
I’m using TVM’s BYOC approach to integrate TVM and TensorRT. But I observe a huge significant performance gap between them.
- Model: vae-decoder.
-
Precision: fp32, but I’ve set
TVM_TENSORRT_USE_FP16to 1. - Purely in TensorRT: ~34 ms.
The code to use TensorRT BYOC in TVM is like:
from tvm.relay.op.contrib import tensorrt
...
mod = tensorrt.partition_for_tensorrt(mod, params, target)
with tvm.transform.PassContext(opt_level=3):
lib = relay.build(mod, target="cuda", params=params)
# load parameters
dev = tvm.cuda(0)
module_exec = runtime.GraphModule(lib["default"](dev))
print(module_exec.benchmark(dev, number=1, repeat=10))
Benchmark Result:
Execution time summary:
mean (ms) median (ms) max (ms) min (ms) std (ms)
101.8611 101.3974 103.1465 101.3486 0.6918
Then, I use the following script to profile the partitioned mod(from TVMConf-2020-BYOC-Demo.py · GitHub):
def trt_profile_graph(func):
class OpProfiler(ExprVisitor):
def __init__(self):
super().__init__()
self.ops = {}
def visit_call(self, call):
op = call.op
if op not in self.ops:
self.ops[op] = 0
self.ops[op] += 1
super().visit_call(call)
def get_trt_graph_num(self):
cnt = 0
for op in self.ops:
if str(op).find("tensorrt") != -1:
cnt += 1
return cnt
profiler = OpProfiler()
profiler.visit(func)
log("Total number of operators: %d" % sum(profiler.ops.values()))
log("Detail breakdown")
for op, count in profiler.ops.items():
log("\t%s: %d" % (op, count))
log("TensorRT subgraph #: %d" % profiler.get_trt_graph_num())
The result shows that I have 42 subgraphs for TensorRT. I think that’s one reason why it is so slow compared with TensorRT(purely). And I get this idea from the article: Bring Your Own Codegen to Deep Learning Compiler.
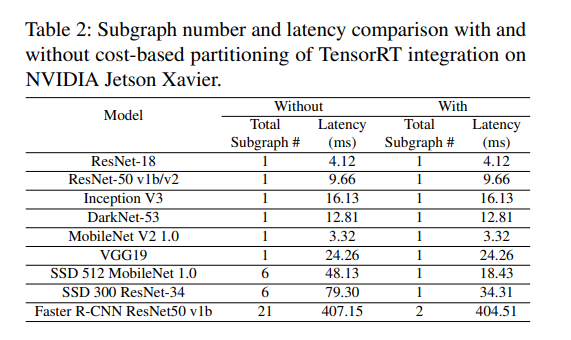
From this table, the fewer the number of subgraphs, the faster it is.
So I wonder if there is a way to reduce the number of subgraphs?