We are in a new age of genAI, with the arrival of new workloads and learnings from our many years of building machine learning compilation pipelines. As a community, our core strategy also evolves from a more build-centric view towards a more Unity core abstraction-centric strategy. As the unity branch gets merged and we start to push towards the new strategy, we also need to keep the documents up to date and this core strategy. Motivated by these needs, this post proposes a documentation refactor.
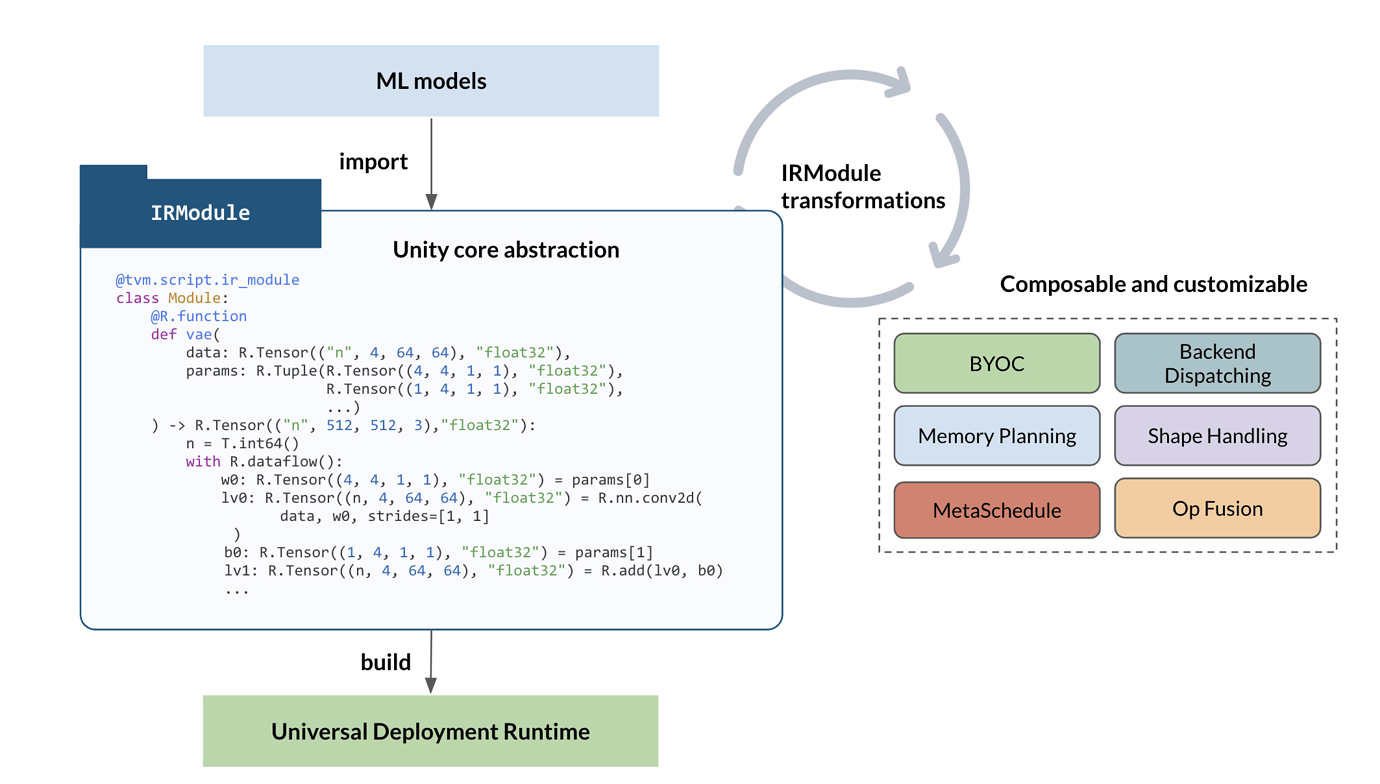
First, we would like to have a few focused documents that help the users understand the core abstraction-centric view and what they can do to build and customize ML compilation pipelines for their own model and hardware environment needs. Additionally, we would like to have a small collection of focused how-to guides that also closely connect. Finally, we would need to provide mechanisms for existing and future sub-components to organize their respective documentation under the specific topic guides.
Theme and Rationale
We would like start by touching the motivation of the project and the key goals of the project. As machine learning becomes increasing important in the age of genAI, we would like to collectively bring optimized AI applications everywhere for everyone. ML compilers provide tools to help ML scientists and engineers on the following goals:
- G0: Optimize performance of ML workloads.
- G1: Deploy ML models to a diverse set of hardware and runtime environments.
- G2: Integrate the compiled modules into current ecosystems, as optimized operators, accelerated modules of subgraph computations, and backend for key genAI APIs.
Importantly, there is a strong need for G3 - continuously improve and customize the compilation approaches as we start to focus on specific model verticals; for particular hardware backend or distributed environments, there is a strong demand. This last goal means we need to empower the community to build their own TVM-based compilation pipelines by bringing in new compilation passes and integrating with performant libraries and novel code generation approaches.
The key goals would serve as the anchor to convey the overall abstraction centric approach through a quick start guide
Quick Start Strawman
- What is ML compilation
- What can ML compilation do (list the G0-G2)
- Overall flow of ML compilation pipeline
- Import/construct a model
- Perform composable optimization transformations
- Leverage “pipelines” to transform the program
- The pipeline encapsulates a collection of transformations in two categories:
- High-level optimizations such as operator fusion, layout rewrites
- Tensor program optimization: Map the operators to low-level kernel via library or code generation
- Build and deployment
- Each function becomes a runnable function in the runtime
- Integrates with runtime environments (c++ and python)
- Customizing the ML compilation pipeline
- State G3
- Everything centered around IRModule transformations
- Composable with existing pipelines
- Example: dispatch to library:
- We would like to quickly try out a variant of library optimization for certain platforms
- Write a dispatch pass
- How it compose that with existing pipelines
- Example: fusion
- Standard pipelines
- We provide pipelines as standard libraries
- Allow quick specialization for specific domains, e.g. LLM
- Integration with ecosystem
- Bring compiled function as Torch module
- What to read next
- Read some of the topc guides sessions
- Read how to section for more specific guides for extending different perspectives.
How to guide common pattern
As we start to build new how-to guides, we explicitly encourage the following pattern to emphasize the connection of each guide to the overall approach. Let us take say TensorIR schedule as an example; we will use the following outline.
- S0: Introduce elements of TensorIR
- S1: Show examples of transformations and how they impact performance
- S2: How does TensorIR fit into the overall flow?
- Give examples of TensorIR match and dispatch pass
- Show how to compose it with a default build
- Discuss scenarios where it can be used: e.g. provide customized optimized kernel for a specific backend.
Specifically, every guide should include S2: how does it fit into overall flow. This approach helps us to bring things back into the bigger picture and allow users to know how each guide can be composed with other ones. This enables the guide to be more focused and connected to the central theme.
Overall Structure
The last section discusses the key goals and how they impact get started and how to guide. This section outlines the overall structure of the documents. Quick start and how to (that have clear S2 section) aims to provide cohesive set of documents that presents the projects through core abstraction centric approach in genAI. The TOPIC GUIDES section will contain tutorials and guides about specific module in organized ways. We can also use these sections to provide deeper dives of the corresponding modules. This section also allows us to preserve docs about some existing modules that have their own usecases.
- GET STARTED
- Install
- Quick start
- HOW TO
- Apply Default Tensor Program Optimization
- Dispatch to Library
- Optimize GEMM on CPU
- Support Customized Operator
- Use call_tir when possible
- Example: Rotary embedding operator
- Use call_dps_packed
- If necessary, can add new op to system
- Bring your own customized codgen
- Construct model with nn.Module API
- Import from PyTorch
- Import from ONNX
- Optimize Object Detection
- Remote Profile using TVM RPC
- Contribute to this document
- more…
- TOPIC GUIDES
- Relax
- TensorIR
- Runtime and Library Integration
- MetaSchedule
- nn.Module
- micro
- Relay
- AutoTVM
- more..
- REFERENCE
- APIs
One motivation is to avoid deep nesting, have fewer key docs that explains concepts but bring connections to the overall approach, while also bring enough room for content for each specific topics independently.
Discussions
The main goal of the post is to kickstart some of the effort. Hopefully we can bring together a good structure that enables us to continue innovate through the core strategy for emerging needs. Would also love to see more tutorials, guides and discussions about how we can bring fun usecases and optimizations, see some of the examples below