Summary
Last year an RFC was proposed to address the organization and structure of the TVM Documentation. After discussion, a first pass was made at the documentation updates following a formal documentation method developed by Divio. This pre-RFC proposes to extend the original RFC, with additions to address both user and developer audiences, as well as sub-projects within TVM.
At a high level, this pre-RFC proposes this basic high level organization structure of documents. It recognizes that while in most communities there is a distinct divide between the user and the developer communities, there can be significant overlap given the nature of TVM as an optimizing compiler.
It also addresses a common issue frequently seen with Divio style documentation, namely the addition of introduction and landing pages, as well as topic-specific pages. The next section describes the proposed high-level reorganization in detail, with two alternatives for comparison and discussion.
This pre-RFC is concerned with the organization of the documents, and not the content. As such, the implementation of this pre-RFC would move documents, and only create new documents as top-level placeholders and indexes.
The goals of this reorganization is to create a document architecture that make it clear what types of documents can be written, and how they are organized. The desired result is to make it easier for users meet their goals, whatever they are, and to make it easier for the development community to contribute to the TVM documentation.
L0 - Full User/Developer guides
This format is distinguished by putting all four document types into both the developer and the user guides. It also adds a specific section for getting started, a common feature across nearly every documentation style.
- Getting Started
- About TVM
- Installing TVM
- User Guide
- Tutorial - A multi-chapter long-form document that to introduces users on how to install and operate TVM, with the goal of successfully introducing basic concepts and workflows.
- How Tos - Documents that describe how to perform common tasks with TVM, divided amongst common application areas.
- Deep Dives - Documents that cover the architecture and design of TVM, at a level appropriate for users.
- Reference - User facing APIs, typically generated from source.
- Developer Guide
- Tutorial - A guided tour through the TVM code-base, using the TVMC application as a framing guide for major components of the code.
- How Tos - Documents that describe how to contribute to particular code areas.
- Deep Dives - Documents that cover the architecture and design of TVM, at a level appropriate for developers.
- Reference - Developer reference documentation.
- Topic Guides
- MicroTVM - A collection of links to docs related to TVM
- VTA - A collection of links of docs related to VTA
L1 - User and Developer with Pruned Subsections
The primary differences between this style and L0 are that the API reference section is broken out from both the developer and user guide into it’s own major subsection, and the deep dive section is removed from the user guide.
- Getting started
- About TVM
- Install TVM
- User Guide
- Tutorials
- How to
- API Reference (flat)
- For developers
- Tutorials
- How to
- Deep Dive
- Topics
- microTVM
L2 - Tour style
This style takes an approach that is more focused on the user journey, from beginner to advanced with topics of interest and more focus on demos.
- Get started
- Installation (build from source, tlcpack.ai, etc)
- Demo: Optimize an operator
- Demo: Optimize a neural net (w/ TVMC, w/o TVMC)
- Demo: Minimal deployment (w/ TVM runtime, w/ microTVM runtime)
- Contribute
- Tutorial
- Relay: Import to Relay example: LeNet-5 on MNIST
- Relay: Build Relay to binary example: LeNet-5 on MNIST
- TE: Implement operators in Tensor Expression (compute & schedule) example: matrix multiplication
- AutoScheduler / AutoTVM: Tune operators example: matrix multiplication
- microTVM: deployment
- mobile deployment
- Architectural Guide
- Frontend
- Relay: Graph-level design: IR, pass, lowering
- TensorIR: Operator-level design: IR, schedule, pass, lowering
- TOPI: Pre-defined operators operator coverage
- AutoScheduler / AutoTVM: Performance tuning design
- Runtime & microTVM design
- Customization with vendor libraries BYOC workflow
- RPC system
- Target system
- …
- Topics of interests
- microTVM
- VTA
- …
- More demos
- Sparse models
- …
Partial POC Rendering of L0


Guide Level Explanation
Drawing from the former RFC:
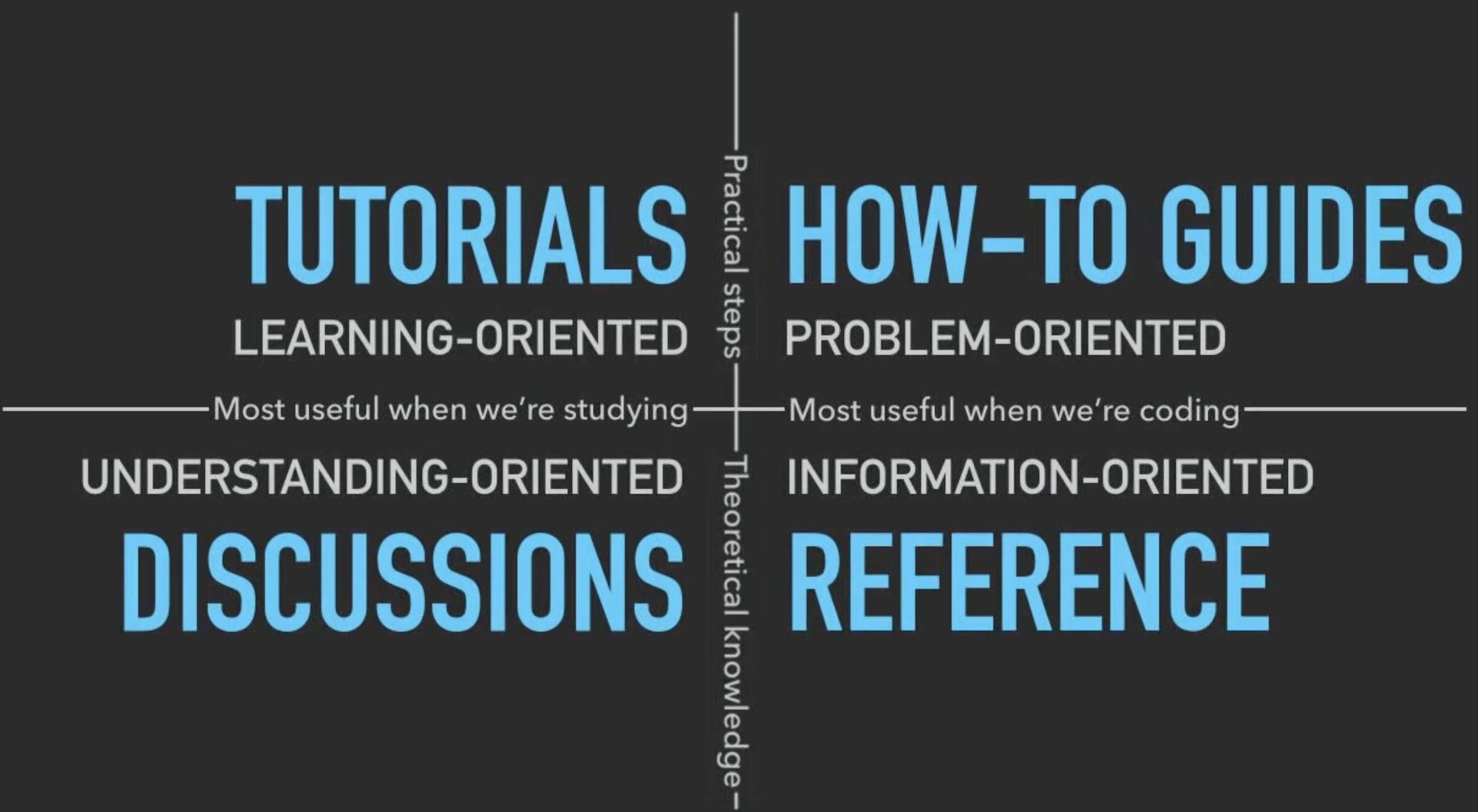
The Four Document Types
Introductory Tutorials
These are step by step guides to introduce new users to a project. A successful introductory tutorial successfully get the user engaged with the software without necessarily explaining why the software works the way it does. Those explanations can be saved for other document types; the introductory tutorial focuses on a successful first experience. These are the most important docs to turning newcomers into new users and developers. A fully end-to-end tutorial, from installing TVM and supporting ML software, to creating and training a model, to compiling to different architectures will give a new user the opportunity to use TVM in the most efficient way possible.
Tutorials need to be repeatable and reliable, because the lack of success means a user will look for other solutions.
How-to Guides
These are step by step guides on how to solve particular problems. The user can ask meaningful questions, and the documents provide answers. An examples of this type of document might be, “how do I compile an optimized model for ARM architecture?” or “how do I compile and optimize a TensorFlow model?” These documents should be open enough that a user could see how to apply it to a new use case. Practical usability is more important than completeness. The title should tell the user what problem the how-to is solving.
How are tutorials different from how-tos? A tutorial is oriented towards the new developer, and focuses on successfully introducing them to the software and community. A how-to in contrast focuses on accomplishing a specific task within the context of basic understanding. A tutorial helps to onboard, a how-to helps to accomplish a task.
Reference
Reference documentation describes how the software is configured and operated. APIs, key functions, commands, and interfaces are all candidates for reference documentation. These are the technical manuals that let users build their own interfaces and programs. They are information oriented, focused on lists and descriptions. You can assume that the audience has a grasp on how the software works and is looking for specific answers to specific questions. Ideally, the reference documentation should have the same structure as the code base and generated automatically as much as possible.
Explanations (Deep Dive)
Background material on a topic. These documents help to illuminate and understand the application environment. Why are things the way they are? What were the design decisions, what alternatives were considered, what are the RFCs describing the existing system. This includes academic papers and links to publications relevant to the software. Within these documents you can explore contradictory and conflicting position, and help the reader make sense of how and why the software was built the way it is. It’s not the place for how-to’s and technical descriptions, and instead focuses on higher level concepts.
Reference Level Explanation
This refactor will require a shift of how the documents are organized. In general, Tutorials and How-Tos are written as Sphinx Gallery documents, allowing for the generation of text, python source, and Jupyter Notebooks. This allows the user to consume these working code samples in a number of ways, but comes at the cost of fixed format that can be confusing to navigate. To help mitigate this, the tutorials and how-tos will be broken up into a more fine grained directory structure. For example:
tvm/
gallery/
dev_how_tos/
compile_models/
...
how_tos/
tutorial/
Rather than render the gallery in one pass as a nested structure (resulting in a single page with multiple sections), instead each directory will be rendered independently. This will aid in navigation through the galleries, and also give more fine-grained grouping of similar topics. The naming of the directory reflects the organization of Sphinx documentation folder, for example:
tvm/
docs/
deep_dive/
how_tos/
index.rst
**compile_models/**
...
reference/
**tutorial/**
dev_deep_dive/
dev_how_tos/
dev_reference/
dev_tutorial/
Depending on the type of documentation, some of the directories may be generated. For example, the tutorial and compile_models directories are auto-generated by Sphinx Gallery. To add a new Sphinx Gallery requires the following steps:
- Create a gallery subdirectory with the how-to or tutorial documents
- Create entries in the docs conf.py example_dirs and gallery_dirs variables to reference the source and target directories.
- Update the appropriate index pages in the docs subdirectories to add the new directories to the Sphinx table of contents.
Drawbacks
One consistent drawback of this approach is how major subprojects are handled. For example, microTVM may require a specific set of tutorials and how-tos, but these can become mixed in with other TVM specific documents. This will be mitigated through two means:
- Subdirectories within the How-Tos can target specific topics
- Landing pages can be created for specific topics that collect links to all of the pages related to that topic.
Another drawback is that this format may require a user to dig deeper on the first run experience, requiring them to dig into a tutorial or how-to to install the software. This can be mitigated by refactoring the landing page to include a “Quick Start” guide for installing the TVM software.
Throughout the open source ecosystem, there is often a distinction between documentation for users and documentation for developers. The TVM community is unique in that frequently users will need to extend TVM to accomplish some goal, for example adding a new backend for code generation. This issue is addressed by dividing the user and developer topics, but keeping them within the same documentation system.
Rationale and Alternatives
This style of documentation has been formalized by developed by Divio and deployed throughout the open source communities. Although it can be difficult to characterize documents within the system (“Should this be a developer or user doc?” “Is this a tutorial or a how-to?”), working within the constraints of a formalized system brings many benefits:
- It helps prevent documentation sprawl. Rather than create new top-level headings to capture new ideas, new ideas are logically documented at different levels of detail within the for existing types.
- It creates a consistent user experience. Users know exactly where to look depending on their needs. New users will find a path to success through tutorials, while existing users who need to solve common tasks can look to the how-tos for guidance.
- It encourages new documentation. Developers have a framework for what docs should look like, and where they should go.
- It takes advantage of current content. A proof-of-concept implementation of this method consisted largely of moving new documents.
- It creates a framework to improve existing content. Many how-tos duplicate steps repeatedly. This will allow us to identify the duplications and refactor the documents into more targeted forms.
In researching documentation systems, there aren’t many formalized systems that have been published.
Prior Art
Projects That Follow This Style
Kubernetes roughly follows this style, augmented with a landing page and a getting started page.
- Home
- Getting Started
- Concepts
- Tasks
- Tutorials
- Reference
- Contribute
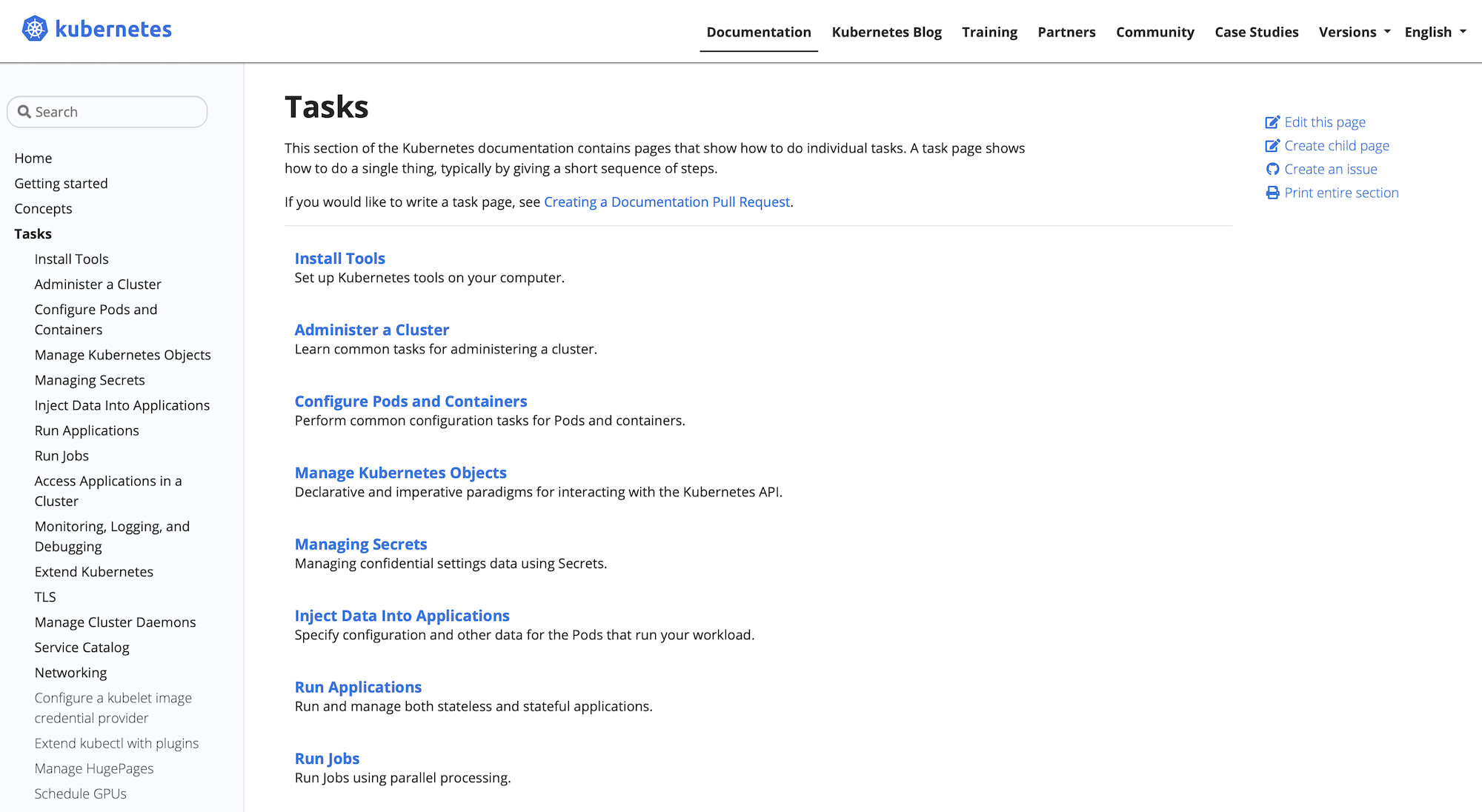
Numpy also follows a similar style, with a very flat organization and additional documents of interest to users.
- What is NumPy?
- Installation
- NumPy quickstart
- NumPy: the absolute basics for beginners
- NumPy fundamentals
- Miscellaneous
- NumPy for MATLAB users
- Building from source
- Using NumPy C-API
- NumPy Tutorials
- NumPy How Tos
- For downstream package authors
- F2PY Users Guide and Reference Manual
- Glossary
- Under-the-hood Documentation for developers
- NumPy’s Documentation
- Reporting bugs
- Release Notes
- Documentation conventions
- NumPy license
Projects in the ML Community
PyTorch has a much more fragmented style, with Getting Started, Tutorials, and Docs (reference docs) spread across a variety of locations and using a variety of styles. The leads to a much more fragmented user experience. However, it has also been cited as a positive learning experience, and the tag search feature is powerful for the volume of documentation. Developing a similar site would likely be resource intensive.
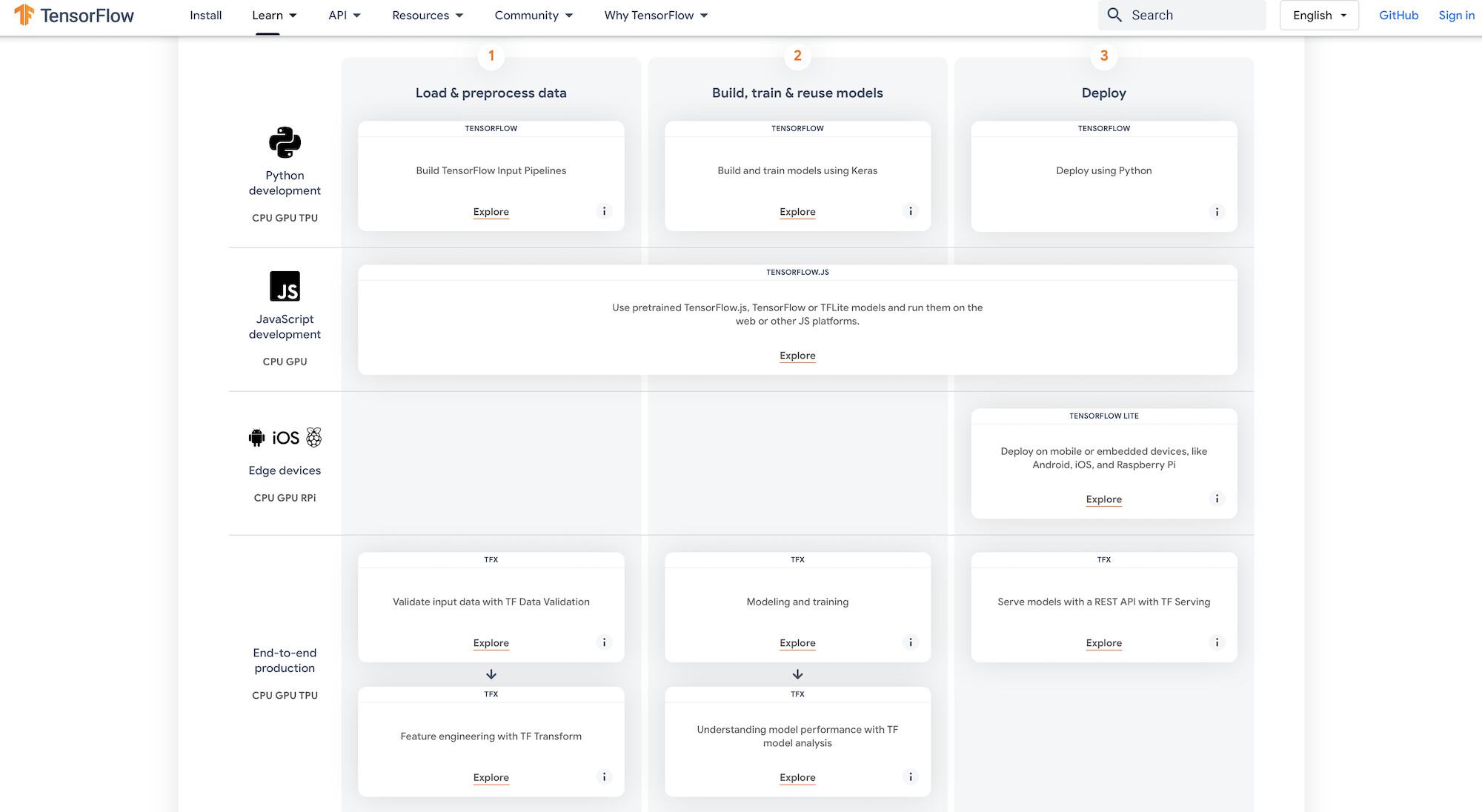
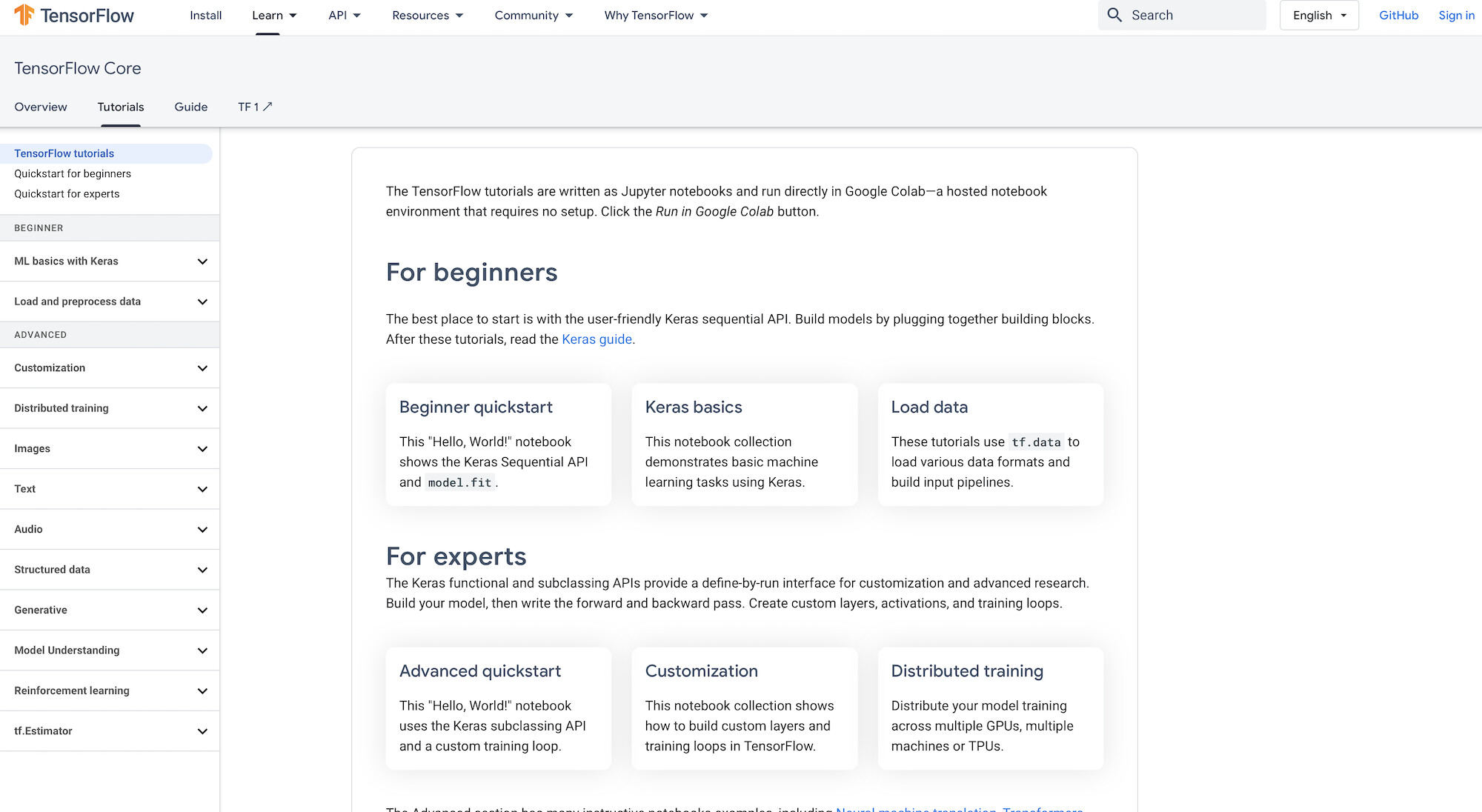
TensorFlow follows a style that’s closer to working from beginner to advanced. One standout feature is a graphical representation of the ecosystem, with links to docs that fall into a particular categorization. When building out the developer documents, it may be worthwhile to consider a similar structure.
Other Apache Software Projects
Hadoop and Spark follow a very loose and informal documentation structure.
Sphinx Documentation Style
It’s instructive to look at the documentation style of a project for producing documentation. Sphinx follows a structure that is similar to the Divio style, but focuses more on guiding the user from getting started through advanced topics, similar to the TensorFlow style.
Non-goals
- This documentation system only loosely addresses how subprojects should be handled.
- It does not consider specific future documents, or a plan for refactoring duplicated content in existing documents.
- It does not address some style issues, like how to ensure every document in a Sphinx Gallery has an appropriate image associated with it.
- It does not address how to incorporate the new RFC process with the documentation process.
- It does not address how to handle testing of documents and impact on CI.
- It does not address Incorporating accepted or completed RFCs into the documentation structure.
- It does not address the role of documentation in the CI/CD pipeline.