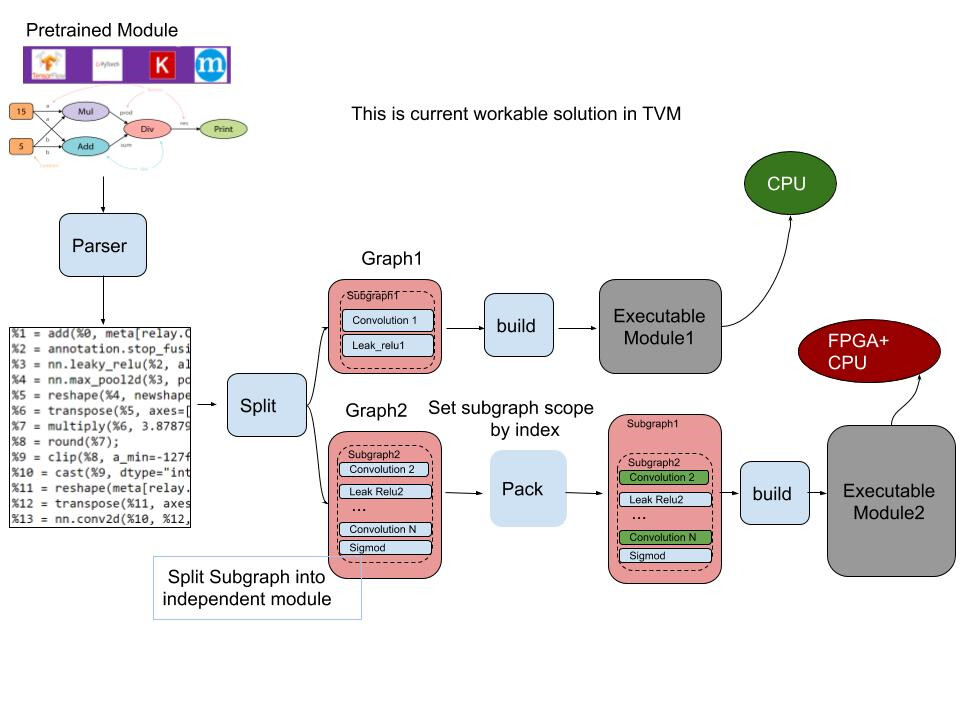
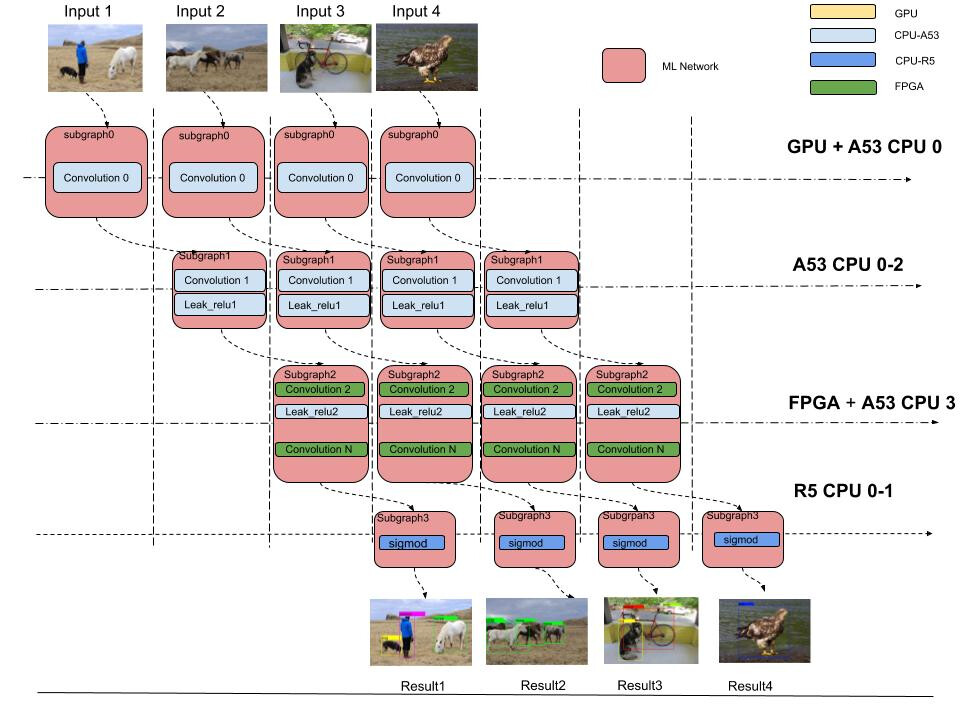
SOC hardware normally include multiple heterogeneous chipset, for example Xilinx Ultra96 board include Mali Gpu, Ultrascale+ Fpga, Arm A53, and Arm R5, currently TVM solution can support Heterogeneous hardware running in serialize, but to reach best performance, we need
a solution to parallel run a compute graph in multiple Heterogeneous hardware.
From this post I can only see a high-level overview and a PR for the first path, which includes a pass that partitions a graph to several submodules with Let binding. However, I have no idea how will you achieve graph pipelining with this graph. It would be better if you could provide more details, such as what the final implementation looks like, and how the runtime execute this graph in pipeline fashion.
Most customized hardware currently integrated via BYOC, which already has a mechanism to partition (or “split” in your word) the graph. It seems to me that the pass you implemented is incompatible to existing BYOC flow. I believe it would be a lot easier if you build the graph pipeline mechanism on the top of BYOC, so that we can guarantee the compatibility and save many redundant efforts.
@comaniac , thanks for the great question, following are my comments.
#1. about pipeline implementation , currently solution rely on external graph scheduler to do such pipeline work, in this case
TVM would get treat as a ML library that can do the subgraph computation, then the third party scheduler would do the
subgraph schedule, this pipeline pass provided the possibility for user do the subgraph pipeline work with TVM output,
because currently TVM have no such mechanism to do operator/subgraph level schedule.
#2. about the compatible with BYOC, actually this pass is a best use case for BYOC, currently BYOC fixed the problem how to
offloading operator into accelerator hardware, but because in TVM level there is no an operator/subgraph level scheduler, after
BYOC, user still can not fully/parallel use the hardware resource, after this Pipeline pass, user can mix use pipeline_graph and
BYOC to get subgraph with operator offloading to give the user capability to pipeline subgraph.
Based on your clarification, could you provide a few examples of the transformed Relay graph? It would be even better if you could include an example of mixing BYOC and graph pipeline, so that the discussion could be based on the example and could be more efficient.
Also, of course you could allow users to bring their own graph scheduler (a.k.a. runtime), but if we want to have this feature in the upstream, it would be better to have corresponding runtime support by default to make sure this feature is self-contained.
Finally, again please provide the complete upstream plan, including all the PRs you plan to file and their functions. It’s hard to review a single PR without knowing the whole picture.
about solution whole picture, these feature would totally include 2 patches, these two patch
can help user to implement a subgraph pipeline, but there is no dependency each other.
#1. pipeline_graph , split the compute graph into a group of subgraph
#2. TVM runtime cpu affinity setting, restrict how many cpu resource available for a particular
Tvm run time.
in this solution we not target to involve a subgraph scheduler/ runtime into TVM, the reason
Is that current TVM architecture not designed for multiple backend parallel and operator level or
Subgraph level schedule, we try to find a clean way not change TVM too much to introduce subgraph pipeline at initial.
About how the pipeline_graph pass work following is a example in the said PR
in our use case we use this pass to generate subgraph for pipeline, we also think this is the biggest
benefit of such pass, but this pass itself only focus on compute graph splitting and not rely on any pipeline
schedule feature, hence it is already be self-contained.
Thanks for the proposal. I feel this is more like a file/pass that you can direct use for your deployment since the scheduler and the runtime are actually not part of the RFC. It sounds not quite general to the codebase though.
Hello,
I made the mistake to review the PR first, and then I found this discussion
So what I understood from the PR (but then I got a bit confused by the terminology in this post) is that you are trying to split your graph so that it can use the hardware resources in a less greedy way then pure BYOC.
So with BYOC you split your graph to use the accelerator (e.g., the FPGA) as much as you can. In theory, if the graph can be entirely offloaded to the accelerator, this is what will happen.
Instead, you are trying to horizontally split your graph in a sort of of pipeline, so that you can always use free resources. For instance if you have a graph A->B->C and two images I1 and I2, you split A->B and C (for instance). So that A->B (for I2) can be offloaded to the CPU if the accelerator is still busy processing C for I1.
Is this what you are trying to achieve?
If so, maybe I would suggest add also your second PR to the one already published, so that we can understand how everything works together.
Also, how do achieve the optimal split? Basically, how do you pick your indices when you try to split your graph?
@zhiics , thanks for the comments, about the scheduler/runtime, we do have a plan to upstream such part, it can work like same
way what graph_runtime did, following is a example.
from tvm.contrib import sub_graph_runtime
#…
pl = [1, 2]
mods = pipeline_graph(mod[“main”], pl)
graphs, libs, params, ctxs = build_module(mods) // use different backend to build the subgraph
@giuseros , thanks for the comments and review, the goal of solution like you mention is to more high efficient
to use compute resource in SOC, for example when FPGA is busy and cpu/gpu is idle, we can use cpu/gpu to handle
some subgraph in pipeline, I can understand that this PR may cause confuse without the runtime part, I would set it
as WIP and add the runtime part soon.
about the subgraph split, at this initial solution that coming from manually config, but we do
have a plan to involve auto tuning in following solution to automatic such work.
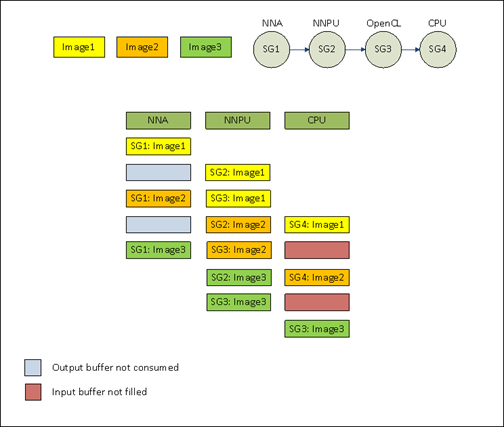
At Imagination Technologies we have implemented pipelined execution in Graph Runtime. This allows TVM runtime to infer a single network multiple times. Memory is shared between inferences. We have a heterogeneous platform with 4 devices accelerator (nna), compute (nnpu), GPU and a CPU. TVM compiler partitions the network based on capabilities of these devices and Graph Runtime executes them in a pipelined manner. This allows parallel execution of certain sections of the network. As the number of devices are known, we have created execution queues for each device using software threads. The runtime pushes a node (packed-function) in the execution queue based on availability of input buffer and the device.
Hi Jake, we haven’t started upstreaming of pipelined execution yet, but our aim is to push everything that we have implemented on top of ToT. I don’t have dates at this moment, however I can discuss more about how we have implemented it with you.