Summary
Integrate Marvell’s ML/AI accelerator with TVM BYOC framework in order to bring the TVM ecosystem to Marvell customers.
Motivation
Marvell MLIP is an ML/AI inference accelerator and is embedded on our ARM Neoverse N2-based OCTEON 10 processor. We are building an easy-to-use, open, software suite for our customers by integrating and utilizing TVM so that we can bring TVM capability and experience to our customers.
Proposal
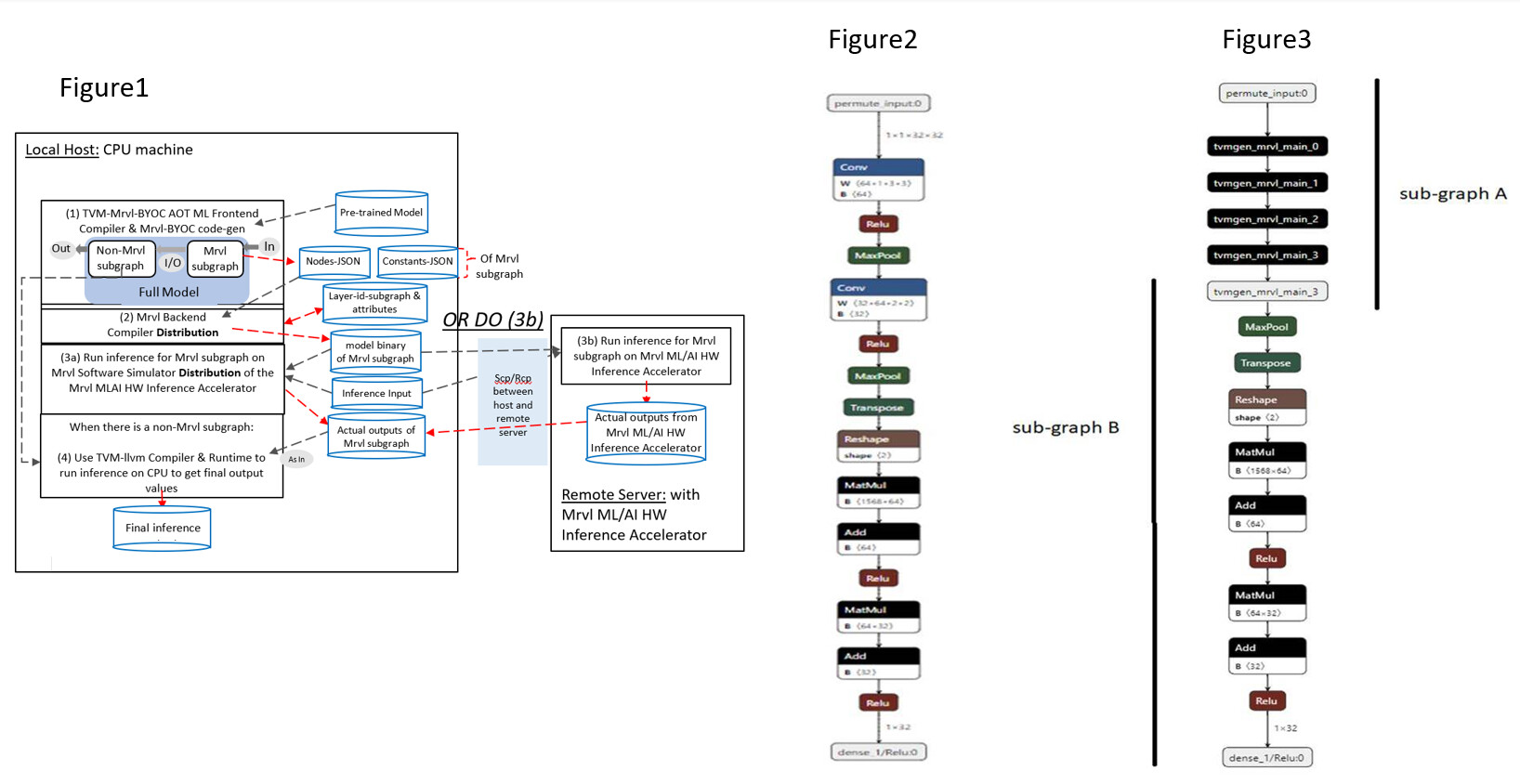
Based on what Marvell ML/AI inference accelerator does the best, a given pre-trained network model will be applied to a TVM-Mrvl-BYOC AOT compilation and code-gen flow as illustrated in Figure 1 below.
Figure 1: Overall Framework and Steps (see figures at end)
- Follow the TVM BYOC framework and then
- STEP (1) Run TVM-Mrvl-BYOC AOT ML Frontend Compilation and Mrvl-BYOC code-gen. The steps involved in this are:
- Load pre-trained network (see Figure 1 above and sample Figure 2 below) into TVM IR graph
- Do Marvell-specific layout conversions to transform IR graph in order to meet requirements of the accelerator
- Do Marvell-specific composite-merging/fusing to transform IR graph in order to utilize available HW capability in the accelerator
- Do additional Marvell-specific transform pass(es) to further optimize IR graph
- Partition IR graph into one or more for-accelerator Mrvl subgraphs and/or one or more for-TVM-target non-Mrvl (e.g., ARMv9) subgraphs
- These subgraphs cover the whole pre-trained network
- For-accelerator Mrvl subgraph here means & contains connected, composite-fused Call nodes (see sample Figure 3 – sub-graph A) as in the given IR graph
- For the first Marvell-BYOC revision, at most one for-accelerator Mrvl subgraph and at most one for-TVM-target non-Mrvl subgraph (see sample Figure 2 – sub-graph B) can be identified; plus, the for-accelerator Mrvl subgraph can only use input tensor(s) of given pre-trained network as its subgraph’s input tensors
- Do code-gen step for each for-accelerator Mrvl subgraph:
- Marvell-BYOC-specific attributes are introduced for each composite-merged/fused Call node (see sample Figure 3 – tvmgen_mrvl_main_0 to tvmgen_mrvl_main_3) so that a Nodes-JSON file and a Constants-JSON file are produced (see output JSON files being generated in STEP 1 of Figure 1 above).
- STEP (2) Run Mrvl-ML/AI Backend Compiler to generate model binary for each Mrvl subgraph
- The Mrvl-ML/AI backend compiler will be distributed as an executable in the OCTEON SDK; and it can be used to read in Nodes-JSON and Constants-JSON files of each Mrvl subgraph as input meta-data in order to generate final instructions, in model binary file as illustrated in Figure 1.
- Note: Mrvl-ML/AI backend compiler, which does accelerator-specific optimization and code generation, is not included to upstream
- STEP (3a) or (3b) Run inference on the software Simulator or on the Mrvl ML/AI HW accelerator for the Mrvl subgraph
- The Mrvl Software Simulator of the Mrvl ML/AI HW accelerator will be distributed as an executable in a Mrvl-ML/AI tar ball; and it can be used to read in input file(s) and the model binary to run inference for the Mrvl subgraph
- Note: Mrvl ML/AI accelerator can run inference in either float16 mode or int8 quantization mode. For this RFC, we will focus only on float16 inference run
- STEP (4) Use TVM-llvm Compiler & Runtime to run inference
- Perform integration steps between sub-graph(s) in order to run inference for the given pre-trained network
- For the first Marvell-BYOC revision, at most one integration step from a for-accelerator Mrvl subgraph to a TVM-target non-Mrvl subgraph is implemented
Figure 2: Sample given, pre-trained network (see figures at end)
Figure 3: Sample for-accelerator Mrvl subgraph A, and for TVM-target non-Mrvl subgraph B (see figures at end)
Status w.r.t. Outlines of Marvell-BYOC Implementation & Verification
The status of our initial POC implementation is the following:
- [POC ready] Cmake related changes for Marvell-BYOC code
- [POC ready] Main Marvell-BYOC entrance APIs in tvm/python/tvm/relay/op/contrib/mrvl.py and files under the tvm/src/relay/backend/contrib/mrvl/ folder including code to:
- Do IR transformations and optimizations
- Identify Sub-graphs
- Do code-gen for Marvell-ML/AI-specific nodes-JSON and constants-JSON files
- [POC ready] tvm/tests/python/contrib/test_marvell
- Add test MxNet ssd_resnet50, which uses Marvell-BYOC APIs to do code-gen for Nodes-JSON and Constants-JSON files
- Add verification utilities to ensure expected JSON files are produced
- For the Keras mobilenet_v2 test case, we notice that the relay from_keras() function does not support input tensor in NCHW format
- Note: Currently, for the current POC Mrvl-BYOC codebase, we only support input tensor in NCHW format
- We have installed and run local TVM Jenkins build & tests utilizing modified tvm/Jenkinsfile and scripts. We are running into a few minor issues where some test cases failed in the Python3:CPU and Python3:i386 stages. Most of them do not seem to directly relate to our Mrvl-BYOC changes but we are currently using pytest.mark.skipif(True) to skip them.
- [12/13/2021] We have finalized our POC code changes and up-streamed as TVM github “PR-9730 [pre-RFC][BYOC] Marvell ML/AI Accelerator Integration” for the TVM community to review and run Jenkins build & tests.
Resolved/Pending PRs and/or questions – please refer to our initial POC TVM “PR-9730 [pre-RFC][BYOC] Marvell ML/AI Accelerator Integration”
- We have provided our pooling-related changes in PR-9235 to the TVM community, title [Op] Do not override specified layout in pooling. In this PR, user can use the new out_layout field of pooling to specify a format, which relay will take & stick to this user-specified format for pooling op. When the out_layout field of pooling is not specified, the original, relay-auto-provided infer format will take place for pooling.
- We have also identified a need to allow a call-back function to be registered when generating Mrvl-BYOC-specific Nodes-JSON file. We are trying to follow TVM Python/CPP-CB style as much as possible. But, since our callback function tvm/src/relay/backend/contrib/mrvl/graph_executor_codegen_mrvl.cc::GetExternalJSON() function is using non-simple argument types, we need help from TVM community to provide suggestions/guidelines in order to make new CB code better to meet TVM community requirements here.
- For one Mrvl-BYOC relay transformation pass, we have identified a need to inject a (global) expr node ID for the RelayExprNode class and its derived classes: Tuple and CallNode, so that during the transformation pass, we can uniquely identify each Tuple or CallNode object. Again, we need help from TVM community to provide suggestions/guidelines here in order to know whether this is one of the best ways to achieve the Mrvl-BYOC need.
- We also identified a need to maintain linkages between (operator-)information described in the original, given pre-trained network model and the code-gen JSON files so that the compiler backend will be able to report user-level (e.g., meaningful-to-user) messages regarding the given pre-trained network. For instance, in the tvm/python/tvm/relay/frontend/onnx.py and common.py files, we can see user-level information being captured using “tvm_custom” related code as in original onnx.py file for the given pre-trained network; but, in common.py, the code later drops the linkage, via attrs.pop(“tvm_custom”), and does not pass the linkage onto the initial relay IR graph. We have a draft solution to maintain linkages between the given pre-trained network model and its relay IR graph (using expr node ID and tvm custom ID, plus, a few utility functions), but would like to know whether the TVM community has any better or work-in-progress resolution.
- We ran into one minor issue and have made enhancement so that, when using TVM RPC code, it is useful for the RPC client to send a file to the remote server and to know where the remote server saves the file on the remote machine. Since this is not directly related to this Mrvl-BYOC PR, we will find time to contribute this enhance back in another TVM PR soon.
- In order for us to generate the constants-JSON file, we must “NOT” remove external params, which were stored in metadata module, in the BuildRelay() function defined in the tvm/src/relay/backend/build_module.cc file. Currently, we are using the CPP directive: #ifndef TVM_USE_MRVL to achieve the not-removal requirement for the Mrvl-BYOC flow when config.cmake has USE_MRVL ON. We are not sure whether there are side effects due to not removing external params in the BuildRelay() function. Are there any other (better) resolution regarding this matter?
- We also wonder whether this tests/python/relay/test_external_codegen.py test suite’s test case, test_load_params_with_constants_in_ext_codegen(), needs to be pytest.mark.skipif( True if USE_MRVL is ON)?
- We are also working on a Mrvl Bring-You-Own-Quantization-Int8 flow under the tvm/python/tvm/relay/quantize/contrib/mrvl folder. When we have a solid POC codebase, we will start to communicate with the TVM Community.
- Since we are new to the TVM community, please let us know whether and when we should also upstream our POC implementation as a TVM github PR so that we can explain our descriptions above more clearly by pointing to specific POC code file(s) and examples in discussions.
Figures: