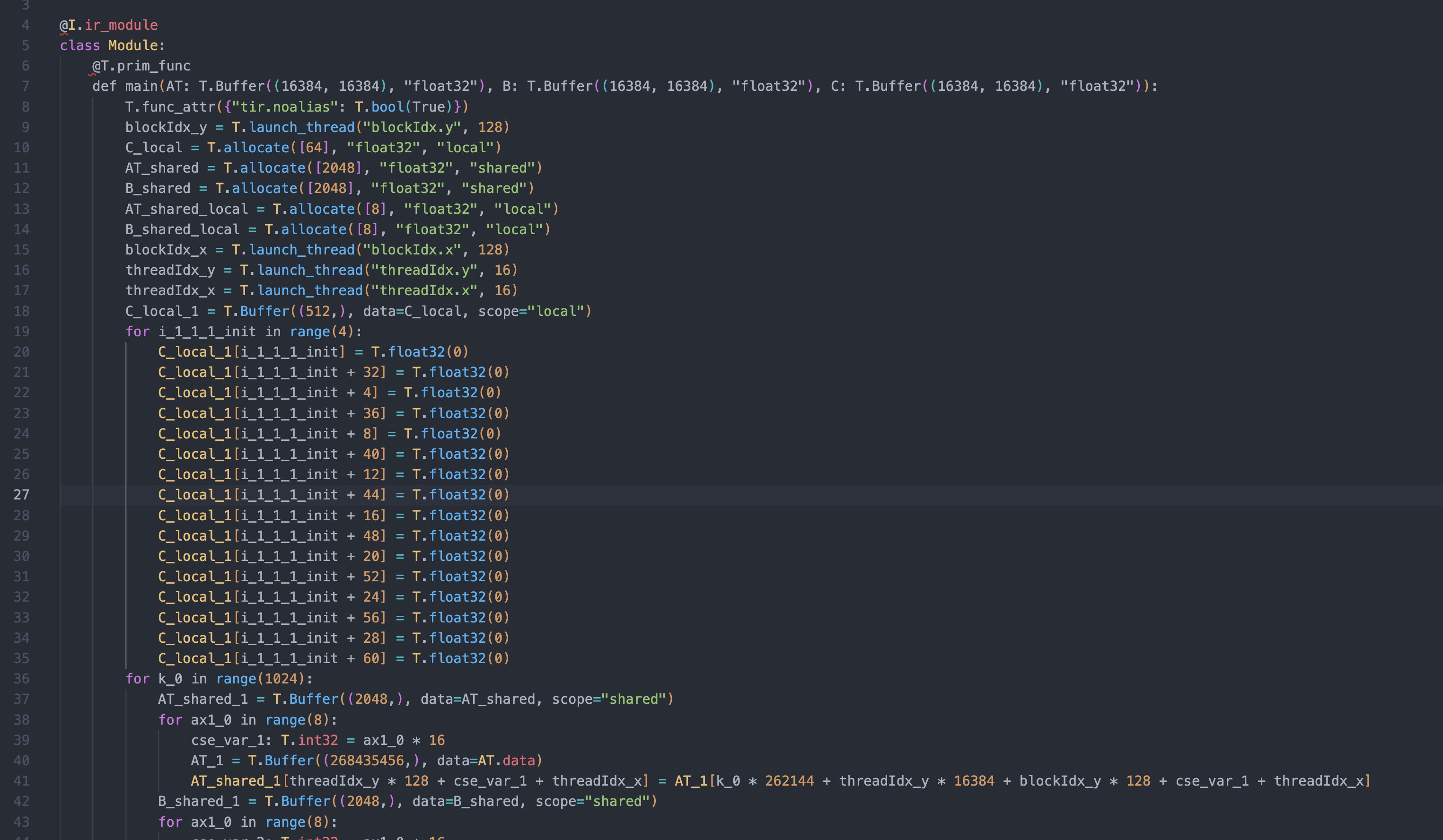
Hi, I am using tir.schedule to codegen an matmul gpu kernel 4096409616384 and implement warp tile, thread tile, cache read, cache write feature.
However the generated tvm.scirpt shows cache read A and shared memory size A, is 4096 * 16384. I believe there is a tir.transform in lower procedure, which adjust the cache_A to the acctually used size like 2048.
So, my question is can I declare smem size explicitly? And anyone can tell me which tir.transfrom it use to prune the sharedmem size.
before transform
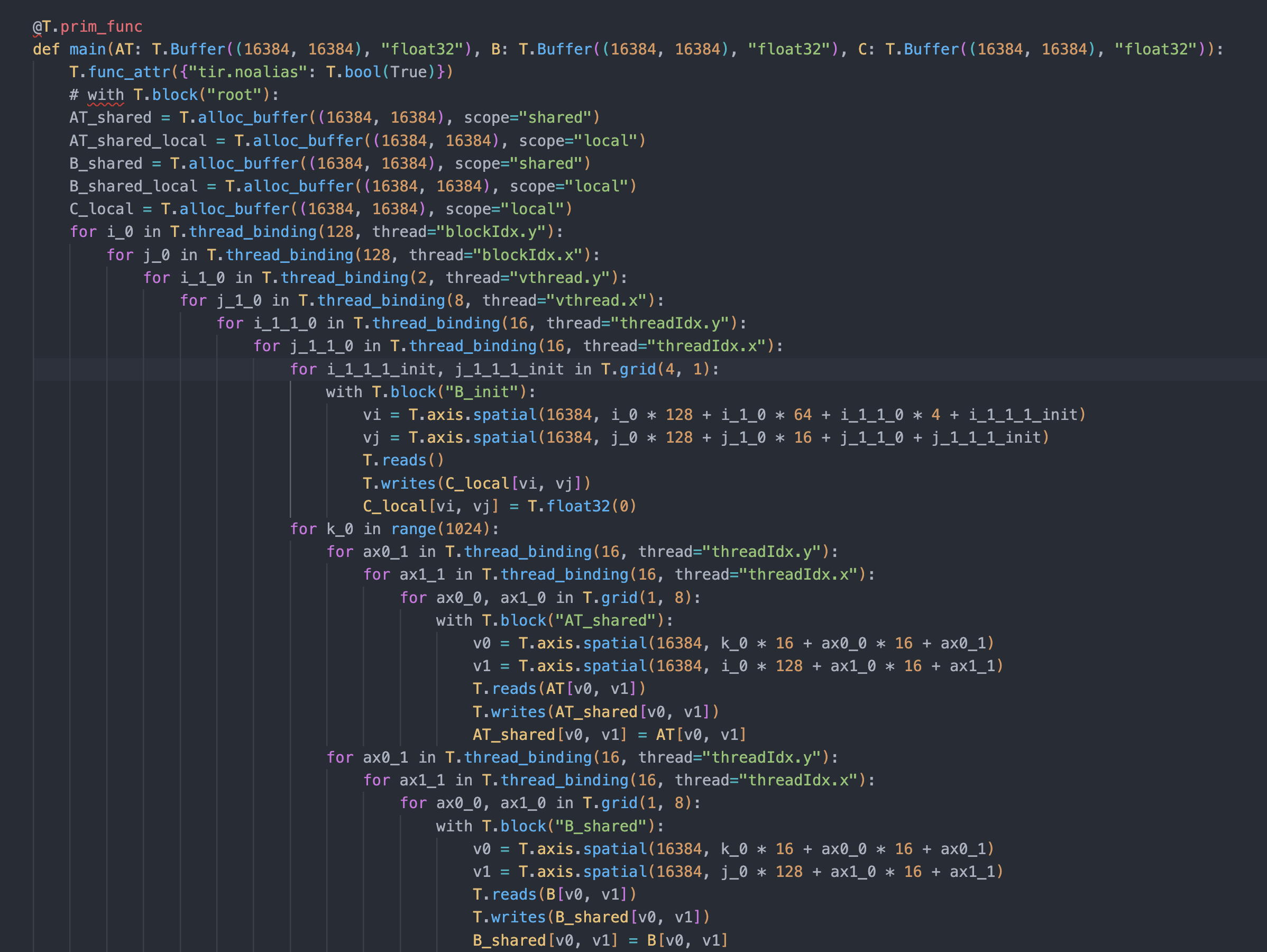
after transform