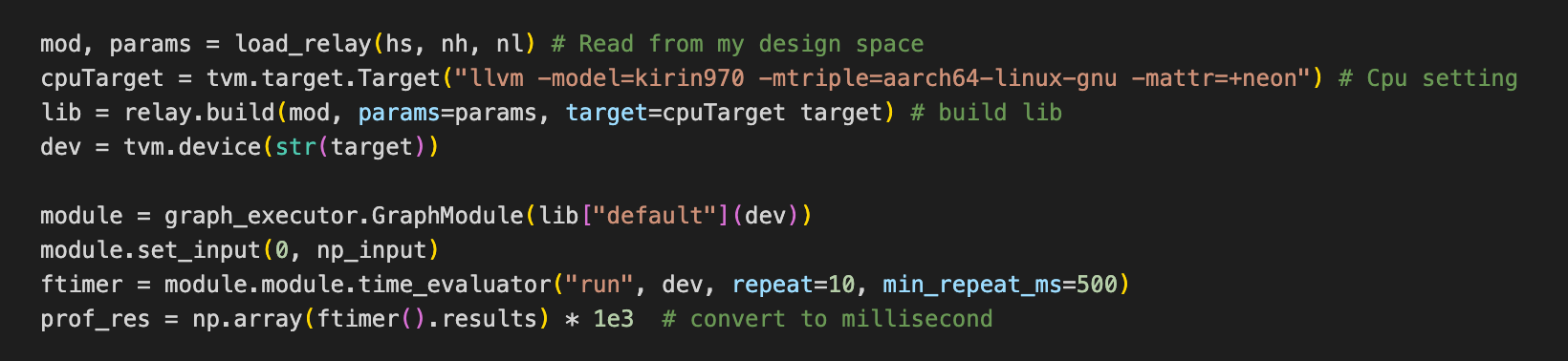
Sorry, I am using the following python code to run my simulation and I am not quite familiar with the backend settings with C++. I did go over thread_pool.cc and threading_backend.cc, but I am still wondering is it possible to utilize or call “TVM_REGISTER_GLOBAL(“runtime.config_threadpool”)” or “Configure(AffinityMode mode, int nthreads, bool exclude_worker0)” function in python as we did in the remote setting. (i.e. remote.get_function(‘runtime.config_threadpool’))