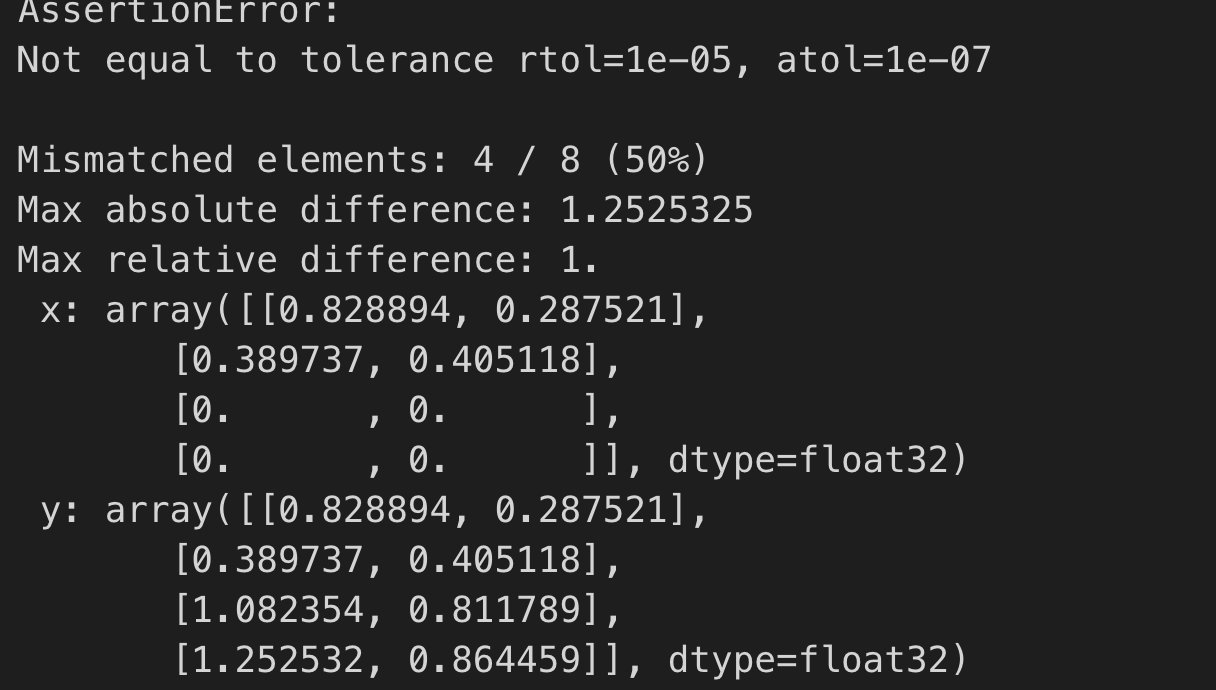
Code attached to reproduce this bug:
import tvm
from tvm import te
import numpy as np
import sys
from tvm import testing
# Fail case:
M, K, N = 4, 4, 2
A = te.placeholder((M, K), name='A')
B = te.placeholder((K, N), name='B')
k = te.reduce_axis((0, K), name='k')
C = te.compute((M, N), lambda i, j: te.sum(A[i, k] * B[k, j], axis=k), name='C')
s = te.create_schedule(C.op)
bn = 2
xo, yo, xi, yi = s[C].tile(C.op.axis[0], C.op.axis[1], bn, bn)
s[C].reorder(xo, yo, xi, yi, k)
s[C].parallel(xo)
def intrin_libxsmm(m, k, n):
a = te.placeholder((m, k), name='a')
b = te.placeholder((k, n), name='b')
k = te.reduce_axis((0, k), name='k')
c = te.compute((m, n), lambda i, j: te.sum(a[i, k] * b[k, j], axis=k), name='c')
a_buffer = tvm.tir.decl_buffer(a.shape, a.dtype, name='a_buffer', offset_factor=1, strides=[te.var('s1'), 1])
b_buffer = tvm.tir.decl_buffer(b.shape, b.dtype, name='b_buffer', offset_factor=1, strides=[te.var('s2'), 1])
c_buffer = tvm.tir.decl_buffer(c.shape, c.dtype, name='c_buffer', offset_factor=1, strides=[te.var('s3'), 1])
def intrin_func(ins, outs):
ib = tvm.tir.ir_builder.create()
ib.emit(
tvm.tir.call_packed(
"tvm.contrib.cblas.matmul", ins[0], ins[1], outs[0], False, False, 1.0, 0.0
)
)
return ib.get()
return te.decl_tensor_intrin(c.op, intrin_func, binds={a: a_buffer, b: b_buffer, c: c_buffer})
micro_kernel = intrin_libxsmm(bn, K, bn)
s[C].tensorize(xi, micro_kernel)
ctx = tvm.cpu(0)
func = tvm.build(s, [A, B, C], target='llvm')
a = tvm.nd.array(np.random.uniform(size=(M, K)).astype(A.dtype), ctx)
b = tvm.nd.array(np.random.uniform(size=(K, N)).astype(B.dtype), ctx)
c = tvm.nd.array(np.zeros((M, N), dtype=C.dtype), ctx)
func(a, b, c)
tvm.testing.assert_allclose(c.asnumpy(), np.dot(a.asnumpy(), b.asnumpy()), rtol=1e-5)