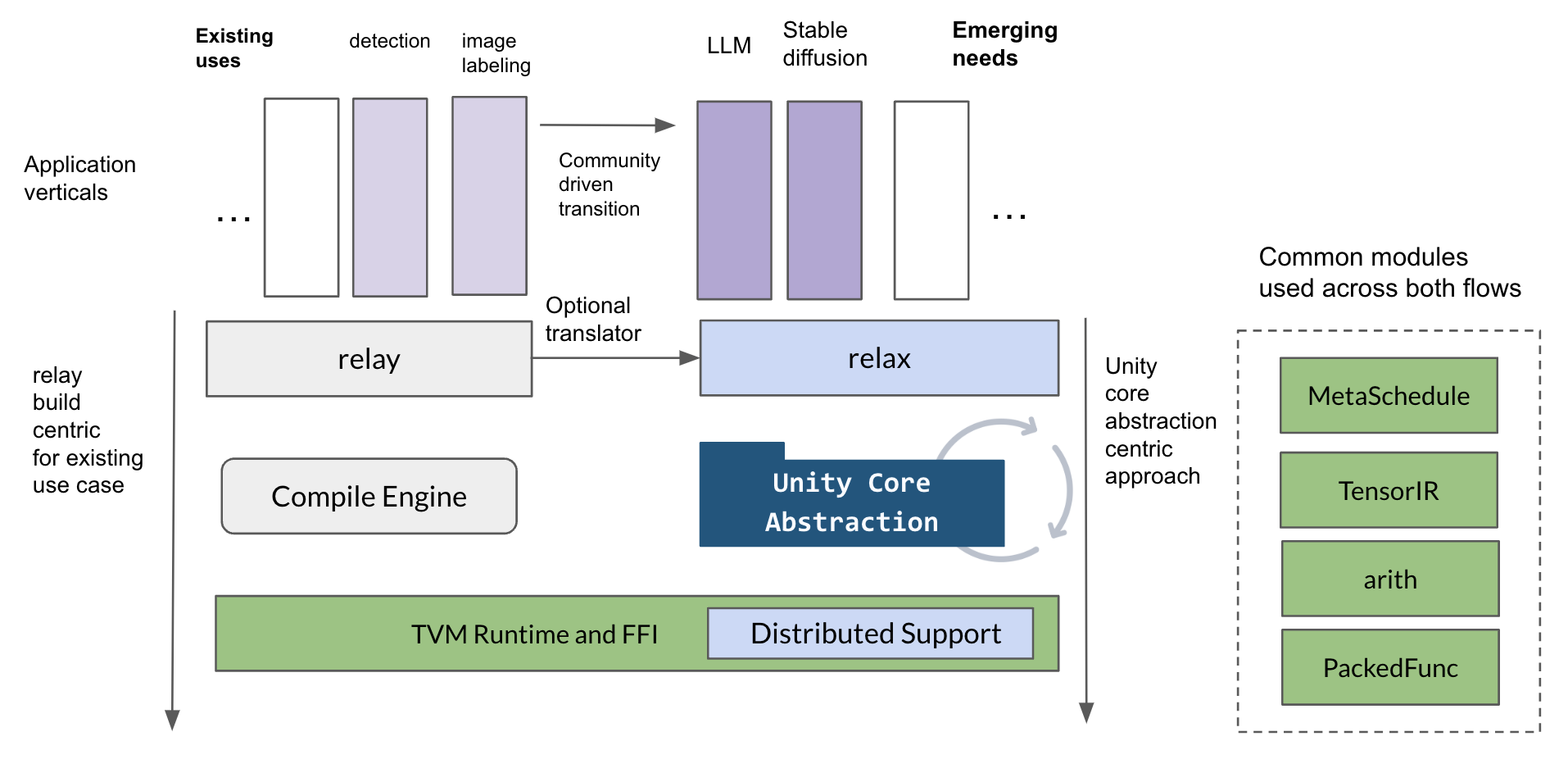
Depending on community interest, we also anticipate community to enable some of the existing verticals through the unity abstraction centric approach on a per vertical basis. We provide tools like relay translator to facilitate such transition. Additionally, we also bring frontend importers such as pytorch and onnx to support first-class dynamic shape import.
We do not anticipate a one to one mapping from existing approaches to the new one in a fine-grained fashion, since the nature of core abstraction centric approach is providing an alternative, more flexible approach to the overall problem. Many problems like operator fusion and memory planning will get simplified in the new approach. Instead, we will think about the vertical needs(e.g. supporting image labeling), and enable the vertical using the new methodology. The enablement of per vertical basis also empowers sub-community to make their own call of when and what to do.
As an open source project, the execution of the strategy of course depends on community. We will access the state depending on community engagement and needs, and empower more people to have their vertical supported. Due to the fast moving nature and diverse needs, we will empower a more extensible approach with strong foundational principle that ties things together (as things being centered around the abstraction).
Because we are also community driven, we would anticipate growing importance of importance of emerging needs and alignment on that direction due to community’s interest — as being shown in our latest surveys and discussions around foundational model. This approach allows us as a community to continuously access the situation at a per vertical basis and make timely informed decisions based on the technical developments and the state of ML/AI ecosystem.
