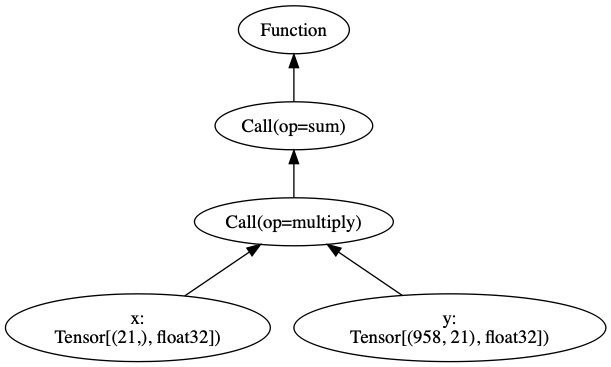
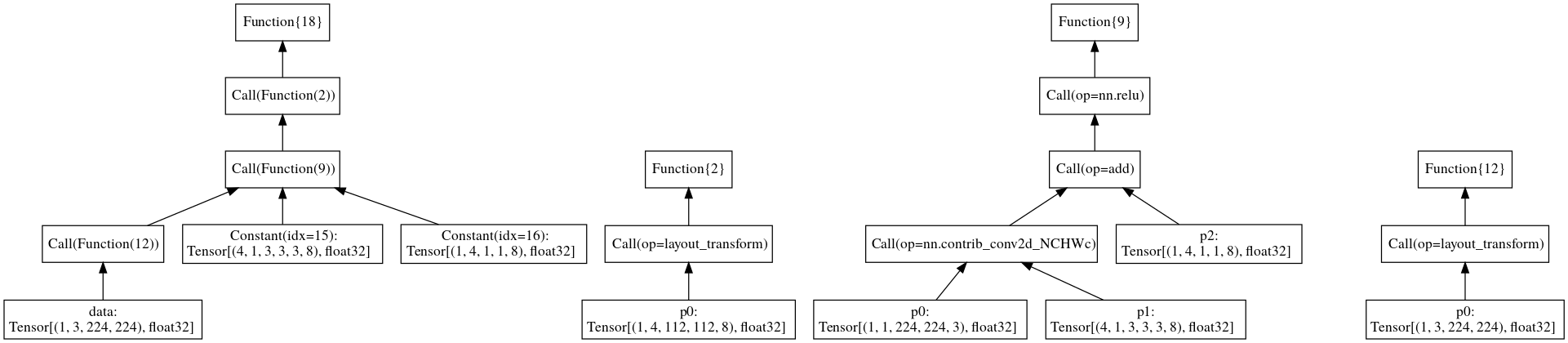
Per @tqchen’s suggestion, we should have Relay produce a JSON-like data representation that can be ingested by multiple visualizers (GraphViz, Netron, TensorBoard). I’ll refer to this data representation RelayViz. In this document, we write RelayViz objects as JSON objects.
Specification for RelayViz data representation
Root object layout
{
"format": "relayviz",
"version": [1, 0],
"nodes": [ <list of nodes> ]
}
General principles
- Many nodes in Relay (Call, TupleGetItem, Function etc) have references to other nodes. Such references should be encoded as an integer ID. The integer ID locates the referenced node in the “nodes” field of the root object. For example, a Function node has a
body attribute that refers to another Relay node. So the Function node should store the node ID of the function body.
- All attributes of Relay nodes that are not node references should be encoded as an attribute.
Example: Function node (one node reference, one attribute)
{
"node_kind": "Function",
"body": <node ID of function body>,
"ret_type": {
"dtype": "float32",
"shape": [64]
}
}
Example: Call node (five node references, two attributes)
{
"node_kind": "Call",
"op": "nn.batch_norm",
"args": [
<node ID of first argument>,
<node ID of second argument>,
<node ID of third argument>,
<node ID of fourth argument>,
<node ID of fifth argument>,
]
}
Spec for particular nodes
This spec should cover all Relay nodes in https://docs.tvm.ai/api/python/relay/expr.html. All appearances of bracketed phrases (<...>) should be interpreted as placeholders.
Function node
{
"node_kind": "Function",
"body": <function body (node ID, integer)>,
"params": [
<Input variable (node ID, integer)>,
...
],
"ret_type": {
"dtype": <type of tensor element (string)>,
"shape": <shape (dimension) of tensor (list of integers)>
}
}
Note: each element in the “params” field must refer to a Variable (Var) node.
Var (variable) node
{
"node_kind": "Var",
"name": <name of variable (string)>,
"dtype": <type of tensor element (string)>,
"shape": <shape (dimension) of tensor (list of integers)>
}
Note: we set the “shape” field to an empty list ([]) for scalars.
Call node
{
"node_kind": "Call",
"op": <name of operator to call (node ID, integer)>,
"args": [
<call argument (node ID, integer)>,
...
]
}
The value for the “op” field shall correspond to an Operator node.
For now, we skip attrs argument in tvm.relay.expr.Call.
Operator (op) node
{
"node_kind": "Op",
"name": <name of operator (string)>,
"attrs": <attributes for the operator (dict)>
}
The “attrs” should store the attributes specific to the operator. For example, the convolution operator (conv2d) should store padding and strides as attributes. For the sake of simplicity, I will skip the “attrs” field for my upcoming pull request.
Const (constant) node
{
"node_kind": "Const",
"value": <value of the constant (int, float, or dict)>,
"dtype": <type of tensor element (string)>
}
Note: if the constant is a tensor, then the “value” field will be set to the object
{
"array_value": <array value (list of floats)>,
"array_shape": <shape of the tensor (list of integers)>
}
Bind node
{
"node_kind": "Bind",
"expr": <the input expression (node ID, integer)>,
"binds": {
<variable_name> : <expression to bind (node ID, integer)>,
...
}
}
Note: In tvm.relay.expr.bind, the binds argument may be one of the two types:
- Map[tvm.relay.Var, tvm.relay.Expr]
- Map[str, tvm.relay.Expr]
If binds is of type Map[tvm.relay.Var, tvm.relay.Expr], then set the <variable_name> placeholder to a value of form “node_XXX”, where XXX is the node ID of the Variable node.
Tuple node
{
"node_kind": "Tuple",
"fields": [
<tuple element (node ID, integer)>,
...
]
}
Let node
{
"node_kind": "Let",
"variable": <local variable to be bound (node ID, integer)>,
"value": <value to be bound (node ID, integer)>,
"body": <body of the let binding (node ID, integer)>
}
If node
{
"node_kind": "If",
"cond": <condition to test (node ID, integer)>,
"true_branch": <expression evaluated when condition is true (node ID, integer)>,
"false_branch": <expression evaluated when condition is false (node ID, integer)>,
}
TupleGetItem node
{
"node_kind": "TupleGetItem",
"tuple_value": <input tuple (node ID, integer)>,
"index": <index of element to be extracted (integer)>
}