In order to see the performance difference of Graph Runtime and VM Runtime. We construct a simple network with three layers of dense+bias structures. The dimensions are 1024-512-256-128.
We construct three cases:
- using Graph Runtime, the input batch size is fixed at compilation. “Graph Runtime”
- using VM Runtime, the input batch size is fixed at compilation. “VM Static”
- using VM Runtime, the input batch relies on “relay.Any()” to do the compilation, which could support dynamic batch size with only one compilation for different batch sizes. “VM Dynamic”
We measure the inference run time in unit of “ms” . The results are as following:
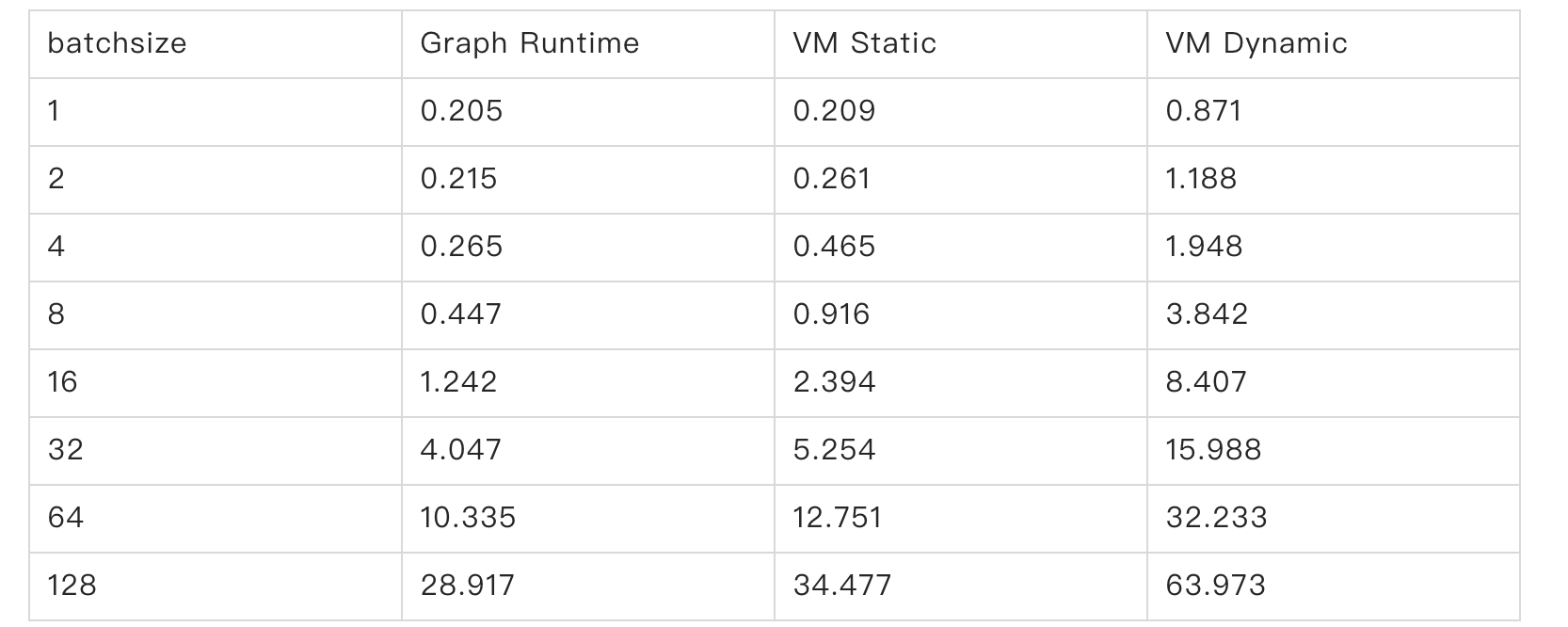
We found that the for the fixed batch size case, the VM runtime is slower than Graph Runtime and can be up to 2 times. We guess this comes from the additional execution of AllocStorage and AllocTensor in VM runtime.
For the dynamic batch size case, the VM runtime is slower than the VM runtime with fixed batch size, which can be up to 4.5 times. We found that, there are many additional instructions for calculating the tensor shape in dynamic input size case. For example, the number of VM instructions with static batch size is only 22, while the number of VM instructions to support dynamic batch size is 85!!
So, it seems that compared with GraphRuntime, VM runtime has some performance degradation. And with dynamic input size from “relay.Any()”, the performance degradation is even larger due to the calculation for the tensor shape. What to think of such a performance degradation in VM runtime and dynamic shape case? Is there any possible future plan to further increase the efficiency of the VM runtime, especially for the dynamic shape support?
Thank you so much!