I was bench-marking tvm and pytorch in terms of inference time and I see that tvm performance is almost 10x better than pytorch. I also compared predictions probability for each inference and it almost matches between tvm and pytorch. The inference time results looks very suspicious for me and I couldn’t figure out any issue in the my code. I thought it would be better to get tvm experts opinion on this.
Is it really possible to get this performance in tvm or something wrong in my code ?
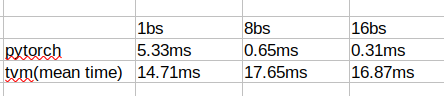
Here is the inference time results in ms with different batch-size(bs)
I am also running into problems with benchmarking. I am trying to measure inference on C++ and the problem is that there are no equivalent to module.benchmark. Is there a correct way to benchmark on C++ somewhere that we can replicate?
I just saw that you run on GPU. Shouldn’t you perform a GPU synchronization to measure time correctly? Like this example done with Torch?
You could try for TVM inference:
start = time.time()
module.run()
tvm.cuda().sync() #or something similar
end = time.time()
Took some time to evaluate different API’s available to calculate inference time in pytorch. It turns out that time difference varies a lot based on what API used in the calculation. Added https://github.com/manojec054/tvm-explore/blob/master/pytorch_benchmark_explore.py#L13 program to calculate matrix multiplication operation time and here is the result
Seems all the these results are not accurate. If you run nsys nvprof python3 pytorch_benchmark_explore.py you will the stats for the specific gemm kernel.
Using TIME API without SYNC is not correct. Using TORCH Profile, I’m not sure whether we should sum all the events. Also usually we need to have a large number of repeats inside the timing region.