1. Summary
Goal of this document is to describe the design of MSC (Multi-System Compiler) and how it benefits the tvm in model optimization. MSC is designed to connect tvm with other machine learning frameworks (e.g. torch, tensorflow, tensorrt…) and systems (e.g. training system, deployment system…). With the help of MSC, model compression methods can be developed, such as advanced PTQ (post train quantization), QAT (quantization awared training), prune training, sparse training, knowledge distilliation, and so on. Besides, MSC manage the model compiling process as a pipeline, so that model compiling services (Saas) and compiling tool-chain can be easily built base on MSC.
MSC is used as an important part of AI Engine at NIO.Inc. Introduction can be found @ TVMConf 2023(TVM @ NIO).
This open source version MSC different with the MSC @ NIO.Inc as following:
A.The optimization for runtime and quantization in NIO will not be included in this open source version.
B.This version use relax and relay to build MSCGraph, while in NIO only relay is used.
C.This version focus on auto compression and training related optimization methods, while Ai Engine @ NIO focus more on runtime acceleration and auto driving related quantization.
2. Motivation
With the optimization of TVM, model performance and memory management has reached a relative high level. To improve the model performance to a higher level and meanwhile ensure the accuracy, new methods are needed. The model compression technology is proved to be useful in increasing the model performance and meanwhile decreasing the memory consumption. Normal compression methods such as pruning and quantization need cooperation of algorithm, software and hardware systems, which make the compression strategy difficult to be developed and maintained, because information format differs from system to system, and compression strategy differs from case to case. To cooperate with different systems and develop compression algorithms as model-free tools, an architecture for saving, passing, and transforming information is needed.
3. Guide-level explanation
3.1 MSCGraph
MSCGraph is core of MSC, it works like IR to compiler. MSCGraph is a DAG format of Relax.Function/Relay.Function. It can be transformed to and from Relax/Relay. Goal of building MSCGraph is to make development of compression algorithm and weights management (this is important when training) easier. A Relax/Relay module has more than one MSCGraphs if not all the Calls can be supported on chosen runtime target.
from tvm.contrib.msc.core.ir import graph_translator
# build msc graph from relax
graph = graph_translator.from_relax(mod, params, entry_name)
print(graph)
# this will export serialization file for load the graph
graph.export("graph", params=params)
# this will export prototxt file for visualize
graph.visualize("graph.prototxt")
# build msc graph to relax
module = graph_translator.to_relax(graph, params)
assert_same(mod[entry_name], module["main"])
Differences bewteen MSCGraph and Relex are:
- MSCGraph has DAG format while Relax has Expression format.
- MSCGraph classify tensors into input and weight, while Relex define tensors as var and constant.
- MSCGraph use node name (conv1, layer1.conv1…) as main id for searching nodes, while Relax use index with prefix (lvXX, gv).
3.2 RuntimeManager
The RuntimeManager connect MSCGraph(s) with different frameworks, it wraps some common used methods and manage MSCTools (see 3.3 MSCTools).
from tvm.contrib.msc.core.transform import msc_transform
from tvm.contrib.msc.core.runtime import create_runtime_manager
from tvm.contrib.msc.core.tools import create_tool, MSC_TOOL
# build runtime manager from module and mscgraphs
optimized_mod, msc_graph, msc_config = msc_transform(mod, params)
rt_manager = create_runtime_manager(optimized_mod, params, msc_config)
rt_manager.create_tool(MSC_TOOL.QUANTIZE, quantize_config)
quantizer = rt_manager.get_tool(MSC_TOOL.QUANTIZE)
rt_manager.load_model()
# calibrate the datas with float model
while not quantizer.calibrated:
for datas in calibrate_datas:
rt_manager.run(datas)
quantizer.calibrate()
quantizer.save_strategy(strategy_file)
# load again the quantized model, without loading the weights
rt_manager.load_model(reuse_weights=True)
outputs = rt_manager.run(sample_datas)
3.3 MSCTools
MSCTools work together with MSCGraph, they decide the compression strategy and control the compression process. MSCTools are managed by RuntimeManager.
from tvm.contrib.msc.core.transform import msc_transform
from tvm.contrib.msc.core.runtime import create_runtime_manager
from tvm.contrib.msc.core.tools import create_tool, MSC_TOOL
# build runtime manager from module and mscgraphs
optimized_mod, msc_graph, msc_config = msc_transform(mod, params)
rt_manager = create_runtime_manager(optimized_mod, params, msc_config)
# pruner is used for prune the model
rt_manager.create_tool(MSC_TOOL.PRUNE, prune_config)
# quantizer is used to do the calibration and quantize the model
rt_manager.create_tool(MSC_TOOL.QUANTIZE, quantize_config)
# collecter is used to collect the datas of each computational node
rt_manager.create_tool(MSC_TOOL.COLLECT, collect_config)
# distiller is used to do the knowledge distilliation
rt_manager.create_tool(MSC_TOOL.DISTILL, distill_config)
3.4 MSCProcessor
The MSCProcessor build pipelines for the compiling process. A compiling process may include different stages, each has special config and strategy. To make the compiling process easy to be managed, MSCProcessor is created.
from tvm.contrib.msc.pipeline import create_msc_processor
# get the torch model and config
model = get_torch_model()
config = get_msc_config()
processor = create_msc_processor(model, config)
if mode == "deploy":
processor.compile()
processor.export()
elif mode == "optimize":
model = processor.optimize()
for ep in EPOCHS:
for datas in training_datas:
train_model(model)
processor.update_weights(get_weights(model))
processor.compile()
processor.export()
Config can be loaded from file, so that compiling can be controlled, recorded and replayed. This is essential for building compiling service and platform.
{
"workspace": "msc_workspace",
"verbose": "runtime",
"log_file": "MSC_LOG",
"baseline": {
"check_config": {
"atol": 0.05
}
},
"quantize": {
"strategy_file": "msc_quantize.json",
"target": "tensorrt",
},
"profile": {
"repeat": 1000
},
...
}
3.5 MSCGym
MSCGym is the platform for auto compression in MSC. It plays a role like AutoTVM, but the architecture is more like OpenAI-Gym. MSCGym extract tasks from compression process. It then use interaction between agent and environment to find the best action for each task. To use MSCGym for auto compression, set the gym config for tool:
{
...
"quantize": {
"strategy_file": "msc_quantize.json",
"target": "tensorrt",
“gym”:[
{
“record”:”searched_config.json”,
“env”:{
“strategy”:”distill_loss”
},
“agent”:{
“type”:”grid_search”,
}
},
]
},
...
}
4. Reference-level explanation
The compiling pipeline in MSC is show below:
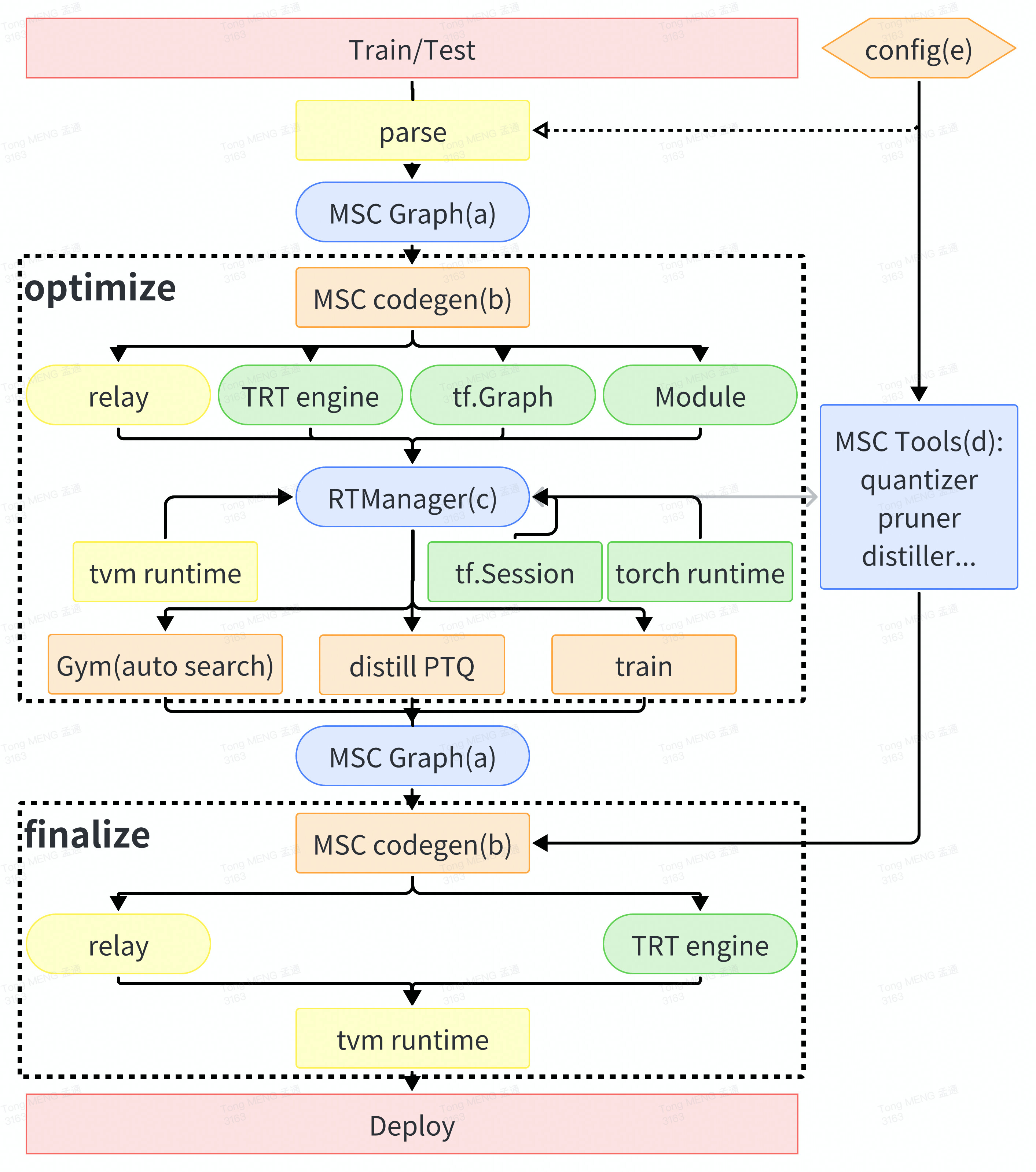
4.1 Core concepts:
MSCGraph: The core IR of MSC. MSCGraph is DAG format of Relax.Function/Relay.Function.
MSC codegen: Generate model building codes (include MSCTool controlling wrappers) for frameworks.
RuntimeManager: The abstract module to manage runtime, MSCGraphs and MSCTools.
MSCTools: The tools that decide compression strategy and control the compression process. Besides, some extra tools are added to MSCTools for debugging.
Config: MSC use config to control the compiling process. That makes the compliing process easy to be recorded and replayed.
4.2 Compiling process:
The compiling process consist of 2 main phases: optimize and finalize.
Optimize phase is used to optimize the model via compression. This phase may use training frameworks and consumes a lot of time and resource (e.g. auto compression, knowledeg distilliation and training).
Finalize phase is used to build the model in required environments. This phase starts with optimized relax module (checkpoint) and build the module in target environment, without any optimization. This phase can be processed in required environments without consume lot of time and resource.
5. Drawbacks
5.1 Extra maintain cost for using Relax-base methods
To keep the compiling pipeline simple and easy to be control, all compiling process in MSC use MSCGraph as the core IR. That means a translator between MSCGraph and Relax is needed to use Relax-based methods, which lead to extra maintain cost.
5.2 Extra develop cost for compression algorithm
The develop of compression algorithm in MSC differs from normal compression frameworks (e.g. NNI). MSCTool separates the algorithm into decision making and method implementation parts. The decision making is based on MSCGraph while methods are implemented base on frameworks (e.g. use torch.Tensor or tvm.Call to quantize a tensor). That leads to extra cost for developing compression algorithm in MSC.
6. Rationale and alternatives
MSC can use abilities from different frameworks, and meanwhile use compiler structure from tvm. That enables the tvm with some features like:
6.1 microsoft nni
MSC can be used like compression frameworks, like microsoft nni.
6.2 polygraphy
With the debug tool in MSCTools, MSC can trace behavior of all the nodes in MSCGraph. When targeting on TensorRT deployment, the MSC can be used like polygraphy.
7. Prior art
MSCTools:Abstract module for manage the compression algorithm. Once an algorithm is implemented, it can be used in different frameworks. Maintain cost is much less for compression algorithms in compare to other compression frameworks.
MSCGym:Plays a role like the AutoTVM. It finds the best strategy for compression automatically. That gives trade-off solutions for model compression if training system is unavailable.
MSCProcessor: A pipeline manager for compiling process. It separates the resource depend phase and environment depend phase. In that way user can use suitable machines for different phase.
8. Milestone
[M0] Build MSCGraph core parts. Enable translation between Relay, Relax and MSCGraph without lossing information.
[M1] Finish RuntimeManager for relax, and torch, so that a compiling process can be test based on MSCGraph.
[M2] Use MSCProcessor to manage the compiling pipeline. Add pruner, prune the graph by given density.
[M3] Add MSCGym, enable auto pruning process. Add distiller, enable knowledge distilliation for pruning.
[M5] Add quantizer and collecter for quantization and debugging.
[M6][Optional] Add MSCWrapper as compression toolchain. MSCWrappers are wrapper format of MSCProcessor, which can be used to wrap and optimize the models in training system.
[M7][Optional] Add MSC_PIPE for Saas. Build a local service and client for test the Saas
…to be continued…