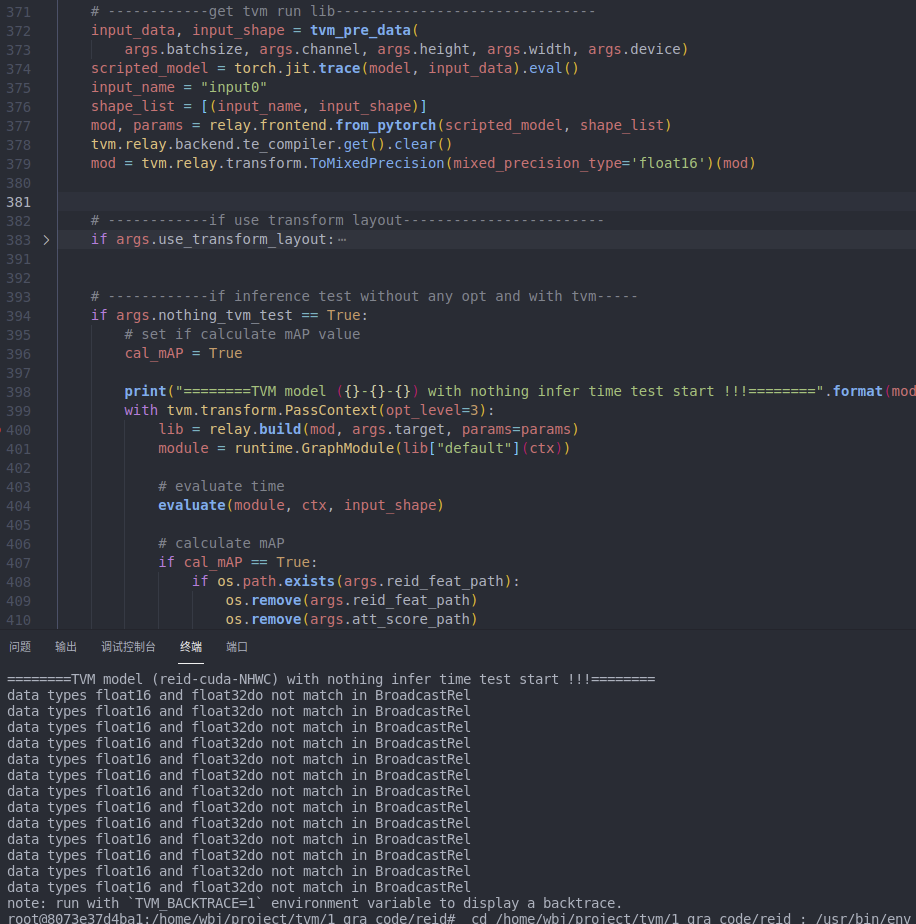
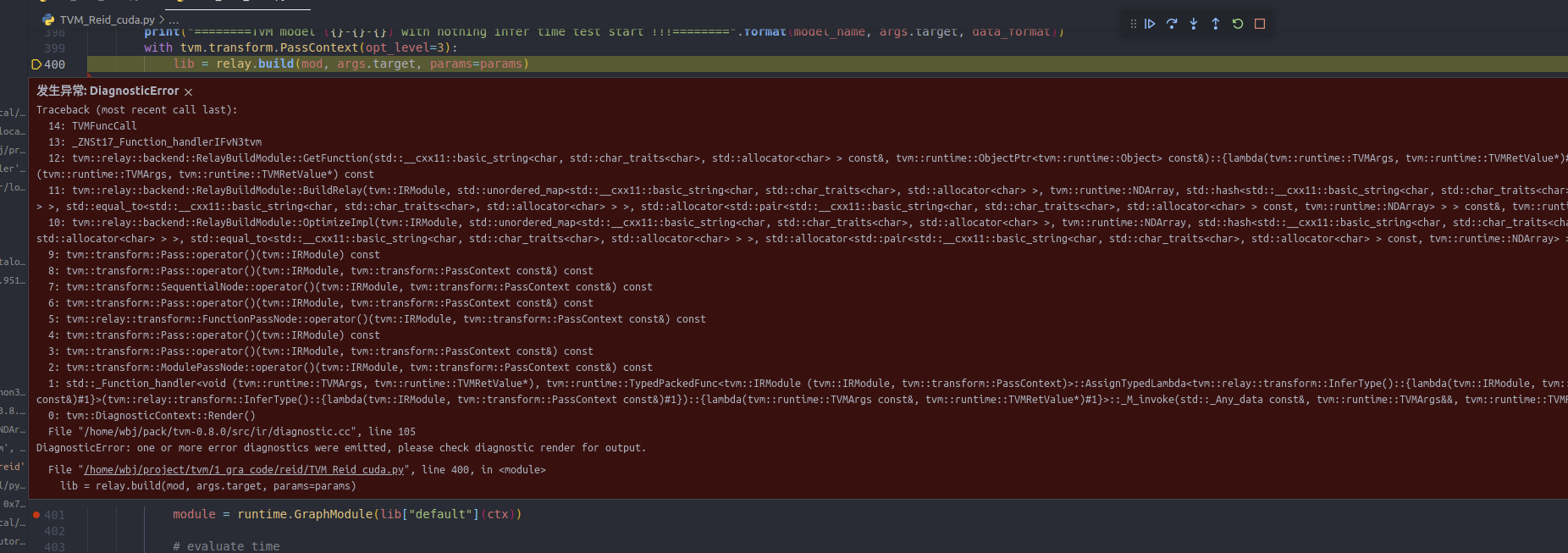
Yes, of course.I think it might be because of “InstanceNorm2d”, when I remove “InstanceNorm2d”, it works.After using fp16 precision, it is much faster than directly using “relay.quantize” to convert to int8, although they are not as fast as the original fp32.
import torch
import torch.nn as nn
from collections import namedtuple
import math
import torch.utils.model_zoo as model_zoo
__all__ = ['ResNet_IBN', 'resnet50_ibn_a']
model_urls = {
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
}
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class IBN(nn.Module):
def __init__(self, planes):
super(IBN, self).__init__()
half1 = int(planes / 2)
self.half = half1
half2 = planes - half1
self.IN = nn.InstanceNorm2d(half1, affine=True)
self.BN = nn.BatchNorm2d(half2)
def forward(self, x):
split = torch.split(x, self.half, 1)
out1 = self.IN(split[0].contiguous())
out2 = self.BN(split[1].contiguous())
out = torch.cat((out1, out2), 1)
return out
class Bottleneck_IBN(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, ibn=False, stride=1, downsample=None):
super(Bottleneck_IBN, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
if ibn:
self.bn1 = IBN(planes)
else:
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet_IBN(nn.Module):
def __init__(self, last_stride, block, layers, frozen_stages=-1, num_classes=1000):
scale = 64
self.inplanes = scale
super(ResNet_IBN, self).__init__()
self.conv1 = nn.Conv2d(3, scale, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(scale)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.frozen_stages = frozen_stages
self.layer1 = self._make_layer(block, scale, layers[0])
self.layer2 = self._make_layer(block, scale * 2, layers[1], stride=2)
self.layer3 = self._make_layer(block, scale * 4, layers[2], stride=2)
self.layer4 = self._make_layer(block, scale * 8, layers[3], stride=last_stride)
self.avgpool = nn.AvgPool2d(7)
self.fc = nn.Linear(scale * 8 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.InstanceNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(nn.Conv2d(self.inplanes, planes * block.expansion, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(planes * block.expansion),)
layers = []
ibn = True
if planes == 512:
ibn = False
layers.append(block(self.inplanes, planes, ibn, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes, ibn))
return nn.Sequential(*layers)
def _freeze_stages(self):
if self.frozen_stages >= 0:
self.bn1.eval()
for m in [self.conv1, self.bn1]:
for param in m.parameters():
param.requires_grad = False
for i in range(1, self.frozen_stages + 1):
m = getattr(self, 'layer{}'.format(i))
print('layer{}'.format(i))
m.eval()
for param in m.parameters():
param.requires_grad = False
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x3 = x
x = self.layer4(x)
return x, x3
# return x
# def load_param(self, model_path):
def load_param(self, model_path='E:/model/resnet50_ibn_a.pth'):
param_dict = torch.load(model_path)
print(param_dict)
print('*'*60)
if 'state_dict' in param_dict:
param_dict = param_dict['state_dict']
for i in param_dict:
if 'fc' in i:
continue
self.state_dict()[i.replace('module.', '')].copy_(param_dict[i])
ArchCfg = namedtuple('ArchCfg', ['block', 'layers'])
arch_dict = {
#'resnet18': ArchCfg(BasicBlock, [2, 2, 2, 2]),
#'resnet34': ArchCfg(BasicBlock, [3, 4, 6, 3]),
'resnet50': ArchCfg(Bottleneck_IBN, [3, 4, 6, 3]),
'resnet101': ArchCfg(Bottleneck_IBN, [3, 4, 23, 3]),
'resnet152': ArchCfg(Bottleneck_IBN, [3, 8, 36, 3]),}
def resnet50_ibn_a(last_stride=1, pretrained=False, **kwargs):
"""Constructs a ResNet-50 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet_IBN(last_stride, Bottleneck_IBN, [3, 4, 6, 3], **kwargs)
block_dict = dict()
if pretrained:
state_dict = torch.load('E:/model/resnet50_ibn_a.pth')
print('Load pretrained model from ===> E:/model/resnet50_ibn_a.pth')
model.load_param('E:/model/resnet50_ibn_a.pth')
# print(state_dict.items())
for k, v in state_dict.items():
# print(k, v)
if 'layer4.' in k:
block_dict.update({k: v})
return model
#def get_resnet50_org():
# model = ResNet_IBN(last_stride=1, arch_dict['resnet50'].block, arch_dict['resnet50'].layers)
# return model
# if __name__ == '__main__':
# import torch
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # PyTorch v0.4.0
#
# model = resnet50_ibn_a(pretrained=False)
# input = torch.randn(1, 3, 384, 128)
# out1, out2 = model(input)
# print(out1.shape)
# print(out2.shape)
# print('&'*80)
# # print(y.shape)
# # print(x3.shape)
 and support in autotvm is inconsistent depending on workload.
and support in autotvm is inconsistent depending on workload.