Motivation
Cloud devices are more powerful than Edge devices, which provides higher computation capabilities for deep learning workloads. For example, for the VTA core, with Cloud devices, we have more resources to support larger GEMM cores (e.g., 32*32 or even 64*64) and device buffers, thus making it possible to boost the performance to great extent. Therefore, it is worthwhile to provide a generic framework to support cloud devices under TVM/VTA architecture.
However, it is non-trivial to extend VTA to Cloud devices. Because the original Xilinx HLS VTA core only works on Xilinx Edge FPGA devices, and Cloud devices exposes different communication models (i.e., shared memory between ARM cores and FPGA device for Edge, vs., PCIe between host and FPGA device for Cloud), and different programming models. In this work, we propose to design a unified framework that can be adapted to any OpenCL-compatible hardware accelerators, e.g., FPGA, ASICs, to seamlessly work with the TVM-VTA architecture. Meanwhile, we provide an example of OpenCL-based VTA implementation that has been tested on the Intel’s high-end FPGAs.
Proposal
We would like to extend VTA to OpenCL-compatible devices (e.g. Intel Programmable Acceleration Card). In particular, we provide a framework where any OpenCL-compatible devices can be easily integrated. The reason we choose OpenCL-compatible devices are:
- OpenCL is generic enough to support a group of devices. For example, both Xilinx and Intel are now in transition towards OpenCL based HLS approaches.
- Vendor-specific optimizations are built-in within their respective OpenCL SDKs (e.g., pack two 8-bit multiply-add units into 1 DSP slice), but the framework we’re providing does not limit to specific SDKs.
In addition to the generic OpenCL framework, as a first attempt for the hardware implementation, we would like to base on Intel Cloud FPGA (e.g. Intel Programmable Acceleration Card) using Intel® FPGA SDK for OpenCL, which has proven portability and scalability for both Intel® Programmable Acceleration (PAC) cards and other custom Intel-FPGA-based acceleration cards. But the overall framework is generic, meaning that any OpenCL-compatible devices can be plugged in with only little extra hardware-specific implementation.
Major works
-
Efficient communication between host and PCIe devices as PCIe transmission is costly compared to memory copy
- To avoid frequent PCIe copies, we propose to let all middle layers of a computation graph to completely run in FPGA devices, without interleaved CPU layers. In particular, originally, residual block in Resnet run in CPU (ARM cores), which may cause copy in and out from device memory frequently. The addition of extra VTA instructions are intended to move this kind of residual block to FPGA device.
- Do copy of uops and instructions in a batch. In particular, only do synchronization after all on-device layers are queued, or queues are overflowed.
-
Support auto-copy between layers running on different devices. We propose to add a few more IR passes:
- annotate device types for computation graph
- tag and propagate device types among layers
- add copy operations (device_copy) automatically if adjacent layers are not in the same devices
-
Driver development for OpenCL-compatible devices
- The original pynq driver could not be used as we do not have direct access to h/w registers
- We implemented a middle layer driver for OpenCL-compatible devices
- The layer sits on devices’ native driver stack, which implemented an interrupt based device driver
-
OpenCL hardware implementation
- Addition of extra Load/ALU instructions, such as Load int8 to ACC buffer (to support ALU-only nodes), ALU Multiply and Left-shift, to support more continued calculations on FPGA
- Refactored the hardware implementation code to conform to Intel® FPGA SDK for OpenCL as a sample hardware implementation
Major changes to the existing TVM/VTA framework
-
To run a workload on cloud FPGA, there is no need to launch additional service on the device side (e.g., rpc server). All the driver and runtime programs are running in the host side.
-
Change VTA runtime to support batch queue synchronization. We intend to only queue the instructions/uops when running a layer and return immediately without doing device synchronization. We only do synchronization and device run when queues are overflowed or the next layer is not on-device。
-
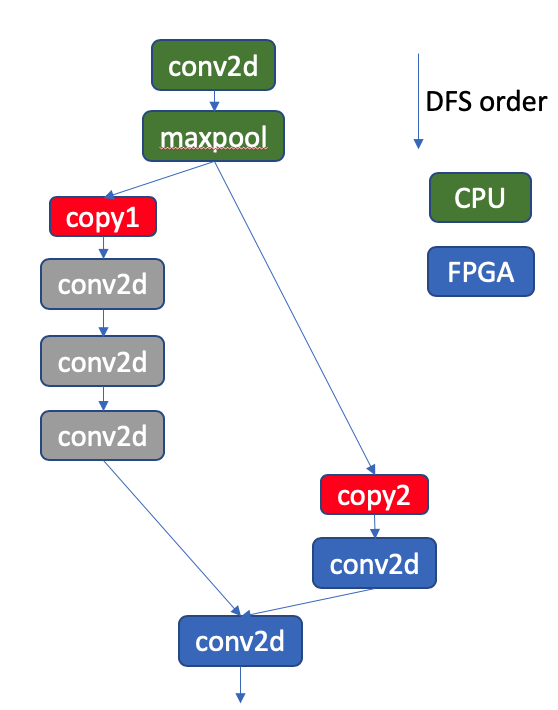
We have to modify the device propagation behaviour from post DFS traversal to recursive method. Originally, device type is propagated based on the post DFS traversed graph, which may not be consistent if the argument order changes. In addition, it may handle some cases wrongly, e.g., the first residual block in Resnet50. The first few layers in Resnet50 are depicted in the following figure (top to bottom is in DFS order). Basically, we want to let all the layers run on FPGA device, except the first and last few layers. In the original device propagation algorithm, based on the post DFS order, the conv2d layers in grey will be propagated with
CPUdevice type as we encountercopy2first, following which the three grey conv2d nodes are marked as the source device type ofcopy2(i.e.,CPU), which is not correct.
Limitations
- Virtual thread is not yet supported for intelfocl devices, so all instructions are running sequentially.
- In the first version, we require all middle layers running on the FPGA. Thus some networks whose operations in these middle layers are not supported by hardware may not be supported, as it causes a mix of CPU and FPGA operations in-between and it is hard to be annotated with correct device types automatically. This restriction can also guarantee there are no frequent device copies between layers. We may relieve this restriction in the future versions.