Background
We currently have two major schedulers for TensorIR: Meta Schedule and Dlight. MetaSchedule offers high performance but typically requires hours to devise an optimal schedule plan; Dlight provides some general schedule templates (e.g. gemv, matmul, reduce) but the performance is limited by manually-set schedule configuration (e.g. tile size) .
This topic is an improvement of dlight, instead of relying on manually-set schedule configuration, we leveraged hardware information to recommend top k (typically 20) config candidates, then we can traverse the top k candidates and find the best. This method not only significantly reduces the time to generate a high-performance kernel to mere seconds but can also achieve comparable performance to Meta Schedule if the schedule template is efficient enough.
The general idea of leveraging hardware information comes from OSDI 22’ Roller. Given my understanding of this paper and its implementation, the key concept is: one high performance schedule config also utilize the memory system effectively.
We learn and enhance roller’s implementation, This is generally an improved tensor ir re-implementation of Roller.
Optimization Steps.
Using a basic CUDA core matrix multiplication on NVIDIA GPUs as an example, the optimization process typically involves the following steps:
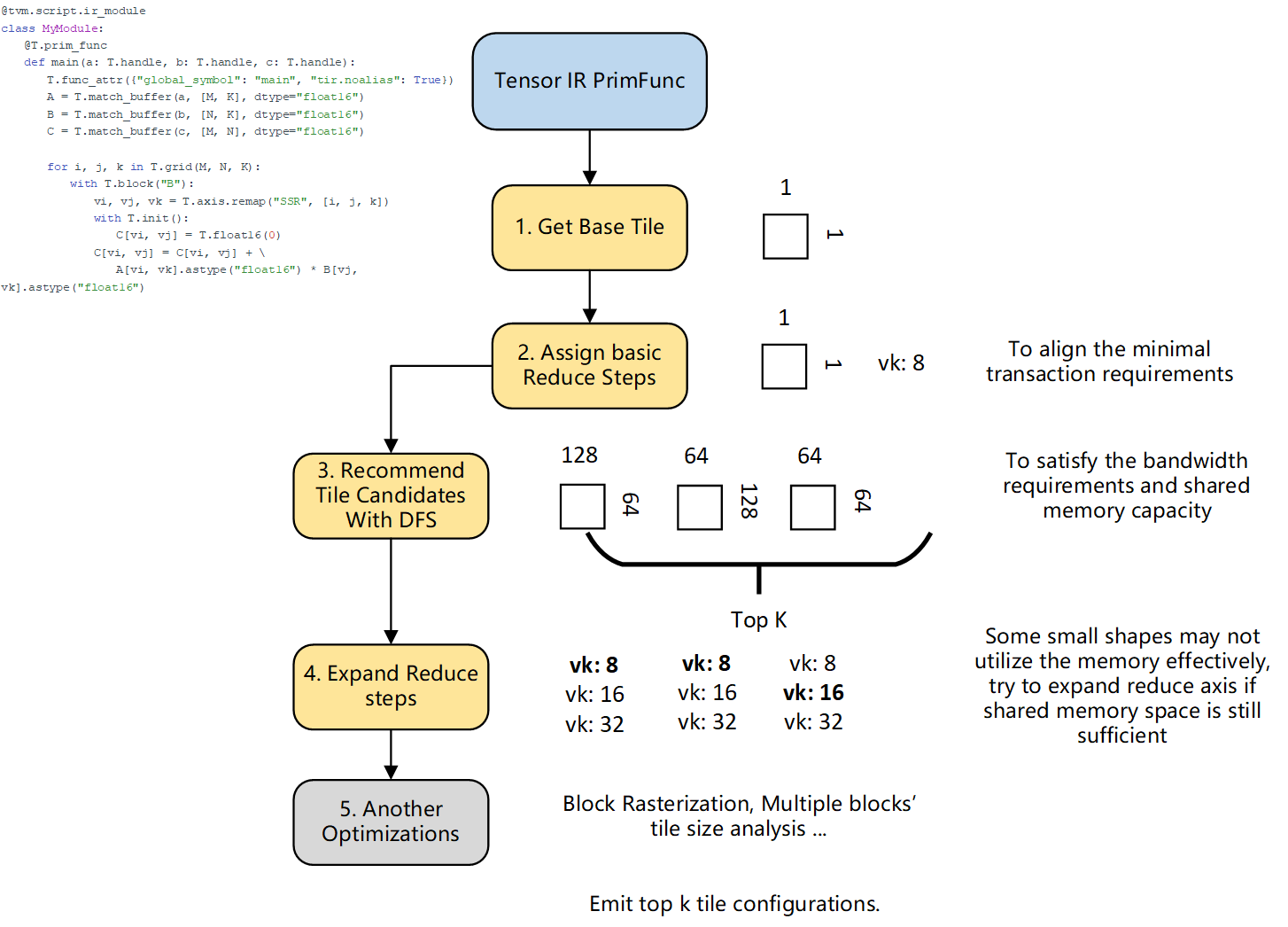
How to use
- Tune with Default policy:
func = ir_module["main"]
target = tvm.target.Target("nvidia/nvidia-a100")
arch = CUDA(target)
policy = DefaultPolicy(func=func, arch=arch)
configs = policy.emit_config(20)
cpresults, best = apply_and_build(func, configs, arch, parallel_build=True)
- Tune with Tensor Core Policy
func = ir_module["main"]
target = tvm.target.Target("nvidia/nvidia-a100")
arch = CUDA(target)
policy = TensorCorePolicy(
func=func,
arch=arch,
tags={
"tensorcore_config": [0, 1],
"pipeline_stage": 2,
"use_async_copy": 1,
},
)
configs = policy.emit_config(20)
cpresults, best = apply_and_build(func, configs, arch, parallel_build=True)
- Auto normalize tensor core func and tags
func = ir_module["main"]
target = tvm.target.Target("nvidia/nvidia-a100")
arch = CUDA(target)
policy = DefaultPolicy(func=func, arch=arch)
try:
func, tags = get_tensorized_func_and_tags(func, arch.target)
except:
tags = None
if tags:
policy = TensorCorePolicy(func=func, arch=arch, tags=tags)
configs = policy.emit_config(20)
cpresults, best = apply_and_build(func, configs, arch, parallel_build=True)
- Tune End2End.
relax_mod = apply_opt_before_tuning(relay_mod, params, target)
relax_mod = dl.ApplyFastTuning(topk=20, target=target, parallel_build=True, meta_database_dir='./.tmp')(relax_mod)
- Reuse meta database
database = ms.database.JSONDatabase(
path_workload="./.tmp/database_workload.json",
path_tuning_record="./.tmp/database_tuning_record.json",
)
with database, target:
relax_mod = relax.transform.MetaScheduleApplyDatabase(enable_warning=True)(relax_mod)
Early Benchmark Result
Devices: A100 80G
CUDA: 12.1
| Operators | Arguments | FastDlight Top 20 Tune Time(s) | Top1 Latency (ms) | Top20 Latency (ms) | DefaultDLight Latency(ms) | speedup vs default |
|---|---|---|---|---|---|---|
| elementwise_copy | 128-8192-float16 | 2.547 | 0.01 | 0.005 | 0.006 | 1.2 |
| elementwise_copy | 16384-16384-float16 | 7.405 | 0.826 | 0.664 | 1.097 | 1.652108434 |
| elementwise_add | 16384-16384-float16 | 9.787 | 1.528 | 1.02 | 1.278 | 1.252941176 |
| reduce_sum | 16384-1024-float16 | 1.386 | 0.024 | 0.021 | 0.765 | 36.42857143 |
| reduce_max | 16384-1024-float16 | 1.085 | 0.023 | 0.022 | 0.766 | 34.81818182 |
| softmax | 128-10-float16 | 0.949 | 0.01 | 0.004 | 0.005 | 1.25 |
| matmul_nt | 1024-1024-1024-float16-float16 | 5.093708515 | 0.029 | 0.025 | 0.036 | 1.44 |
| matmul_nt | 8192-8192-8192-float16-float16 | 6.301071167 | 15.645 | 4.872 | 7.704 | 1.581280788 |
| matmul_nt | 16384-16384-16384-float16-float16 | 18.82274413 | 232.311 | 39.06 | 78.313 | 2.004941116 |
| matmul_nn | 1024-1024-1024-float16-float16 | 3.544429541 | 0.044 | 0.024 | 0.037 | 1.541666667 |
| matmul_nn | 8192-8192-8192-float16-float16 | 6.116118431 | 5.58 | 4.631 | 7.498 | 1.61908875 |
| matmul_nn | 16384-16384-16384-float16-float16 | 16.83759928 | 86.931 | 37.944 | 67.279 | 1.773113009 |
| matmul_nt | 1024-1024-1024-float32-float32 | 3.082 | 0.78 | 0.258 | 0.256 | 0.992248062 |
| matmul_nt | 8192-8192-8192-float32-float32 | 35.129 | 162.054 | 67.28 | 118.725 | 1.764640309 |
| matmul_nn | 1024-1024-1024-float32-float32 | 3.028 | 0.346 | 0.225 | 0.229 | 1.017777778 |
| matmul_nn | 8192-8192-8192-float32-float32 | 33.267 | 61.582 | 59.723 | 104.809 | 1.754918541 |
| conv2d_nhwc_hwio | 128-64-224-224-3-7-7-2-1-3-float16-float16 | 5.287 | 0.749 | 0.749 | 1.565 | 2.089452603 |
| conv2d_nhwc_hwio | 128-64-224-224-64-1-1-2-1-3-float16-float16 | 8.236 | 0.33 | 0.294 | 0.662 | 2.25170068 |
| conv2d_nhwc_hwio | 128-64-224-224-3-7-7-2-1-3-float32-float32 | 3.337 | 4.716 | 2.984 | 3.346 | 1.121313673 |
| gemv | 1-1024-1024-float16 | 1.275 | 0.011 | 0.005 | 0.006 | 1.2 |
| gemv | 1-8192-8192-float16 | 1.762 | 0.114 | 0.082 | 0.096 | 1.170731707 |
| gemv | 1-16384-16384-float16 | 3.649 | 0.36 | 0.304 | 0.345 | 1.134868421 |
| gemv_i4 | 1-16384-16384-float16 | 2.072 | 0.13 | 0.082 | 0.143 | 1.743902439 |
| Network | InputShape | Format | FastDlight TOP 20 Tune Time (s) | FastDlight Latency (ms) | DefaultDlight Latency (ms) |
|---|---|---|---|---|---|
| MLP | (128, 224, 224, 3) | float32 | 43.726 | 2.688503265 | 13.29352856 |
| MLP | (128, 224, 224, 3) | float16 | 29.25 | 1.77359581 | 3.119468689 |
| resnet-18 | (128, 224, 224, 3) | float32 | 298.521 | 34.41455364 | 48.52347374 |
| resnet-18 | (128, 224, 224, 3) | float16 | 226.363 | 5.837249756 | 25.78620911 |
to reproduce: mlc-benchmark/tir-roller at master · LeiWang1999/mlc-benchmark · GitHub