I want to copy 8xhalf data from global memory to local Memory, But I found the error’ValueError: Check failed: op->lanes <= 4 (8 vs. 4) : Ramp of more than 4 lanes is not allowed.’ But the strange thing is when I copy 8xhalf data from local memory to shared memory, it’s correct. The TIR is the same in both cases,
And I have looked into cuda source Code.the error case is: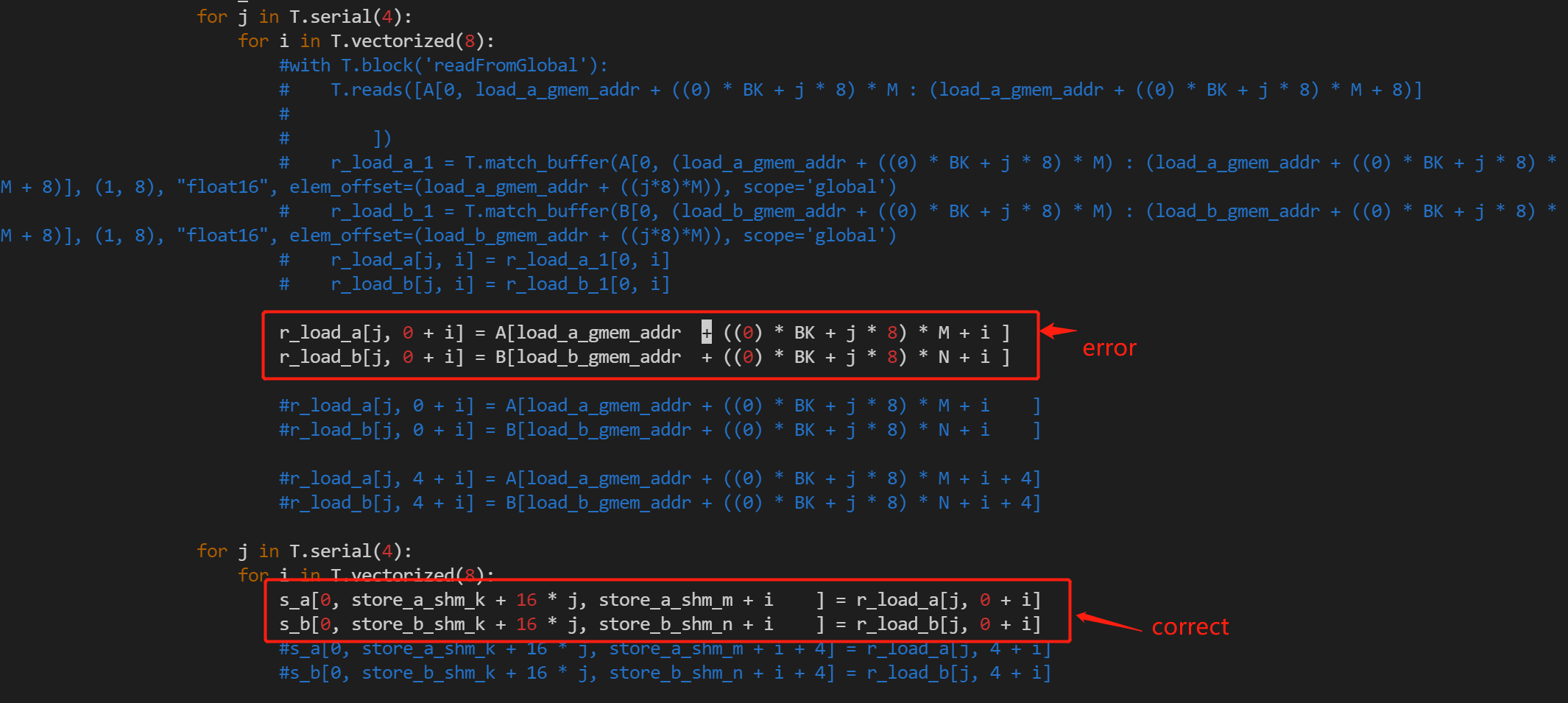
_1 = make_int4(index_0, index_1, index_2, index_3);
local_memory[i] = make_uint2(__pack_half2(global_memory[index0], …))’
but the correct case is:
(uint4*)shared_memory[i] = (uint4*)local_memory[index_0]*
Because the 8xfloat16 data in memory(whatever in global、shared、local) are continuous, so I want to use the ‘*(uint4*)’ to copy data. how can i solve this error? @tqchen