Summary
Integrate Marvell’s Machine Learning Inference Processor (MLIP) with TVM BYOC framework to bring the TVM ecosystem to Marvell customers. This preRFC deprecates this previous preRFC thread [pre-RFC][BYOC] Marvell ML/AI Accelerator Integration as this is a refreshed and simplified version.
Motivation
Marvell MLIP is an ML/AI inference accelerator and is embedded on our ARM Neoverse N2-based OCTEON family of processors: Data Processing Units (DPU) | Empowering 5G Carrier, Enterprise and Cloud Data Services - Marvell. We are building an easy-to-use, open, software suite for our customers by integrating and utilizing TVM so that we can bring TVM capability and experience to our customers.
Proposal
The Marvell ML (Machine Learning) Inference Processor is optimized for inference, so must be given a pre-trained network model and applied to a TVM-Marvell-BYOC compilation and code-gen flow as illustrated and explained below. This framework consists of three components Partitioner, Codegen and Runtime.
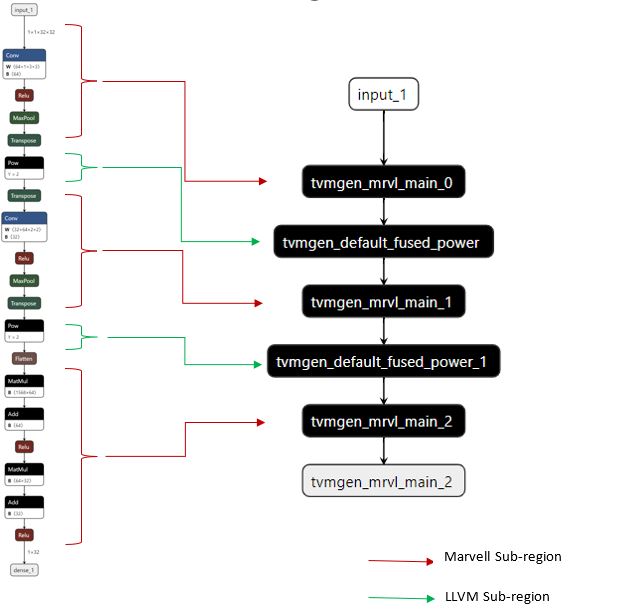
The TVM BYOC framework generates the IR for the given pre-trained network model and calls into the partitioner components in the Marvell BYOC framework.
Partitioner
The Marvell partitioner utilizes TVM’s partitioning infrastructure and greedily identifies the regions and operators in the model that can be supported by Marvell MLIP. We use the standard BYOC approach as outlined here: https://tvm.apache.org/2020/07/15/how-to-bring-your-own-codegen-to-tvm, using the Annotate, Partition, and Merge Compiler Region passes. For the first version, we plan to support the following operators for the Marvell BYOC backend:
Operators :
- Conv2d
- FC
- Max_pool2d
- Avg_pool2d
- Global_avg_pool2d
- Sum(add)
- Concatenate
Fused Ops/Activations :
- Pad
- Relu
- Batch_norm
We will be adding further operator support in phases once the initial implementation is complete.
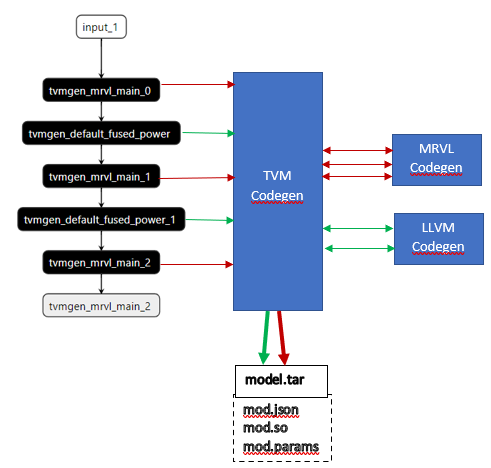
Code generator
For each of the partitioned Marvell regions, annotated as “tvmgen_mrvl_main_*”, TVM calls into the Marvell BYOC codegen with details of that layer/node/operators. Each of the regions are serialized to generate a JSON graph representation that is understood by the Marvell Machine Learning Compiler(mmlc). The MLIP ISA machine instructions are created by running the mmlc compiler on the JSON graph and the generated binary is embedded into the runtime generated by TVM.
Similarly for the compiler regions annotated as “default” (which cannot be supported by the Marvell backend), TVM consults the LLVM codegen to generate the code which can be run on the ARM Neoverse Cores.
For a hybrid graph, multiple regions can be executed and stitched together seamlessly with the TVM runtime.
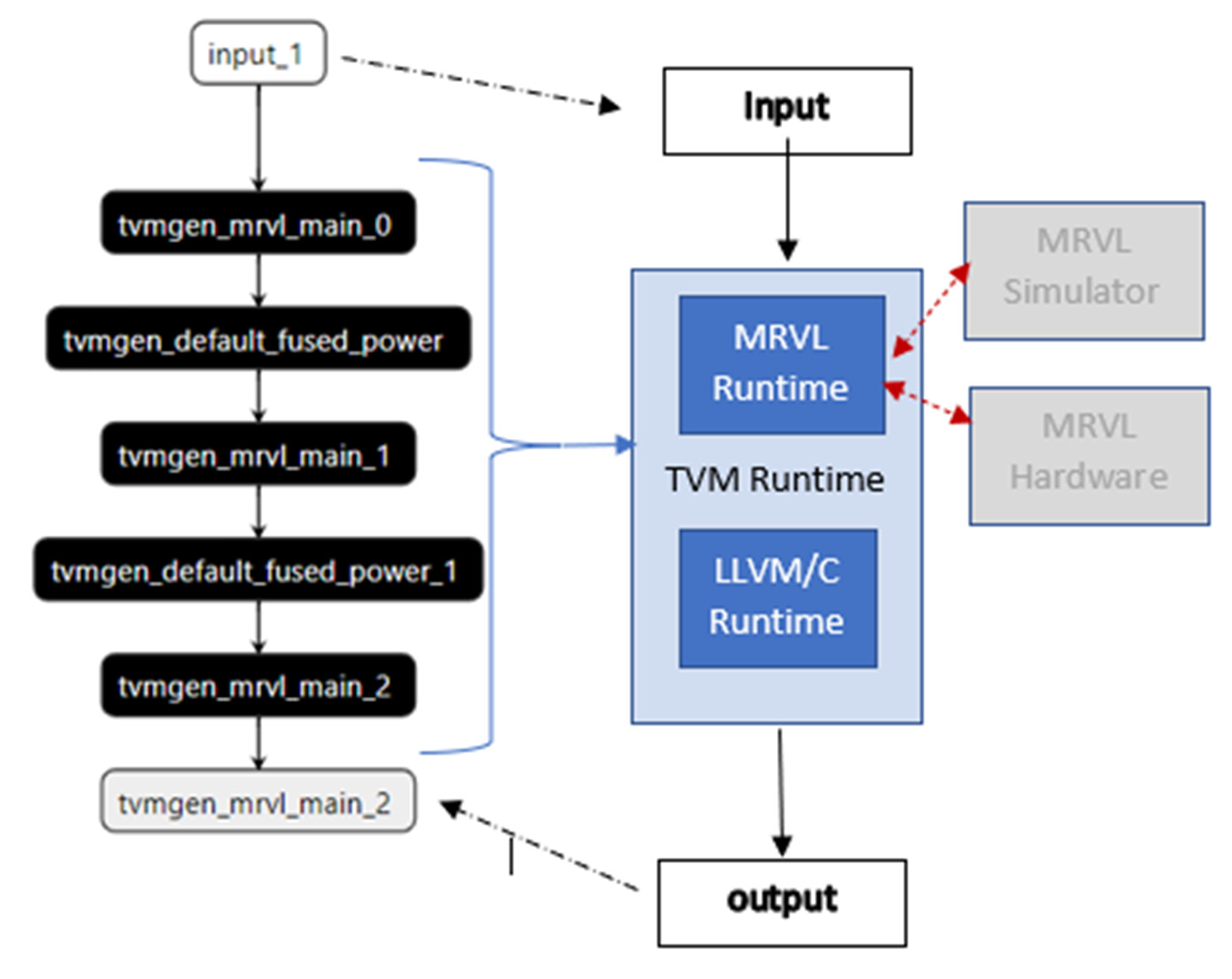
Runtime
The runtime consists of two flavors, a simulator runtime and hardware runtime. The hardware runtime is for the users who have access to Marvell hardware, such as the CN106 (Data Processing Units (DPU) | Empowering 5G Carrier, Enterprise and Cloud Data Services - Marvell) . For users without access to the Marvell hardware but requiring the functionality of compiling and running a model, the simulator runtime is provided. It provides a functional, bit-accurate experience without the presence of hardware.
Phasing
To ease the submission and code review process, we plan to roll out the initial support in phases:
- Phase 1 – Partitioning and Code Generation Support: We will be adding the BYOC infrastructure necessary to partition the graph to Marvell and LLVM regions and generate a serialized JSON representation suitable for the Marvell mmlc compiler.
- Phase 2 – Software Runtime Support: We will be adding support for the software simulator runtime which will allow users without the hardware to experiment with different models and understand performance implications. We will be supporting fp16 compilation only.
- Phase 3 - Hardware Runtime Support & int8 PTQ flow: We will be adding support for our hardware runtime in this phase to allow users to run inference on the hardware. Also, we will be introducing our Post Training Quantization flow, which will allow users to perform data aware calibration and quantize fp32 models to int8 for execution on the hardware.
Testing
For Phase 1, we will be adding basic tests for partitioning Relay Graphs for the BYOC backend like other backends which do not have hardware support readily available.
For Phase 2 & Phase 3, we will work with the community to enable end to end tests running on both the software and hardware runtimes with standard models.