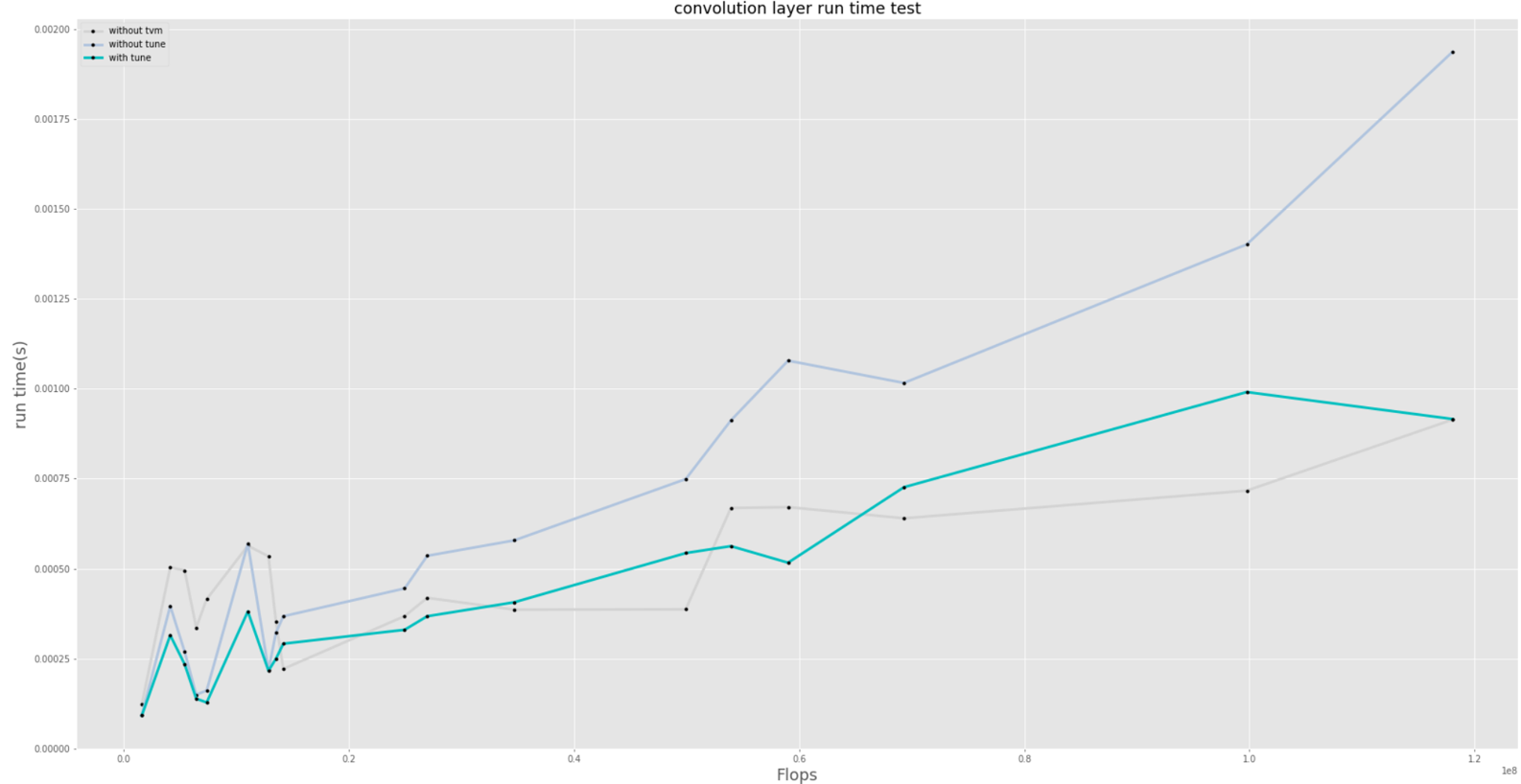
Hello Recently, I conducted tests on convolution layers with different core sizes, different input-output channel sizes and different input resolutions, respectively measuring their running time without TVM optimization, the time when they were converted to TVM but not scheduled, and the time when they were transferred to TVM and scheduled. Among them, four search methods are used respectively in scheduling and the one with the smallest running time of the results is retained. There is a strange phenomenon in the experimental results. When FLOPS exceed a certain value, TVM optimization slows down. The experimental platforms were Intel CPU, TVM 0.9, PyTorch 1.8.1, and Ubuntu 20.04. I got the same result on another computer. Has this happened to anyone? Please let me know if there is a solution, thank you!
The graph below shows the running time measured in three cases. The horizontal coordinate is flops, and the vertical coordinate is running time