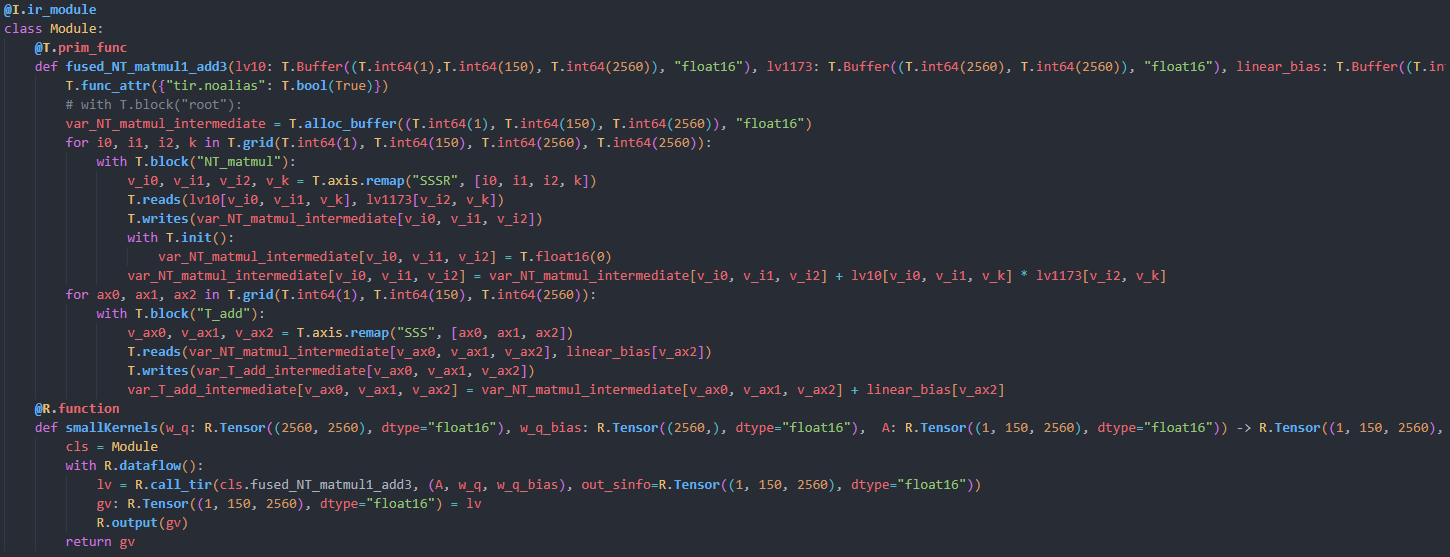
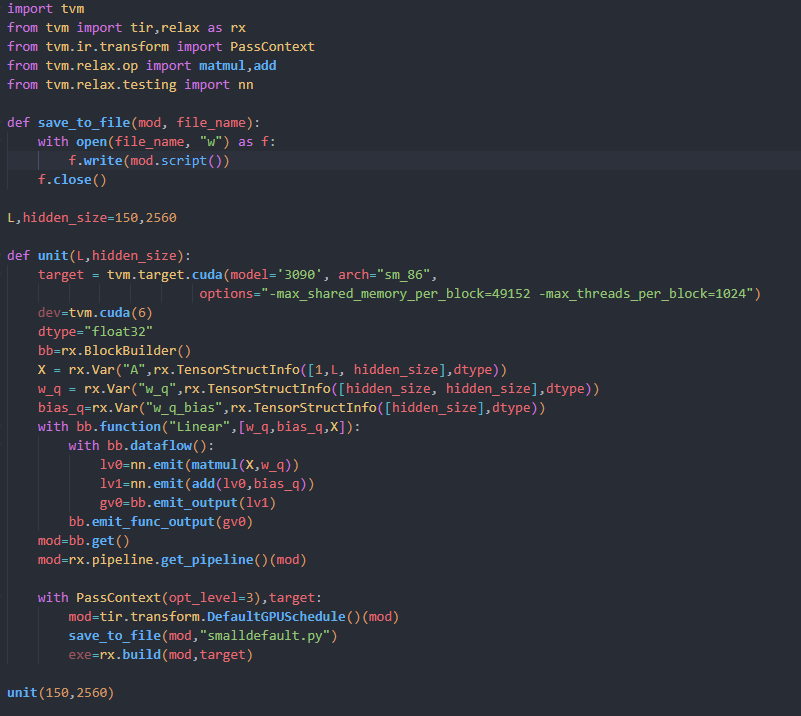
The module is doing Linear transform, and i dispatch it to pre-scheduled op in MLC-LLM dolly-v2-3b.
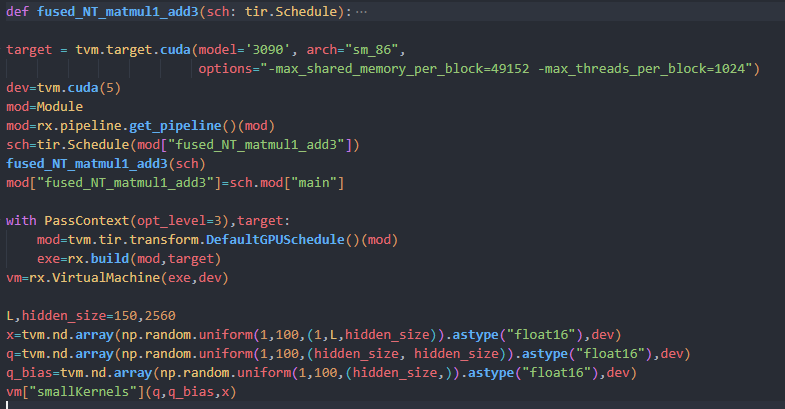
I profile it by using Nsight Compute run the script above.
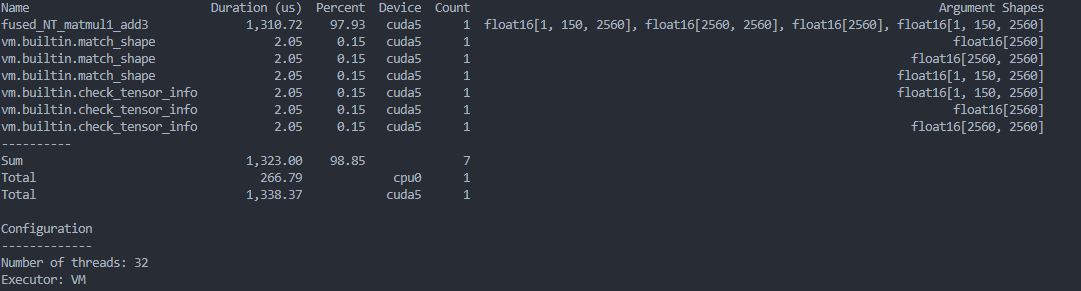
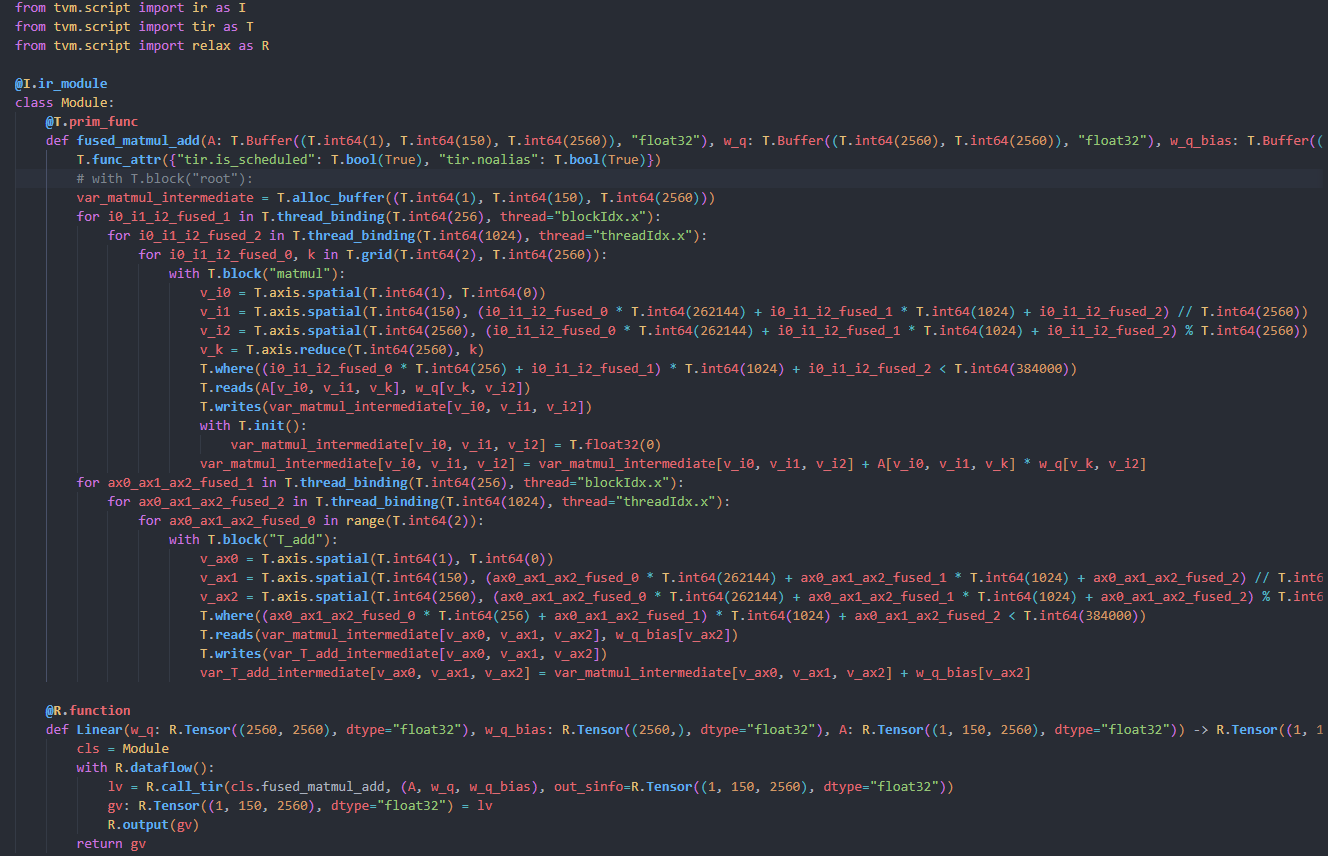
As a result of Nsight Compute,there are 5 kernels named fused_NT_matmul1_add3 generated in the profile report.
But in the script, i just do inference once, and the prim_func fused_NT_matmul1_add3 is only called once in relax_func smallLernels.Intuitively there should only be one cuda kernel.
It is quite confusing, could anyone help to explain why?
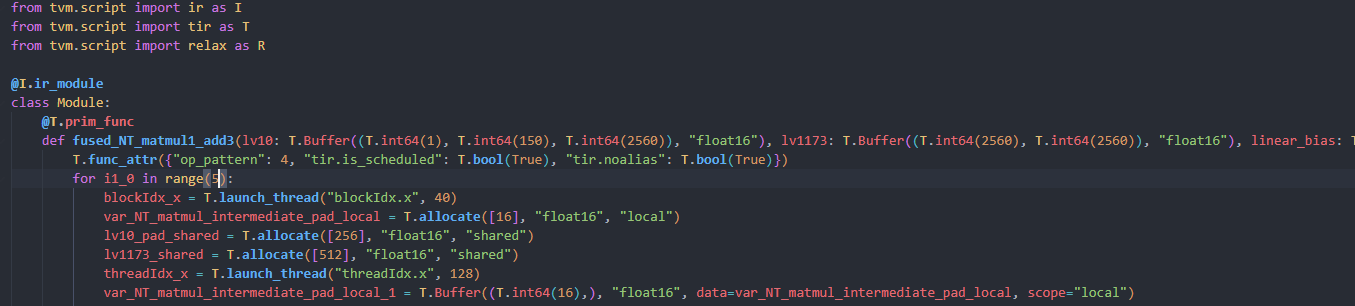
The code snippet above is part of lowered module TVM generated.
I think maybe it is because for i1_0 in range(5): and the generated cuda kernel is in the shape of <<40,128>>. Then it would be called 5 times in the cuda stream.
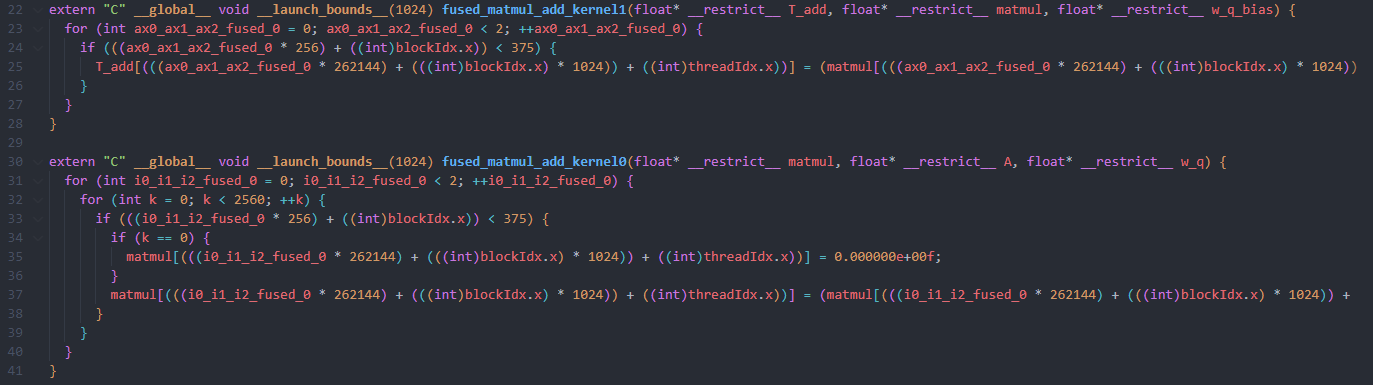
Above is the corresponding cuda source code. What confuse me is that there are actually two cuda kernel generated, fused_matmul_add_kernel0 is doing matmul and fused_matmul_add_kernel1 is doing add. Would it
be contrary to the original intention of Op fusion? Maybe there will be some performance loss?