This is a follow up RFC for Compute Graph Pipeline
Split relay graph into Subgraph then doing Subgraph Pipeline :RFC
In this RFC, we present a new framework for subgraph pipelining that first split relay graph into multiple subgraph/group operator s then doing subgraph/group operators scheduling , this frame work would include 3 parts, the logic is self contained , PR submitted as https://github.com/apache/tvm/pull/7892
#1. Relay graph splitting.
all the logic in this function analysis.py:pipeline_graph, this function input is a “relay graph” and an integer array to represent
the subgraph split logic and the output is multiple "relay graph " as “subgraph” that can get use for future pipeline scheduling.
#2. Runtime/Executor and Interface
subgraph_executor.h in folder src/runtime/subgraph/
and
subgraph_executor.py, are the subgraph executor/runtime logic, that implement the interface to interact with frontend part logic to
“create subgraph executor”,“set input”, “run” "get output " and “stop”
#3. Scheduling and Memory movement
other file except runtime/executor files mentioned in #2, implement the “pipeline scheduling”, “memory movement” and “Syncolization”
logic.
Before this RFC, I have an Initial version RFC that just discuss/implemented the “Relay graph splitting” and as we discussed, that seems like not
be self-contained, then I create this new RFC with subgraph runtime/executor support to make whole logic be self contained and review friendly.
we also have some discussion about integrate subgraph into BYOC to avoid redundant code, integrate into BYOC is convenience for these backend
that use BYOC mechanism, but such pipeline logic would not available for these backend that not go through BYOC, for example VTA, for such reason, hence we keep the subgraph split logic as a independent function to make this pipeline feature both available for BYOC backend and non-BYOC backend.
Motivation for subgraph pipeline
currently a lot of edge device use for inference is SOC, the idea scenario is we can use multiple chipset for compute together and parallel, one existing solution is to do batch processing on different chipset, for example processing image1 on cpu, image2 on gpu, image3 on FPGA,
but one issue is different chipset have different latency , slow chipset like cpu may be 10+ time slow then fast chipset like FPGA, when use whole compute graph as a schedule unit would involve huge latency for processing even we may get a better throughput. hence we need smaller schedule unit like subgraph as the schedule unit to more efficient to use SOC heterogenous hardware resource and reach better performance.
another benefit of subgraph pipeline is to provide the capability to use more backend parallel for inference, with the RPC help the backend
joined into the subgraph pipeline can even locate remotely on cloud.
in our use case we start to think about subgraph pipeline feature when we cooperate with autoware to use VTA as opensource vision control unit solution on ultra96 board, that time we experience performance issue on image processing throughput, VTA use CPU to process first conv layer and FPGA+CPU for other layer, when CPU is doing first layer processing, the FPGA actually is IDLE, then we give try to split the subgraph into 2 part and doing pipe line, we get about 30% + performance improvement without any hardware change.
Background and Prior Work
This subgraph runtime/executor relies on graph_executor for operator execution and storage set up, it is one more wrap up graph_executor,
Goals&Scope
The goal of this new framework&runtime is to provide a solution for such requirement to get performance improvement by doing operator/subgraph level scheduling. In this initial version, what we developed include
#1. a function to split compute grah
#2. a tiny runtime/executor,
Some features may useful but not available in this version are
#1. the subgraph split logic coming from user define, the automatic split logic generating or optimizing not there yet
#2. There is no CPU affinity configuration for these threads that running Pipeline control logic in this version
Architecture of solution
In this RFC and PR, we split our work into 3 parts, from top to down is as following
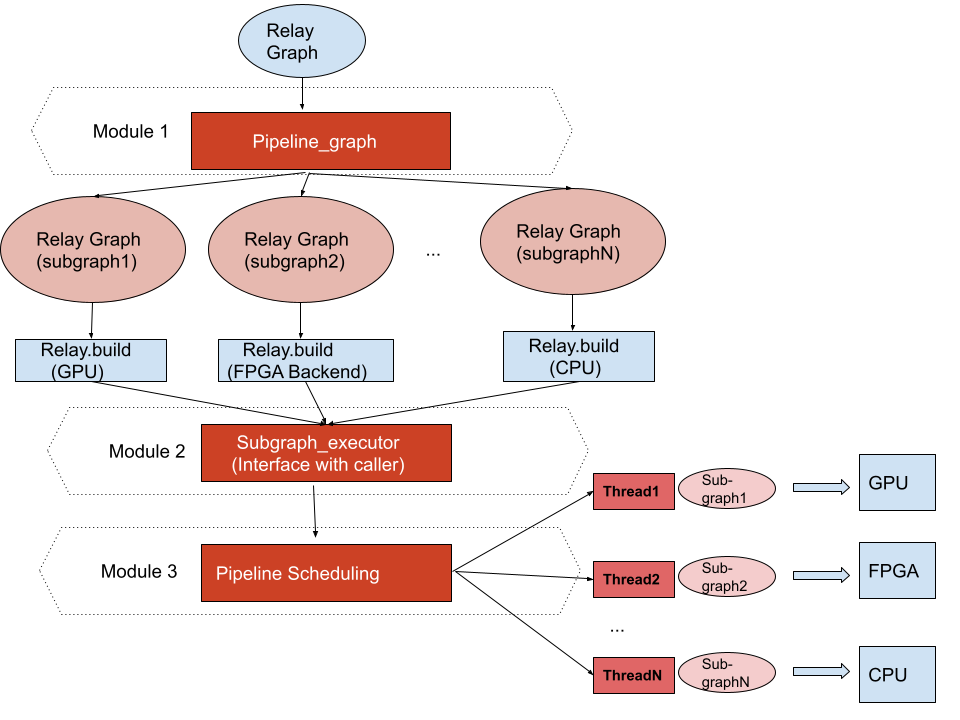
Module 1: Relay graph split logic Analysis.py:Pipeline_graph
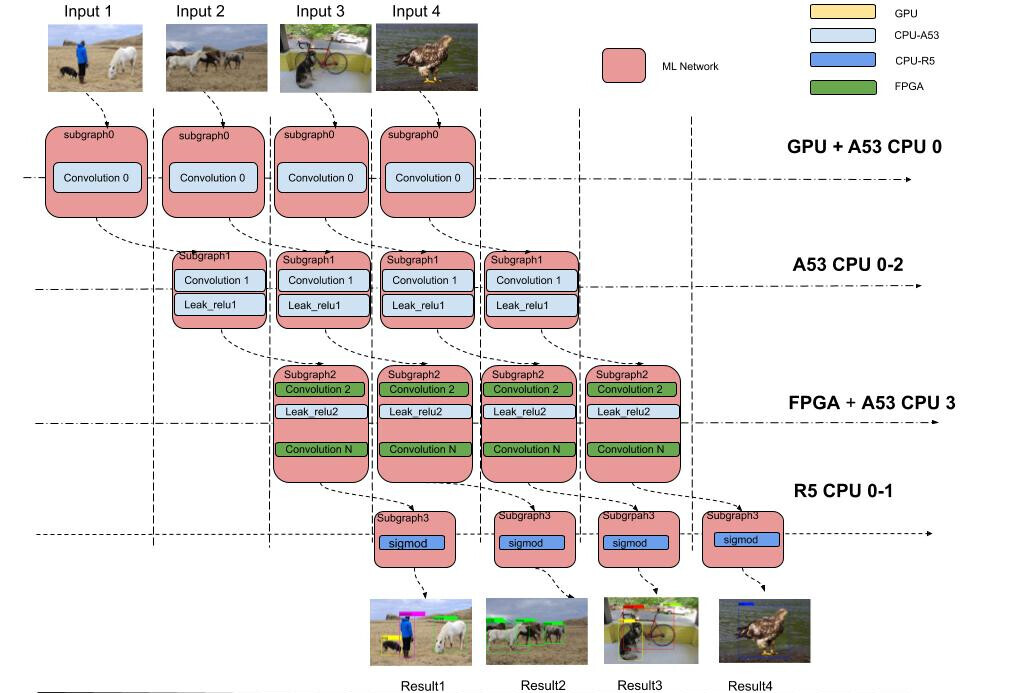
Function of module 1 is to split relay graph into a group of relay subgraph, following is an example for a simple network split
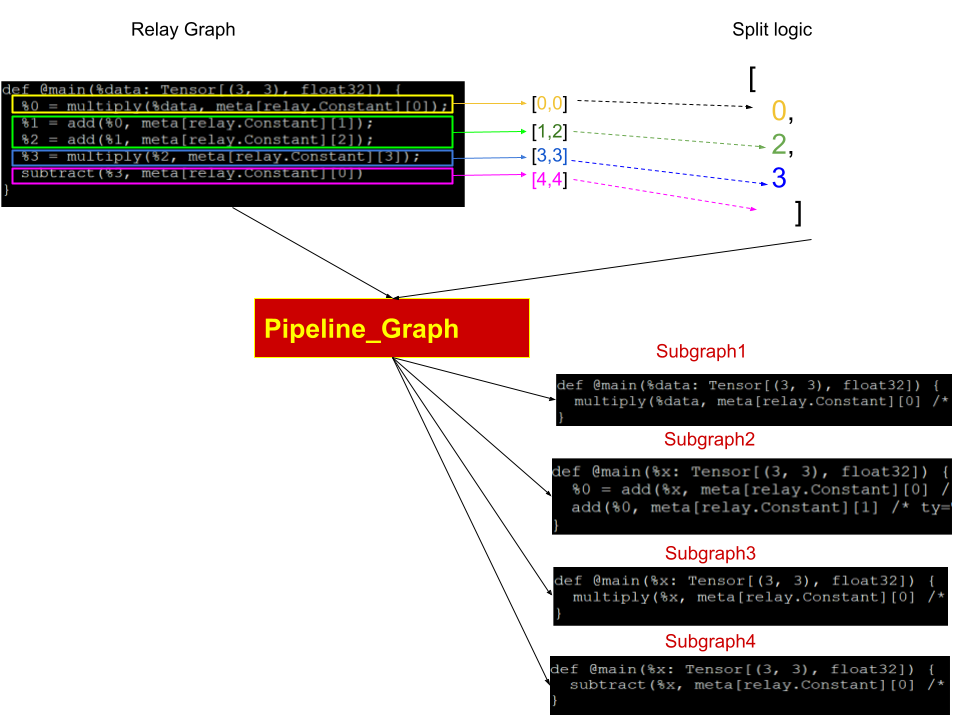
there are 2 input for this function No1 “Relay graph”, No 2 “Split array” , the output is Array of “module”, this function did 2 mainly work, first is to split one relay expression into multiple independent
expression, secondly rebuild the meta data reference to make sure new expression can find meta correctly. the detailed logic can get find in pipeline_graph function.
Module 2: Subgraph runtime/executor[Interface]
After split a Relay graph into a group of subgraph, user can build these subgraph with any backend they prefer, then subgraph runtime would do the job to scheduling these module/library in
pipeline model.
Subgraph runtime can get split into 2 module, One is the interface part that response to interact with caller to set data/parameter/modules that need to get schedule and doing the initialization/
run/stop work, Second part is the scheduling logic that response to pipeline the subgraph and transfer data between different subgraph, here we only talking about the Interface part.
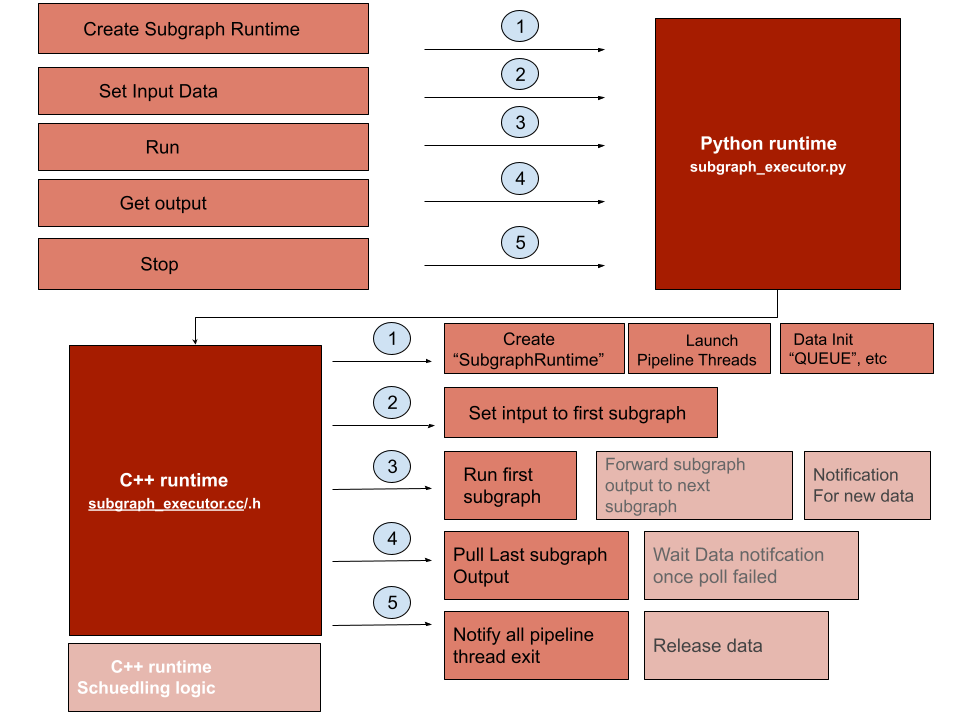
Subgraph runtime[Interface], have 3 files subgraph_executor.py, subgraph_executor.cc , subgraph_executor.h,
subgraph_executor.py is first interface that use to receive data and parameters for subgraph_runtime creation, internally it calling Cython function that exposed by subgraph_executor.cc/.h to create “SubGraphRuntime” instance in c++ part, then go through these functions like “SetInput”, “GetOutput” that provided by “SubGraphRuntime” to set input and get output from C++ part(subgraph_executor.cc/.h).
Another work did in subgraph_executor.py is that it would reate “graph_executor” module for every subgraph module, then the “module” information of “graph_executor” would send into c++ part as
the scheduling unit for pipeline logic
subgraph_executor.cc/.h is the c++ part logic that interact with both caller and lower level scheduling logic, there is a class named “SubGraphRuntime” that use to do control level scheduling logic,
like run/stop etc, it also provide the storage service to storage variable that use for scheduling work.
What this part logic did as following
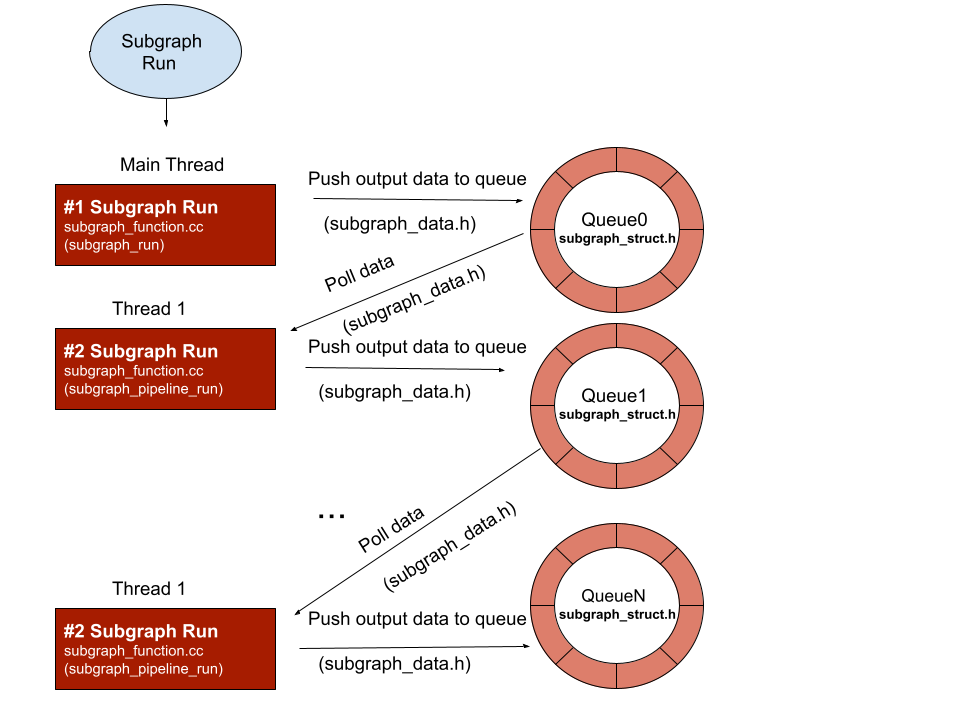
Module 3: Subgraph runtime/executor[Scheduling logic]
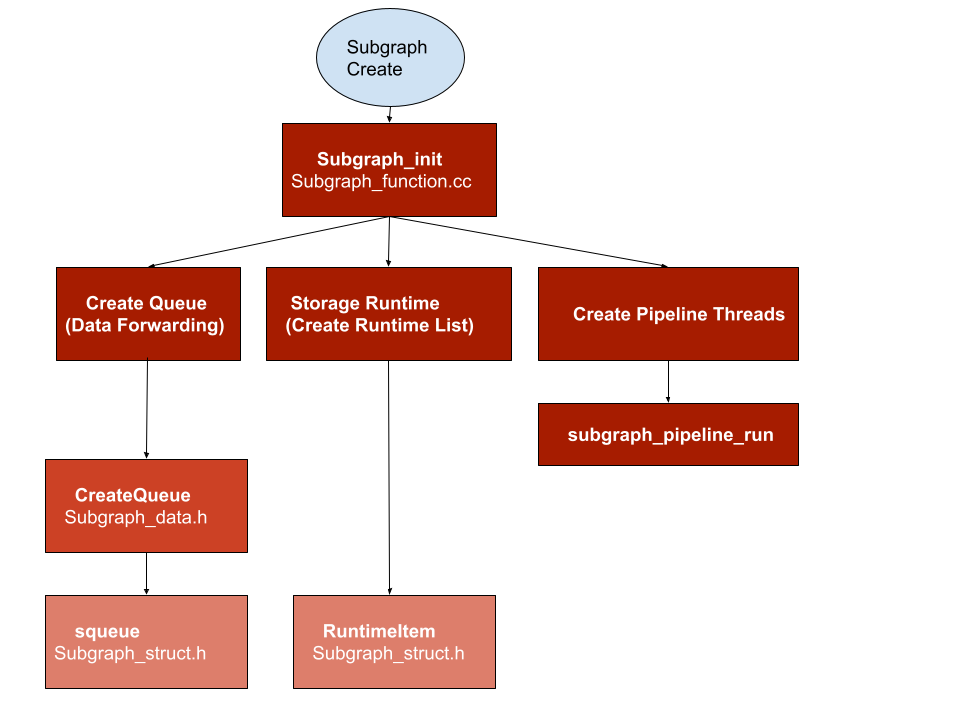
Scheduling logic consist of four files, “subgraph_function.cc/.h”, “subgraph_data.h”, “subgraph_struct.h” this modules doing following work.
#1. Maintain a pipeline thread pool
#2. data forwarding between different subgraph
#3. cross device data copy
#4. set input data for different subgraph
#5. polling output data
#6. synchronization logic for data arrive notification
Following are some diagram how these files cooperate
Subgraph create
Subgraph run