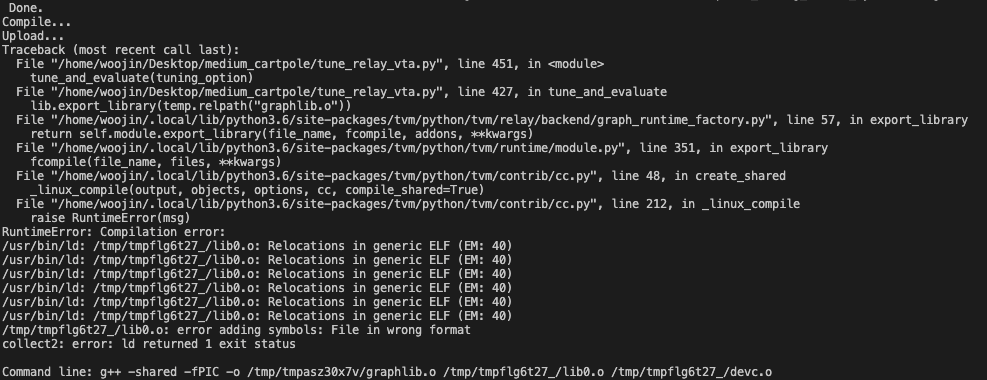
I solved, but I don’t know why it works.
I checked your git commit, [Fix][Tutorial][VTA] Update tune_relay_vta.py to support single board by insop · Pull Request #7100 · apache/tvm · GitHub
I changed
lib.export_library(temp.relpath("graphlib.o")) this code to lib.export_library(temp.relpath("graphlib.tar"))
Why does this work? The only thing I did is changing graphlib.o file to graphlib.tar file.
Also, when executing code, it found some warning message like this:
[Task 8/10] Current/Best: 0.00/ 1.58 GFLOPS | Progress: (10/10) | 5.36 s Done.
[Task 9/10] Current/Best: 0.00/ 0.00 GFLOPS | Progress: (10/10) | 1.31 sWARNING:root:Could not find any valid schedule for task Task(func_name=conv2d_packed.vta, args=((‘TENSOR’, (1, 8, 28, 28, 1, 16), ‘int8’), (‘TENSOR’, (16, 8, 1, 1, 16, 16), ‘int8’), (2, 2), (0, 0, 0, 0), (1, 1), ‘NCHW1n16c’, ‘int32’), kwargs={}, workload=(‘conv2d_packed.vta’, (‘TENSOR’, (1, 8, 28, 28, 1, 16), ‘int8’), (‘TENSOR’, (16, 8, 1, 1, 16, 16), ‘int8’), (2, 2), (0, 0, 0, 0), (1, 1), ‘NCHW1n16c’, ‘int32’)). A file containing the errors has been written to /tmp/tvm_tuning_errors_rjrt44ra.log.
Done.
[Task 10/10] Current/Best: 0.00/ 11.05 GFLOPS | Progress: (10/10) | 21.55 s Done.
Compile…
Upload…
Evaluate inference time cost…
Mean inference time (std dev): 755.27 ms (11.72 ms).
Is this negligible error?