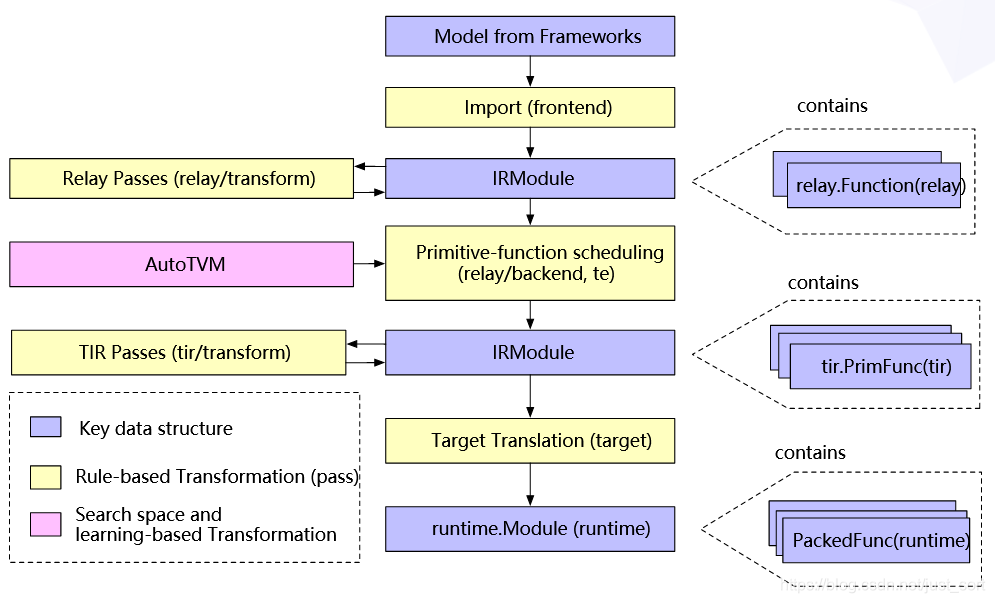
Hello everyone. I am learning tvm from the tutorials and other online blogs. I still have some questions about the complete compile flow of using it. Sorry this may be a little bit long.
In my mind, tvm reads a onnx/pytorch/tf model and turns it into Relay IR(which is just like a graph type without the exact realization code). Then tvm turns the IR into TE, and it will use AutoTVM to do the schedule. With the auto-scheduling result, the TE will be turned into TIR.(In the process it will do many passes). At last, TIR will be transformed into llvm or C or other source languages. We can use the result languages like llvm and transformed it into the instructions that can be run in my hardware(if it has a risc-v cpu).
Now here are my quesions.
Autotvm doesn’t need any infomation about my hardware, does it? I read the passage and blogs about Autotvm and they said this part doesn’t need any info about the hardware.
Does the llvm I generate have any infomation about my hardware?
(Well the third one is the most one I want to ask)
In the flow I discribed before, I notice that when we turn llvm to my instructions, I just need a parser or translator(which it is just like a stupid machine and it can even have no need to know what the llvm is doing). Therefore, I think it has no pass or optimize about the program, just a simple translator.
If my chip or hardware’s instructions set has one instruction, which is not simple risc-v one.(Here we can take Gemmini as an example, Gemmini has an instruction that control a operation of matrix multiplication, obviously this instruction doesn’t exist in the risc-v’s set).
Can autotvm be used to find an optimized result for this operation?
If the answer for 3rd question is YES, how can it do that when autotvm doesn’t know anything about our hardware. If the answer is NO, does it mean I can’t use autotvm for my own backend if the backend has any instruction defined by myself?(Usually, many accelerators have these kinds of instructions) .
Actually I think I haven’t understood the complete compile flow on my own backend(like Gemmini). Hope anyone can help me clear my confusion.
AutoTVM does not need hardware information for “tuning”. However, it depends on manually written template, which depends on the specific hardware. i.e., you may need to rewrite templates for all ops if you’d like to tune with AutoTVM
If you’d like to generate llvm intrinsic for your hardware, it may need to update the codegen, but it should be easy.
I don’t really know your meaning of the 3rd Question. My understanding is your hardware may have some tensorized instruction (e.g. Tensor Cores or AVX-512). If so, you have to write it in the template (explained in the answer to the 1st question) with tensorize intrinsics.
I think what I am confused about is just the right-side flow. And according to picture, I need to define new computing rules and new scheduling rules for my ops (like conv, relu, and including my own ops like I can fuse some of the operations into one op and I can make it as a new instruction for my backend). So the hand-write templates you mentioned are the same things as the rules in the picture, is this right?
For the answer of the 2nd question, here is my thinking. No matter what kind of code I want to generate for my hardware, it still has the information about my hardware. Then I just need to translate the code(like llvm intrinsic) into my own instructions from the set of hardware? In fact I am not sure how to use the generate code to control my hardware.
And thanks a lot for your answer. Yes it is what I mean and I am sorry about my pool description. So it means that I can use AutoTVM and even Ansor for these instructions’ scheduling and tuning, is it right?
First of all, we have three tuning systems in native TVM (I don’t know what’s ITRI, and it may not be in the upstream codebase):
AutoTVM: template-based tuning, need templates for each anchor operator
Ansor: template-free tuning, need schedule rules for a specific backend, but it’s hard to mutate ansor’s algorithm (at least it’s hard for me)
Meta-schedule: works for both template-based and template-free (rule-based) tuning based on TensorIR. Unfortunately, it has no documents yet, we are working on it.
You may still need an llvm compiler backend. TVM is a source-to-source compiler, but not designed to output assembler code directly.
If your instructions is a tensorized intrinsic (which computes a sub tensor instead of a scalar), AutoTVM and Meta-schedule works if you can write templates or rules, but Ansor does not support tensorized intrinsics.
Thanks for your answer. It helps me understand the compile flow a lot.
Actually I am trying to use tvm to compile a pytorch model for my backend hardware. The hardware in fact just has some instructions that can be sent by its cpu to control the registers.(I don’t even think they can be called as an instruction set). Therefore, I want to make it clear that how tvm’s flow works. According to your answers, I have my conclusion.
First, tvm takes in the pytorch model and turns it to IRmodule. Then I need to write some new templates to fit my backend’s performance.
Then the IR with the AutoTVM’s result will be lowered to Tensor IR(actually). After that I can use the TIR to generate into LLVM IR(llvm intrinsic), here I need to update the codegen of tvm. At last, maybe I can use an external llvm compiler to turn the llvm IR to the assembler code – my instructions to control the machine(of course I need to write a head file or sth like that to support the compile process).
In the whole flow, is the only backend information I give to tvm just the part of AutoTVM? It seems that if I don’t use autoTVM, tvm will have no idea what my backend is because I just need it to output the llvm intermediate representation.
Is this flow right? But in the flow there are still many details and how to update the flows and codegen is still a challenge for me but I will work hard to overcome.