When TVM reads a model, it represents it in relay. There, initially each operator looks like a separate function, and invocation of an operator looks like a function call. Then, a fusion pass will partition the graph, where each partition is a group of such calls. Each such group will become a single function later on. This is where names like tvmgen_default_fused_add_multiply_erf_multiply_add_multiply come from. Then, once the relay has been translated into TIR, some loop nests in it may be marked as targeted for an accelerator, like an NVIDIA GPU. Each such loop nest will be extracted into its own function, with _kernelN appended to the name. These are typically pure computations, without any function calls, or control flow.
In your code, you can try doing something like print(lib_einsum.ir_mod) to see the TIR module, but it may have the kernels already extracted.

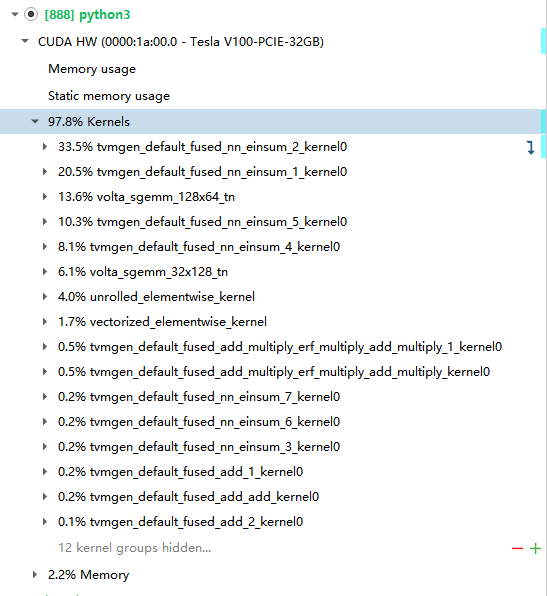
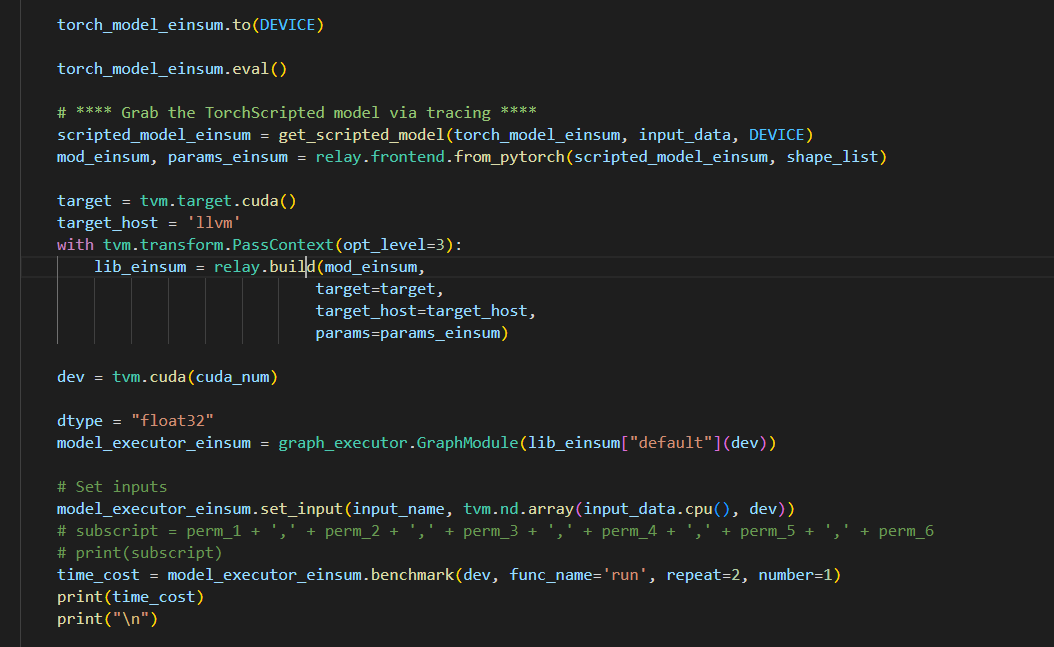
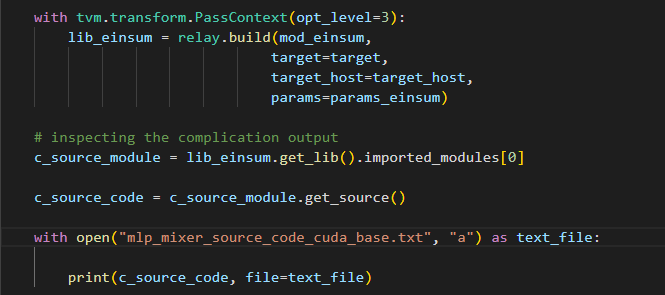 and it look like this
and it look like this
