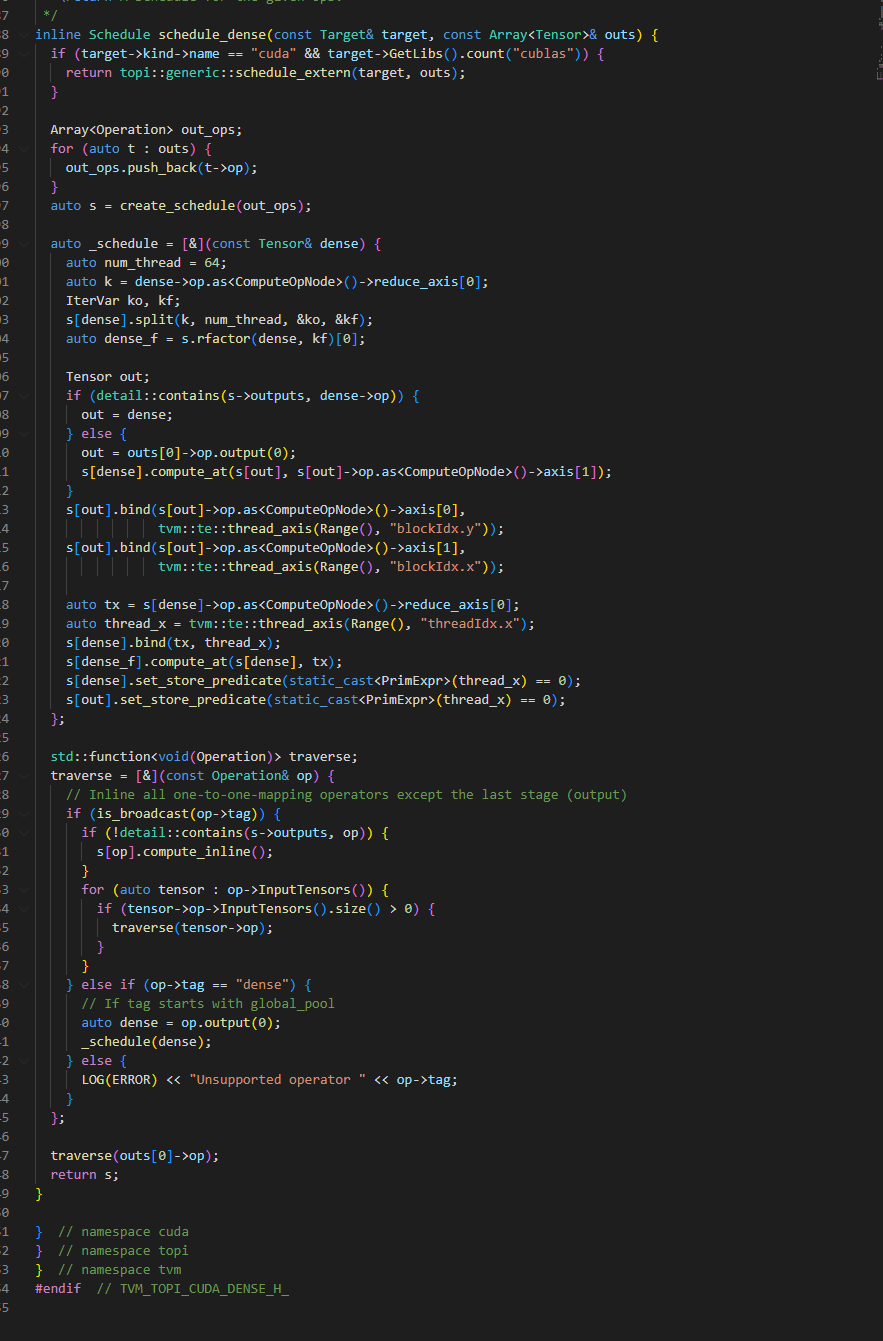
Such as this function, is that reason cuase TVM run slower than pytorch?
I don’t think so…TVM is slower than PT in compilation time because TVM involves lots of optimization passes and code generation while PyTorch is working on a dynamic graph interpretation.
emmm, when I complied a model from PT in TVM, I get a graph_executor and then count the model inference time by
model_executor_vanilla.benchmark(dev, func_name='run', repeat=2, number=1)
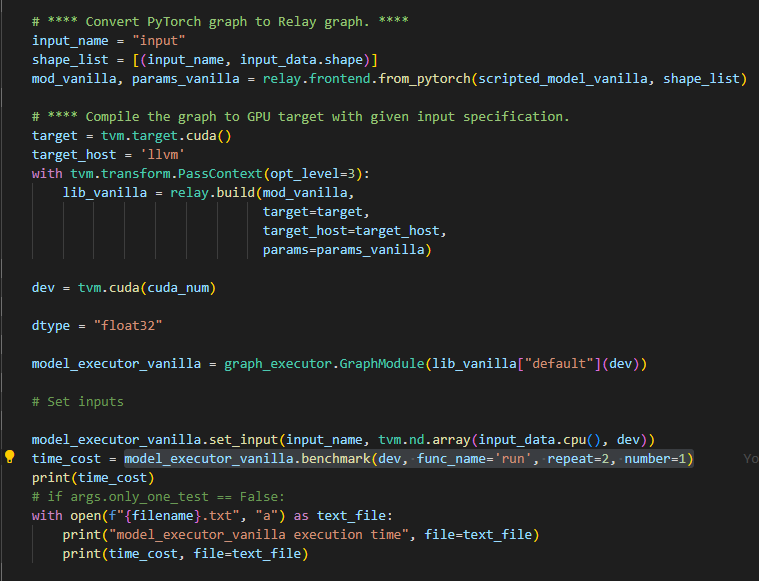
I do not see any TVM tuning applied to the TVM compiled model. The inference time can be changed dramatically with application of tuning or without. You need to use AutoTVM or AutoScheduler (so far separately, new tuning approach which is merge of these two is comming  )
)
More examples for AutoTVM are here: tvm/gallery/how_to/tune_with_autotvm at main · apache/tvm · GitHub
More examples for AutoSchduler are here: tvm/gallery/how_to/tune_with_autoscheduler at main · apache/tvm · GitHub
Yeah, I exactly don’t tune the model with AutoTVM. I just transform the model into TVM IR? And build it. But I found it run slower then PT. Is that what you mean I haven’ t tune the model by AutoTVM? So i get the slower “run” function?
tvm operations consist of compute and schedules.
Compute describes the set of low level ops how to perform high level op. I.e. reduction over certain axis with multiplicaiton one elements to other describes conv2d.
Schedule describes how straightforward compute should be mapped to certain hardware to get better performance. It is a rules how to transform one generic TIR graph to HW specific TIR. I.e. one of the transformation is spiting of iteration axis and assigning reminder to the global work group and split to local work size to utilize the whole GPU the most efficient way.
The divider and reminder usually are selected by empiric way of analyzing kernel on many networks. This is a way of many inference engines and neural network frameworks.
Or you can automatically create many configurations how to split above mentioned axis, measure performance of kernel with such parameters and select the best.
AutoTVM and AutoScheduler are doing exactly the same - they define the search space, select some paramenters, generate many kernels, measure and save all information to the statistic file. Then this statistics can be applied during network compilation.
The difference of network compiled without tuning or with tuning can be 2x-10x depending on hardware and tuner.
Details how to extract tasks, tune, save to log file and then use this file you can find by links which I shared above