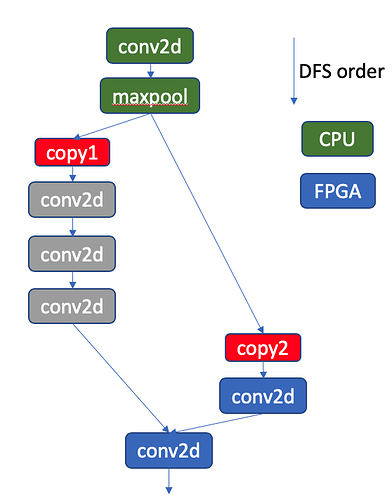
I think the runtime support here (https://github.com/apache/incubator-tvm/pull/3554) is for uop and instructions sync via PCIe. However, if we want to run a full network (e.g., Resnet), we’re still missing layer-wise synchronization/device_copy if two adjacent layers are resident in different devices.
Thank you for the reply @remotego, I agree with your views. As you mentioned, using OpenCL is a good way to bootstrap an accelerator design quickly. I myself did that with VTA when I wrote it in HLS as a grad student, so I see its value!
There are definitely strong pros/cons of HDLs vs. HLS languages. Ultimately if we want to give people choice, we should have a good CI testing story as Liangfu pointed out. But I do encourage you to give Chisel a try. It gives you the best of both worlds in terms of building higher abstractions (e.g. Bundle), while providing a good and easy to interpret mapping to RTL.
That said we welcome this addition in OpenCL. For now we’ll need to address the lack of consistent CI testing framework for the multitude of designs we have for VTA. @liangfu did you want to suggest some approaches there in an RFC? I’d be happy to work with you on that RFC.
In one of your posts above you mentioned that you have implemented theproposal. Have you tested it with some models? which fpga board you used? what are the performance numbers compared to vta on fpga soc? Is your code available in a repo somewhere? I really like to test it with some models and use it for my purpose. I don’t have enough time to add the driver support and inter layer synchronizations for my project.
Thanks for your interest. Yes, we’ve tested some models, e.g., Resnet_XX. Currently we’re using Intel A10. The performance on Cloud FPGA is much better than Edge FPGA (e.g., ultra96), as we have more resources to enlarge the GEMM core size. We’re still doing much performance optimization from both software and hardware aspects.
We’re preparing the code for PR, and the basic version should be ready soon.
I like to have your opinion on using soft cores for pcie based fpgas. Rather than going through the high latency communications between the host and fpga or as you did running all the middle layers on the fpga itself, we can offload runtime stuff on a soft core (nios, microblaze, or better a riscv core). what’s the downsides here?
In my opinion, the performance of those soft cores are quite poor compare to server-grade processors (for processing speed, number of cores and memory bandwidth). I would estimate the overhead due to slow processor will be much larger than the overhead of PCIe communications.
We want to use TVM for our ADM-PCIE-KU3 (Xilinx Kintex UltraScale) FPGA board. I wanted to ask if TVM support for server-class FPGAs (PCIe connected) is stable? Does it provide the required driver support?