Background
This doc aims to discuss how we should do operator scheduling(and optionally tuning) following the TVM Core strategy for emerging needs. Operator scheduling refers to the phase where we take high-level description of the operators and bring more performant code. This process is usually called scheduling.
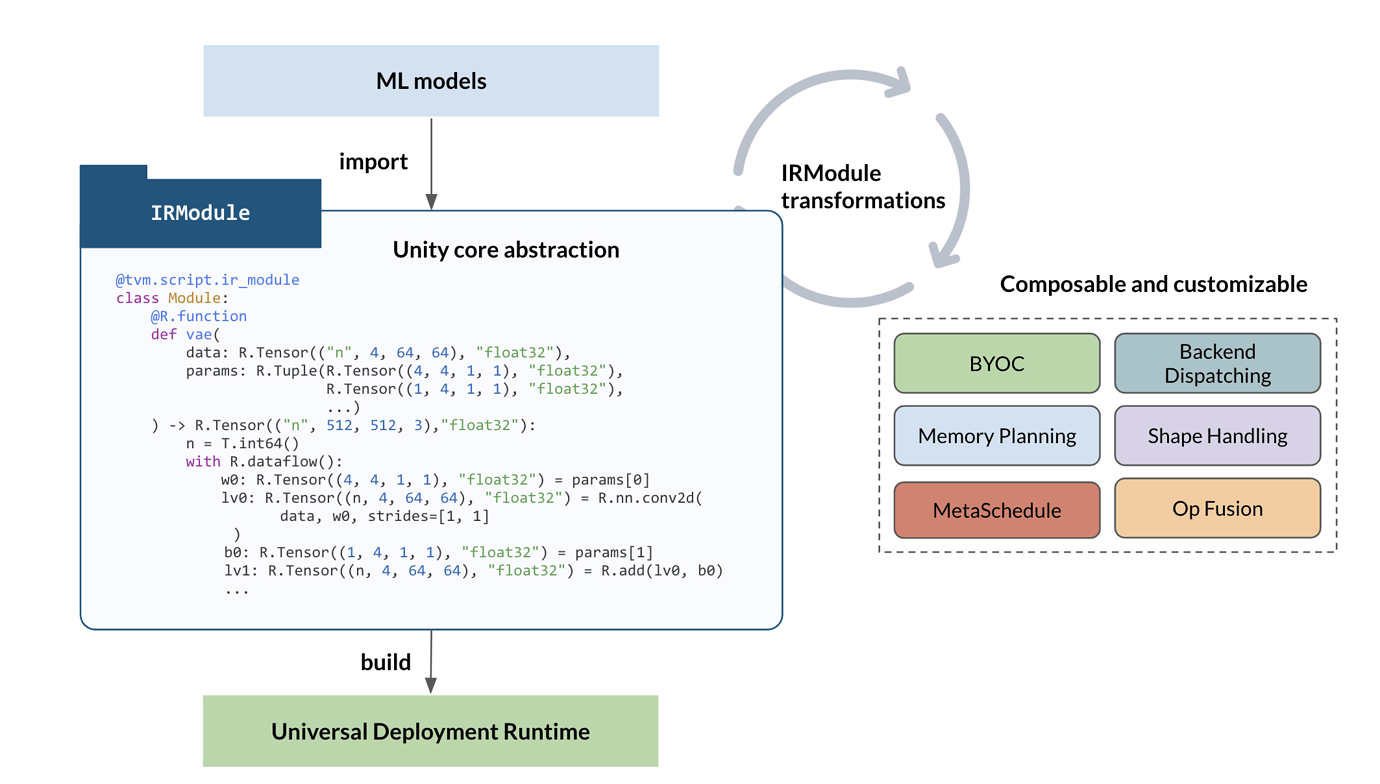
Over the course of development, we have several components.
- TE-compute: ability to describe high-level computations via tensor expression.
- TE-schedule
- TensorIR: IRModule compatible abstraction for low-level tensor programs
- MetaSchedule: scheduling and auto-scheduling support for TensorIR.
Additionally, we have libraries to declare a set of common compute and possible optimized schedules around them:
- TOPI-Compute: the compute definition
- TOPI-Schedule: a collection of manual schedules that accompany the compute
Most of the prior compilation flows are build-centric, causing the scheduling to be deeply coupled as a fixed step of operator scheduling within the compilation. There are several levels of coupling here:
- C0: The topi-compute and topi-schedule are usually deeply coupled, as the schedule needs to operate on a particular kind of compute.
- C1: Tuning and application of tuned results are coupled, causing the build step to always involve a long tuning time.
- C2: The mixing strategy of manual schedule, different library dispatch, and auto-scheduling are coupled because the dispatching of operators has to be done in a single shot.
Proposed Strategy
TVM’s core strategy for emerging needs provides a high-level guideline to address the above challenges. In this section, we will elaborate on the general technical strategy we should take moving forward. The strategy contains the following key principles:
- K0: Scheduling of an operator is done via IRModule⇒IRModule transform, where we update each TensorIR functions.
- K1: Tuning of the TensorIR functions decoupled from the application. We can have a preprocessing pipeline to extract tasks. After tuning, we simply have an ApplyBest pass that pattern matches the TensorIR and rewrites to the best-tuned functions. This approach aligns with K0.
- K2: Library dispatch and BYOC are done through a separate pass that also follows the K0 strategy, and we can customize the orders and selection strategies to enable the composition of library dispatching, manual schedule, and optional tuning.
K0 is especially important, as it helps us to create a modular set of optimizing components that do not need special support within a build pipeline. Such an approach also allows multiple developing communities to bring new approaches and compose them together concurrently. We highlight a few of the current infrastructures that follow these principles.
- MetaSchedule contains infrastructure for manual scheduling and application of the Database as an independent pass.
- dlight — is a strategy-based module that detects the pattern and performs general rewrites for GPU kernels. We also start to see fast-delight, which combines domain knowledge and tuning.
- Sometimes, it is helpful to leverage structural hash and equality to simply create manual dispatching of tensorIR to already optimized TensorIR; we find this approach useful to do quick performance exploration before capturing them in more generic passes.
Suggestions for Future Development
While we will continue to maintain some of the existing approaches, this post aims to provide a guideline for our new development thrusts. Here are some of the suggestions
- S0: Move from TE-Schedule, TOPI-Schedule for new developments and use TensorIR/MetaSchedule.
- S1: Continue to leverage TE-Compute only to create TensorIR functions.
- S2: Leverage MetaSchedule infra for autotuning application. While we can create different modules to form different search spaces (the fast dlight example), we can reuse most infra for tuning and application of the best result.
- S3: Supply manually specialized TensorIR when there is a demand, as long as we isolate them as K0 passes.
Discussions
We already successfully applied these principles for GenAI developments like LLM and see great development productivity from the approach. So, this post aims to summarize these lessons as a strategy that we think can benefit the overall project. It would also be good to bring and examples around these principles and new ideas to make the scheduling and optimization better.
Also love to see specific examples and usecases you see and we can discuss how the new paradigm can help those cases.