Hello,
I am trying to quantize a resnet50 tflite model from fp32 to fp16 via the ToMixedPrecision Pass. This post was very useful for me to set the required stuff for me to proceed with quantization.
Coming to my issue,
I first downloaded a ResnetNet50V2 model using the Keras Applications API, quantised it to fp16 and then converted it to a tflite model.
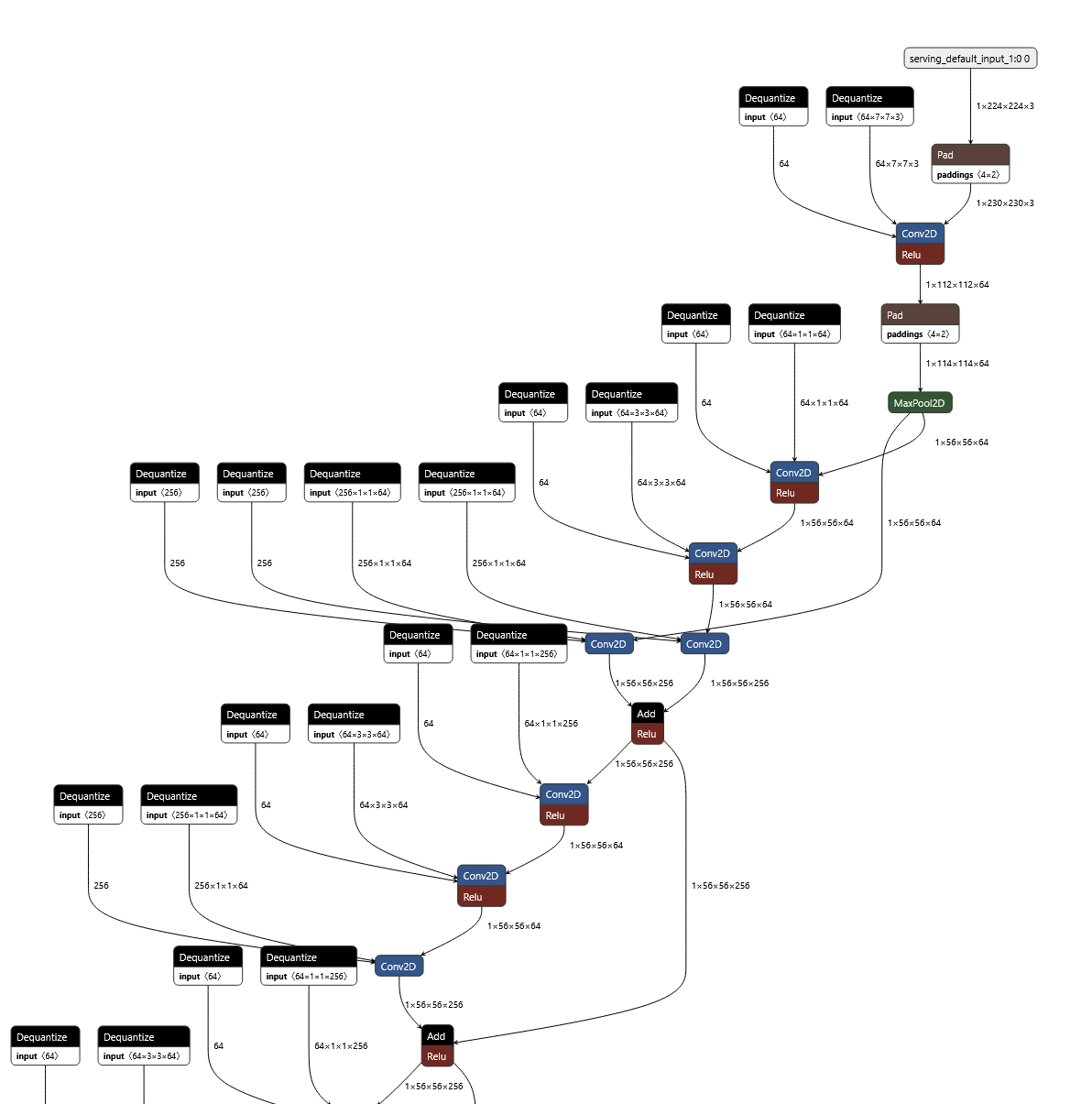
However, when I check the graph of the quantised model on Netron, I see this:
Further, the input layer looks like this :
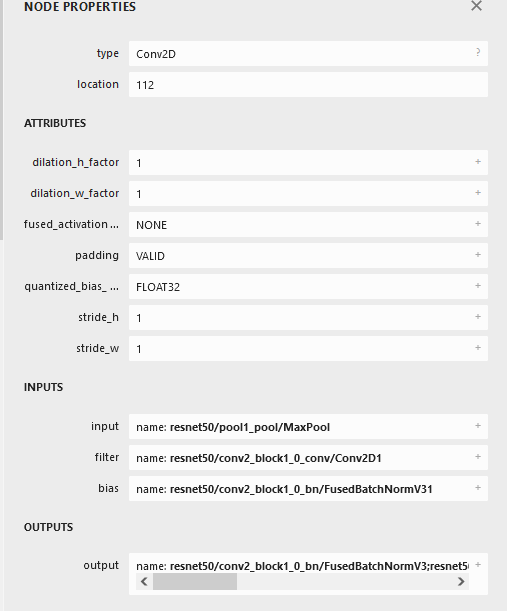
And a Conv layer looks like this:
I do not understand why the datatypes still show up as float32 in the conv layer.
The code which performed this quantizaton is :
Representative dataset gen:
test_datagen = ImageDataGenerator(preprocessing_function=preprocess_input)
test_generator = test_datagen.flow_from_directory(TEST_DATA_DIR,
target_size=(IMG_WIDTH, IMG_HEIGHT),
batch_size=1, shuffle=False,
class_mode='categorical')
def represent_data_gen():
""" it yields an image one by one """
for ind in range(len(test_generator.filenames)):
img_with_label = test_generator.next() # it returns (image and label) tuple
image = np.array(img_with_label[0], dtype=np.float32, ndmin=2)
# image = image.reshape((1,3,224,224))
# print(image.shape)
yield [image] # return only image
Actual quantization and conversion:
# CONVERSION TO FP-16
# convert a tf.Keras model to tflite model
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16] # save them in float16
converter.representative_dataset = represent_data_gen
tflite_model = converter.convert()
# write the model to a tflite file as binary file
with open("resnet50_imagenet_both-fp16-quant-nov9.tflite", "wb") as f:
f.write(tflite_model)
The ToMixedPrecision Pass is like this:
def graph_optimize(mod, params, run_fp16_pass, run_other_opts):
mod = tvm.IRModule.from_expr(mod["main"])
if run_other_opts:
mod = tvm.relay.transform.FastMath()(mod)
mod = tvm.relay.transform.EliminateCommonSubexpr()(mod)
BindPass = tvm.relay.transform.function_pass(
lambda fn, new_mod, ctx: tvm.relay.build_module.bind_params_by_name(
fn, params
),
opt_level=1,
)
mod = BindPass(mod)
mod = tvm.relay.transform.FoldConstant()(mod)
mod = tvm.relay.transform.CombineParallelBatchMatmul()(mod)
mod = tvm.relay.transform.FoldConstant()(mod)
if run_fp16_pass:
mod = InferType()(mod)
mod = ToMixedPrecision()(mod)
if run_other_opts and run_fp16_pass:
# run one more pass to clean up new subgraph
mod = tvm.relay.transform.EliminateCommonSubexpr()(mod)
mod = tvm.relay.transform.FoldConstant()(mod)
mod = tvm.relay.transform.CombineParallelBatchMatmul()(mod)
mod = tvm.relay.transform.FoldConstant()(mod)
return mod, params
Finally, when I do an inference in tvm on cuda target on my GPU (NVIDIA A3000 enterprise GPU), I do not get any speedup/accelaration. I get similar times as a normal non-quantised fp32 resnet50 model.
Please help me in identifying where I am going wrong with fp16 quantization.
TIA.
@AndrewZhaoLuo