
As shown in the figure, there is the vm.builtin.alloc_tensor function between each operator, but my understanding is that this function only reuses the buffer of the StorageObj object and should not take so much time. How should I modify this to achieve high performance. Can anyone provide me with some help?
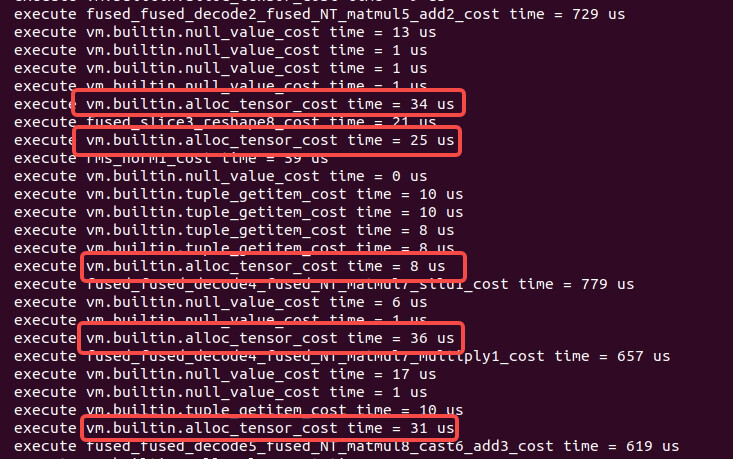
The buffer shape of alloc_tensor 36 us is [1,1,5504] * float16