Hello everyone. I want to deploy Unet on PYNQ Z2. When I use sim mode, I can excute the code without any problems. But if I change the mode to pynq, I will meet a GraphModule Error(Check failed: (data != nullptr) is false: ). My code is listed below, and my tvm version is 0.9.
env = vta.get_env()
device = "vta"
target = env.target if device == "vta" else env.target_vta_cpu
if env.TARGET not in ["sim", "tsim", "intelfocl"]:
# Get remote from tracker node if environment variable is set.
# To set up the tracker, you'll need to follow the "Auto-tuning
# a convolutional network for VTA" tutorial.
tracker_host = os.environ.get("TVM_TRACKER_HOST", None)
tracker_port = os.environ.get("TVM_TRACKER_PORT", None)
# Otherwise if you have a device you want to program directly from
# the host, make sure you've set the variables below to the IP of
# your board.
device_host = os.environ.get("VTA_RPC_HOST", "192.168.31.51")
device_port = os.environ.get("VTA_RPC_PORT", "9091")
if not tracker_host or not tracker_port:
remote = rpc.connect(device_host, int(device_port))
else:
remote = autotvm.measure.request_remote(
env.TARGET, tracker_host, int(tracker_port), timeout=10000
)
# Reconfigure the JIT runtime and FPGA.
# You can program the FPGA with your own custom bitstream
# by passing the path to the bitstream file instead of None.
reconfig_start = time.time()
vta.reconfig_runtime(remote)
vta.program_fpga(remote, bitstream=None)
reconfig_time = time.time() - reconfig_start
print("Reconfigured FPGA and RPC runtime in {0:.2f}s!".format(reconfig_time))
else:
remote = rpc.LocalSession()
ctx = remote.ext_dev(0) if device == "vta" else remote.cpu(0)
# onnx_model = onnx.load("Unet1.onnx")
model = torch.jit.load("Unet.pt")
test_path = '/home/dengbw/PycharmProjects/Unet/data/test/0.png'
save_res_path = test_path.split('.')[0] + '_VTA_res.png'
img = cv2.imread(test_path)
# 转为灰度图
img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
# 转为batch为1,通道为1,大小为512*512的数组
img = img.reshape(1, 1, img.shape[0], img.shape[1])
# 转为tensor
img_tensor = torch.from_numpy(img)
img_data = img_tensor
input_name = "input.1"
shape_dict = {input_name: img_data.shape}
# mod, params = relay.frontend.from_onnx(onnx_model, shape_dict)
mod, params = relay.frontend.from_pytorch(model, [('input.1',(img_data.shape))])
with vta.build_config(opt_level=3, disabled_pass={"AlterOpLayout", "tir.CommonSubexprElimTIR"}):
lib = relay.build(
mod, target=tvm.target.Target(target, host=env.target_host), params=params
)
# print(lib)
temp = utils.tempdir()
lib.export_library(temp.relpath("graphlib.tar"))
remote.upload(temp.relpath("graphlib.tar"))
lib = remote.load_module("graphlib.tar")
module = graph_executor.GraphModule(lib["default"](ctx))
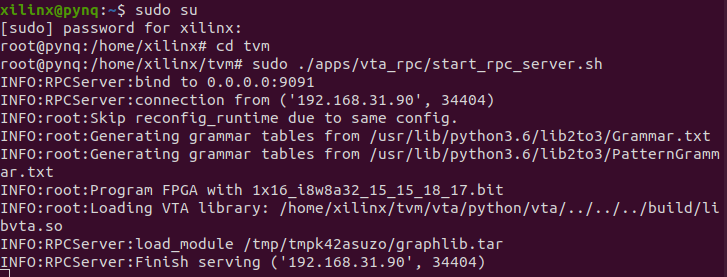
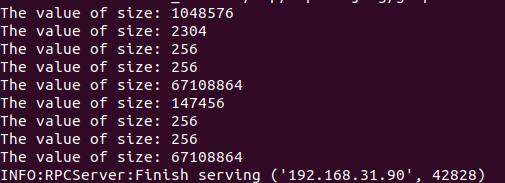
This is the error I encountered.
Reconfigured FPGA and RPC runtime in 8.74s!
One or more operators have not been tuned. Please tune your model for better performance. Use DEBUG logging level to see more details.
Traceback (most recent call last):
File "/home/dengbw/PycharmProjects/pynq/opt_Unet.py", line 84, in <module>
module = graph_executor.GraphModule(lib["default"](ctx))
File "/home/dengbw/tvm/python/tvm/_ffi/_ctypes/packed_func.py", line 237, in __call__
raise get_last_ffi_error()
tvm.error.RPCError: Traceback (most recent call last):
4: TVMFuncCall
3: tvm::runtime::RPCWrappedFunc::operator()(tvm::runtime::TVMArgs, tvm::runtime::TVMRetValue*) const
2: tvm::runtime::RPCClientSession::CallFunc(void*, TVMValue const*, int const*, int, std::function<void (tvm::runtime::TVMArgs)> const&)
1: tvm::runtime::RPCEndpoint::CallFunc(void*, TVMValue const*, int const*, int, std::function<void (tvm::runtime::TVMArgs)>)
0: tvm::runtime::RPCEndpoint::HandleUntilReturnEvent(bool, std::function<void (tvm::runtime::TVMArgs)>)
15: TVMFuncCall
14: tvm::runtime::PackedFuncObj::Extractor<tvm::runtime::PackedFuncSubObj<tvm::runtime::{lambda(tvm::runtime::TVMArgs, tvm::runtime::TVMRetValue*)#2}> >::Call(tvm::runtime::PackedFuncObj const*, tvm::runtime::TVMArgs, tvm::runtime::TVMRetValue*)
13: tvm::runtime::RPCServerLoop(int)
12: tvm::runtime::RPCEndpoint::ServerLoop()
11: tvm::runtime::RPCEndpoint::HandleUntilReturnEvent(bool, std::function<void (tvm::runtime::TVMArgs)>)
10: tvm::runtime::RPCEndpoint::EventHandler::HandleNextEvent(bool, bool, std::function<void (tvm::runtime::TVMArgs)>)
9: tvm::runtime::RPCEndpoint::EventHandler::HandleProcessPacket(std::function<void (tvm::runtime::TVMArgs)>)
8: tvm::runtime::RPCSession::AsyncCallFunc(void*, TVMValue const*, int const*, int, std::function<void (tvm::runtime::RPCCode, tvm::runtime::TVMArgs)>)
7: tvm::runtime::LocalSession::CallFunc(void*, TVMValue const*, int const*, int, std::function<void (tvm::runtime::TVMArgs)> const&)
6: tvm::runtime::PackedFuncObj::Extractor<tvm::runtime::PackedFuncSubObj<tvm::runtime::GraphExecutorFactory::GetFunction(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, tvm::runtime::ObjectPtr<tvm::runtime::Object> const&)::{lambda(tvm::runtime::TVMArgs, tvm::runtime::TVMRetValue*)#1}> >::Call(tvm::runtime::PackedFuncObj const*, tvm::runtime::TVMArgs, tvm::runtime::TVMRetValue*)
5: tvm::runtime::GraphExecutorFactory::ExecutorCreate(std::vector<DLDevice, std::allocator<DLDevice> > const&)
4: tvm::runtime::GraphExecutor::Init(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, tvm::runtime::Module, std::vector<DLDevice, std::allocator<DLDevice> > const&, tvm::runtime::PackedFunc)
3: tvm::runtime::GraphExecutor::SetupStorage()
2: tvm::runtime::NDArray::Empty(tvm::runtime::ShapeTuple, DLDataType, DLDevice, tvm::runtime::Optional<tvm::runtime::String>)
1: tvm::runtime::DeviceAPI::AllocDataSpace(DLDevice, int, long long const*, DLDataType, tvm::runtime::Optional<tvm::runtime::String>)
0: 0xb28a6c9f
File "/home/dengbw/tvm/src/runtime/rpc/rpc_endpoint.cc", line 376
RPCError: Error caught from RPC call:
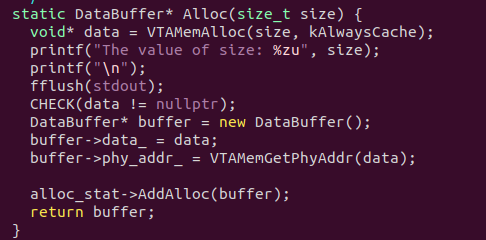
[15:57:03] /home/xilinx/tvm/vta/runtime/runtime.cc:179: Check failed: (data != nullptr) is false:
Any one can help me?