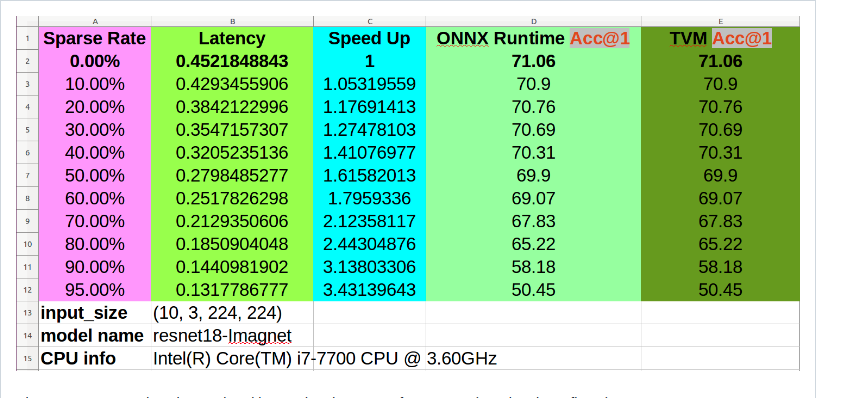
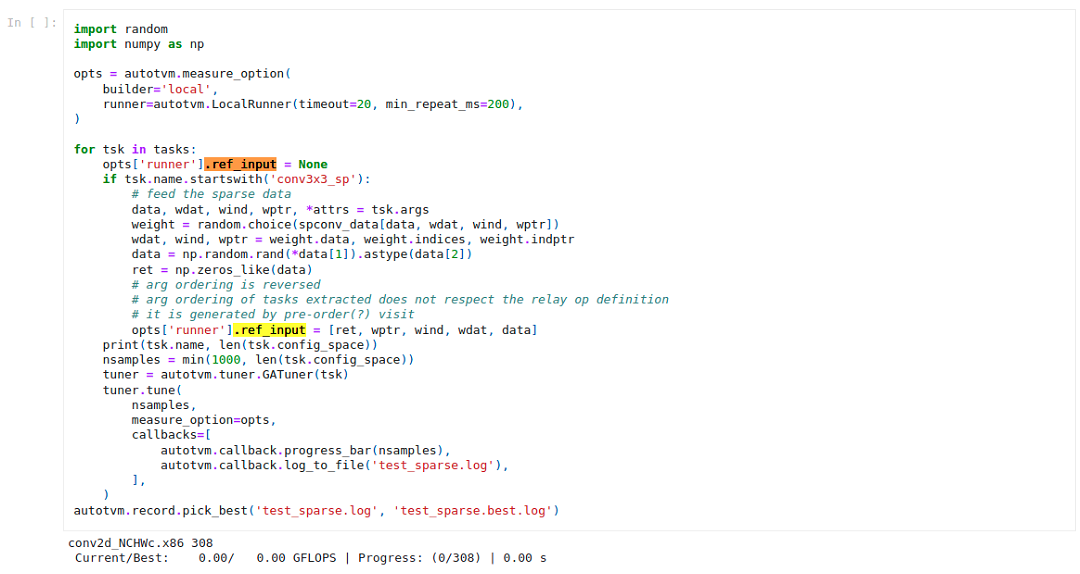
@Tantalus13A98B5F My computer dies when the first time I run the auto tuning cell and didn’t get the log file. So I adjust the nsamples and the LocalRunner’s timeout to half of it in the sample usage like this:
opts = autotvm.measure_option(
builder='local',
runner=autotvm.LocalRunner(timeout=10, min_repeat_ms=100),
)
nsamples = min(500, len(tsk.config_space))
Then I runs it again, and check the result after a night. Though it still seems to make my computer dead, I get the test_sparse.best.log this time. Do I need to show the log file for diagnostics?
After tuning, I test the runtime and compare with the dense version. And this time I get a better result that just a little bit slower then the dense version. Does it means that I can get the speedup if I get larger nsamples for tuning?
And here is my tuning result:
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:103: Iteration: 0
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #0 tvmgen_default_fused_layout_transform: 536.916 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #1 tvmgen_default_fused_nn_contrib_conv2d_NCHWc_add_nn_relu: 107332 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #2 tvmgen_default_fused_nn_max_pool2d: 2605.97 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #3 tvmgen_default_fused_layout_transform_1: 1879.01 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #4 tvmgen_default_fused_nn_sparse_conv2d_multiply_add_nn_relu: 109441 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #5 tvmgen_default_fused_nn_sparse_conv2d_multiply_add_add_nn_relu: 109260 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #6 tvmgen_default_fused_nn_sparse_conv2d_multiply_add_nn_relu_1: 106321 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #7 tvmgen_default_fused_nn_sparse_conv2d_multiply_add_add_nn_relu1: 109353 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #8 tvmgen_default_fused_layout_transform_2: 1130 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #9 tvmgen_default_fused_nn_contrib_conv2d_NCHWc_add_nn_relu_1: 32443.6 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #10 tvmgen_default_fused_layout_transform_3: 829.159 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #11 tvmgen_default_fused_layout_transform_4: 781.847 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #12 tvmgen_default_fused_nn_contrib_conv2d_NCHWc_add: 3953.99 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #13 tvmgen_default_fused_layout_transform_5: 658.711 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #14 tvmgen_default_fused_nn_sparse_conv2d_multiply_add_add_nn_relu_1: 104458 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #15 tvmgen_default_fused_nn_sparse_conv2d_multiply_add_nn_relu_2: 105394 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #16 tvmgen_default_fused_nn_sparse_conv2d_multiply_add_add_nn_relu_2: 100436 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #17 tvmgen_default_fused_layout_transform_6: 402.577 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #18 tvmgen_default_fused_nn_contrib_conv2d_NCHWc_add_nn_relu_2: 31527.2 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #19 tvmgen_default_fused_layout_transform_7: 184.404 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #20 tvmgen_default_fused_nn_contrib_conv2d_NCHWc_add_1: 3710.73 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #21 tvmgen_default_fused_layout_transform_71: 121.917 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #22 tvmgen_default_fused_nn_sparse_conv2d_multiply_add_add_nn_relu_3: 103666 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #23 tvmgen_default_fused_nn_sparse_conv2d_multiply_add_nn_relu_3: 103309 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #24 tvmgen_default_fused_nn_sparse_conv2d_multiply_add_add_nn_relu_4: 103671 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #25 tvmgen_default_fused_layout_transform_8: 218.042 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #26 tvmgen_default_fused_nn_contrib_conv2d_NCHWc_add_nn_relu_3: 31511.9 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #27 tvmgen_default_fused_layout_transform_9: 67.794 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #28 tvmgen_default_fused_layout_transform_10: 232.413 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #29 tvmgen_default_fused_nn_contrib_conv2d_NCHWc_add_2: 3610.98 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #30 tvmgen_default_fused_layout_transform_91: 57.2552 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #31 tvmgen_default_fused_nn_sparse_conv2d_multiply_add_add_nn_relu_5: 309960 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #32 tvmgen_default_fused_nn_sparse_conv2d_multiply_add_nn_relu_4: 307926 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #33 tvmgen_default_fused_nn_sparse_conv2d_multiply_add_add_nn_relu_51: 298952 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #34 tvmgen_default_fused_nn_adaptive_avg_pool2d: 91.7728 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #35 reshape_nop: 0.2193 us/iter
[12:57:28] /home/wsko/tvm/src/runtime/graph_executor/debug/graph_executor_debug.cc:108: Op #36 tvmgen_default_fused_nn_dense_add: 276.49 us/iter
Node Name Ops Time(us) Time(%) Shape Inputs Outputs
--------- --- -------- ------- ----- ------ -------
tvmgen_default_fused_nn_sparse_conv2d_multiply_add_add_nn_relu_5 tvmgen_default_fused_nn_sparse_conv2d_multiply_add_add_nn_relu_5 309960.0 14.113 (10, 512, 7, 7) 7 1
tvmgen_default_fused_nn_sparse_conv2d_multiply_add_nn_relu_4 tvmgen_default_fused_nn_sparse_conv2d_multiply_add_nn_relu_4 307926.0 14.02 (10, 512, 7, 7) 6 1
tvmgen_default_fused_nn_sparse_conv2d_multiply_add_add_nn_relu_51 tvmgen_default_fused_nn_sparse_conv2d_multiply_add_add_nn_relu_5 298952.0 13.612 (10, 512, 7, 7) 7 1
tvmgen_default_fused_nn_sparse_conv2d_multiply_add_nn_relu tvmgen_default_fused_nn_sparse_conv2d_multiply_add_nn_relu 109441.0 4.983 (10, 64, 56, 56) 6 1
tvmgen_default_fused_nn_sparse_conv2d_multiply_add_add_nn_relu1 tvmgen_default_fused_nn_sparse_conv2d_multiply_add_add_nn_relu 109353.0 4.979 (10, 64, 56, 56) 7 1
tvmgen_default_fused_nn_sparse_conv2d_multiply_add_add_nn_relu tvmgen_default_fused_nn_sparse_conv2d_multiply_add_add_nn_relu 109260.0 4.975 (10, 64, 56, 56) 7 1
tvmgen_default_fused_nn_contrib_conv2d_NCHWc_add_nn_relu tvmgen_default_fused_nn_contrib_conv2d_NCHWc_add_nn_relu 107332.0 4.887 (10, 2, 112, 112, 32) 3 1
tvmgen_default_fused_nn_sparse_conv2d_multiply_add_nn_relu_1 tvmgen_default_fused_nn_sparse_conv2d_multiply_add_nn_relu_1 106321.0 4.841 (10, 64, 56, 56) 6 1
tvmgen_default_fused_nn_sparse_conv2d_multiply_add_nn_relu_2 tvmgen_default_fused_nn_sparse_conv2d_multiply_add_nn_relu_2 105394.0 4.799 (10, 128, 28, 28) 6 1
tvmgen_default_fused_nn_sparse_conv2d_multiply_add_add_nn_relu_1 tvmgen_default_fused_nn_sparse_conv2d_multiply_add_add_nn_relu_1 104458.0 4.756 (10, 128, 28, 28) 7 1
tvmgen_default_fused_nn_sparse_conv2d_multiply_add_add_nn_relu_4 tvmgen_default_fused_nn_sparse_conv2d_multiply_add_add_nn_relu_4 103671.0 4.72 (10, 256, 14, 14) 7 1
tvmgen_default_fused_nn_sparse_conv2d_multiply_add_add_nn_relu_3 tvmgen_default_fused_nn_sparse_conv2d_multiply_add_add_nn_relu_3 103666.0 4.72 (10, 256, 14, 14) 7 1
tvmgen_default_fused_nn_sparse_conv2d_multiply_add_nn_relu_3 tvmgen_default_fused_nn_sparse_conv2d_multiply_add_nn_relu_3 103309.0 4.704 (10, 256, 14, 14) 6 1
tvmgen_default_fused_nn_sparse_conv2d_multiply_add_add_nn_relu_2 tvmgen_default_fused_nn_sparse_conv2d_multiply_add_add_nn_relu_2 100436.0 4.573 (10, 128, 28, 28) 7 1
tvmgen_default_fused_nn_contrib_conv2d_NCHWc_add_nn_relu_1 tvmgen_default_fused_nn_contrib_conv2d_NCHWc_add_nn_relu_1 32443.6 1.477 (10, 2, 28, 28, 64) 3 1
tvmgen_default_fused_nn_contrib_conv2d_NCHWc_add_nn_relu_2 tvmgen_default_fused_nn_contrib_conv2d_NCHWc_add_nn_relu_2 31527.2 1.435 (10, 8, 14, 14, 32) 3 1
tvmgen_default_fused_nn_contrib_conv2d_NCHWc_add_nn_relu_3 tvmgen_default_fused_nn_contrib_conv2d_NCHWc_add_nn_relu_3 31511.9 1.435 (10, 16, 7, 7, 32) 3 1
tvmgen_default_fused_nn_contrib_conv2d_NCHWc_add tvmgen_default_fused_nn_contrib_conv2d_NCHWc_add 3953.99 0.18 (10, 4, 28, 28, 32) 3 1
tvmgen_default_fused_nn_contrib_conv2d_NCHWc_add_1 tvmgen_default_fused_nn_contrib_conv2d_NCHWc_add_1 3710.73 0.169 (10, 8, 14, 14, 32) 3 1
tvmgen_default_fused_nn_contrib_conv2d_NCHWc_add_2 tvmgen_default_fused_nn_contrib_conv2d_NCHWc_add_2 3610.98 0.164 (10, 16, 7, 7, 32) 3 1
tvmgen_default_fused_nn_max_pool2d tvmgen_default_fused_nn_max_pool2d 2605.97 0.119 (10, 2, 56, 56, 32) 1 1
tvmgen_default_fused_layout_transform_1 tvmgen_default_fused_layout_transform_1 1879.01 0.086 (10, 64, 56, 56) 1 1
tvmgen_default_fused_layout_transform_2 tvmgen_default_fused_layout_transform_2 1130.0 0.051 (10, 2, 56, 56, 32) 1 1
tvmgen_default_fused_layout_transform_3 tvmgen_default_fused_layout_transform_3 829.159 0.038 (10, 128, 28, 28) 1 1
tvmgen_default_fused_layout_transform_4 tvmgen_default_fused_layout_transform_4 781.847 0.036 (10, 8, 56, 56, 8) 1 1
tvmgen_default_fused_layout_transform_5 tvmgen_default_fused_layout_transform_5 658.711 0.03 (10, 128, 28, 28) 1 1
tvmgen_default_fused_layout_transform tvmgen_default_fused_layout_transform 536.916 0.024 (10, 1, 224, 224, 3) 1 1
tvmgen_default_fused_layout_transform_6 tvmgen_default_fused_layout_transform_6 402.577 0.018 (10, 4, 28, 28, 32) 1 1
tvmgen_default_fused_nn_dense_add tvmgen_default_fused_nn_dense_add 276.49 0.013 (10, 1000) 3 1
tvmgen_default_fused_layout_transform_10 tvmgen_default_fused_layout_transform_10 232.413 0.011 (10, 8, 14, 14, 32) 1 1
tvmgen_default_fused_layout_transform_8 tvmgen_default_fused_layout_transform_8 218.042 0.01 (10, 1, 14, 14, 256) 1 1
tvmgen_default_fused_layout_transform_7 tvmgen_default_fused_layout_transform_7 184.404 0.008 (10, 256, 14, 14) 1 1
tvmgen_default_fused_layout_transform_71 tvmgen_default_fused_layout_transform_7 121.917 0.006 (10, 256, 14, 14) 1 1
tvmgen_default_fused_nn_adaptive_avg_pool2d tvmgen_default_fused_nn_adaptive_avg_pool2d 91.773 0.004 (10, 512, 1, 1) 1 1
tvmgen_default_fused_layout_transform_9 tvmgen_default_fused_layout_transform_9 67.794 0.003 (10, 512, 7, 7) 1 1
tvmgen_default_fused_layout_transform_91 tvmgen_default_fused_layout_transform_9 57.255 0.003 (10, 512, 7, 7) 1 1
reshape_nop __nop 0.219 0.0 (10, 512) 1 1
Total_time - 2196311.897 - - - -