UMA: Universal Modular Accelerator Interface
Feature Name: Universal Modular Accelerator Interface (UMA)
Start Date: 2022 February
Authors:
Paul Palomero Bernardo @paulpb, Christoph Gerum @cgerum - University of Tübingen
Michael J. Klaiber @mjklaiber, Ingo Feldner - Bosch Research
Philipp van Kempen @philippvk, Rafael Stahl @r.stahl, Daniel Müller-Gritschneder - Technical University of Munich
Johannes Partzsch - TU Dresden
Andrew Stevens - Infineon Technologies
RFC PR: https://github.com/apache/tvm-rfcs/pull/60
GitHub Issue: TBD
Summary

The goal of UMA (Universal Modular Accelerator Interface) is to create a unified infrastructure for easily integrating external accelerators into TVM. UMA provides file structures, Python interface classes and an API for accelerator integration. These interfaces and API are accessible from Python and are part of the components UMA Partitioner, UMA Lower and UMA Codgen. The features and proposals of Target registered compiler flow customization [TVM-RFC0011] and [TVM-RFC0010] are considered, with the difference that UMA tries to provide a more general interface for integrating new accelerators and one specific implementation of the hooks described in [TVM-RFC0011].
Image Source: Uma Thurman is The Bride | Pictured: Uma Thurman in a scene … | Flickr under CC BY-NC-ND 2.0
Update (2022-03-07):
The text below is the initial version of this pre-RFC. The changes resulting from this discussion thread can be found here: https://github.com/boschresearch/tvm-rfcs/blob/rfc_uma/rfcs/00xx_UMA_Unified_Modular_Accelerator_Interface.md
Motivation
A number of accelerators have already been integrated into TVM, e.g. VTA, ARM EthosU. These are similar in both the structure of their build flow and the operations that they can offload. Nonetheless, due to incremental independent development, the TVM interfaces and processing steps used are quite different with little commonality. A consistent, unified, infrastructure would simplify accelerator integration making it accessible to smaller, hardware-focused, development teams.
Focus
UMA’s primary objective is to enable straight-forward TVM integration of loosely-coupled processor/microcontroller controlled accelerators. That is, accelerators capable of executing complete tensor operations or operation-graphs without host processor intervention. Secondary objectives are:
- Support for closely-coupled accelerators (those offload parts of CPU computation for significant elements of tensor operations)
- Compatibility with both run-time or ahead-of-time compilation
- Support for heterogeneous execution utilizing accelerators optimized for specific operations or data types
Accelerator support or optimization functions outside the scope of UMA are:
- Parallel execution on multi-accelerator architectures (to be handled by executor/run-time and customized layer splitting)
- Real-time execution (to be handled by executor/run-time)
- High-level support for parameter conversion like quantization or sparsity exploitation (to be realized via model pre-processing or in accelerator backends)
Reference-level explanation
Flow description
The figure below describes the UMA interface from a top level. An Accelerator Partitioner which is a specialization of the UMA Partitioner takes the Relay graph and matches for supported and unsupported operators. Unsupported operators are processed with the default TVM flow. Supported operator are processed with UMA Pipeline. In the following the tasks and the functionality of each block in the figure below is described:
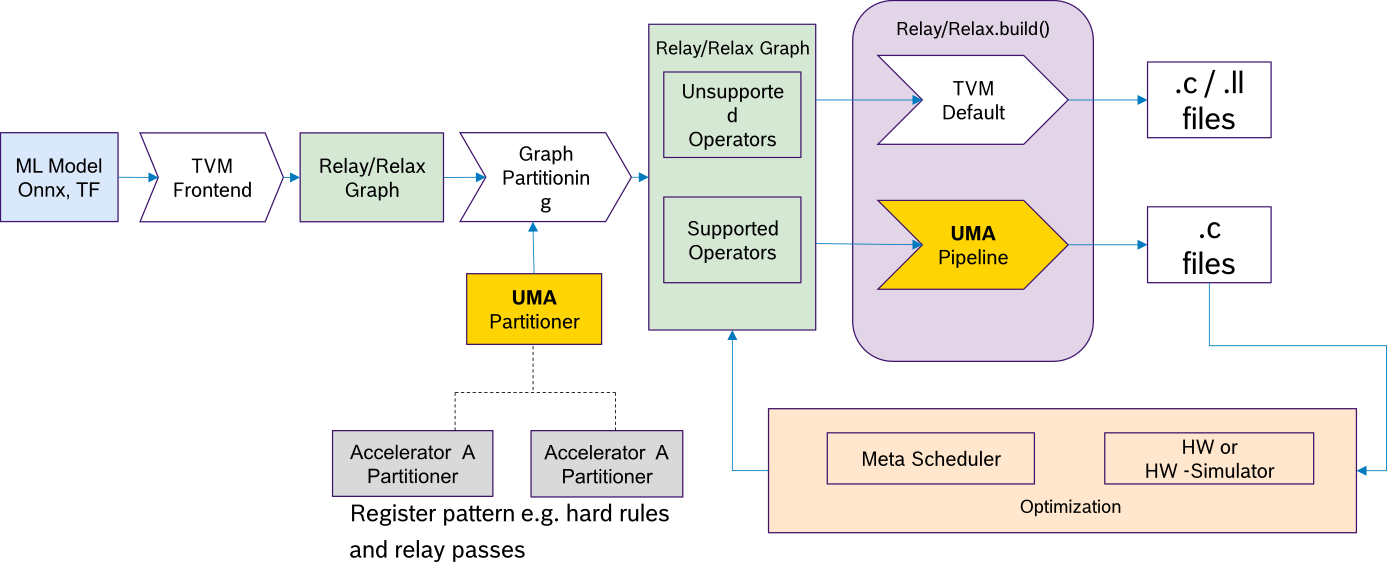
UMA Partitioning:
- Register relay passes
- Register patterns - supported sub-graph operations
- Order: pre-partitioning passes, Graph partitioning, post-partitioning passes
- UMAPartitioner baseclass (Python only) has to be inherited by accelerator-specific Partitioners (e.g. Accelerator A Partitioner, etc)
The figure below described the UMA Pipeline. The blocks are described below:
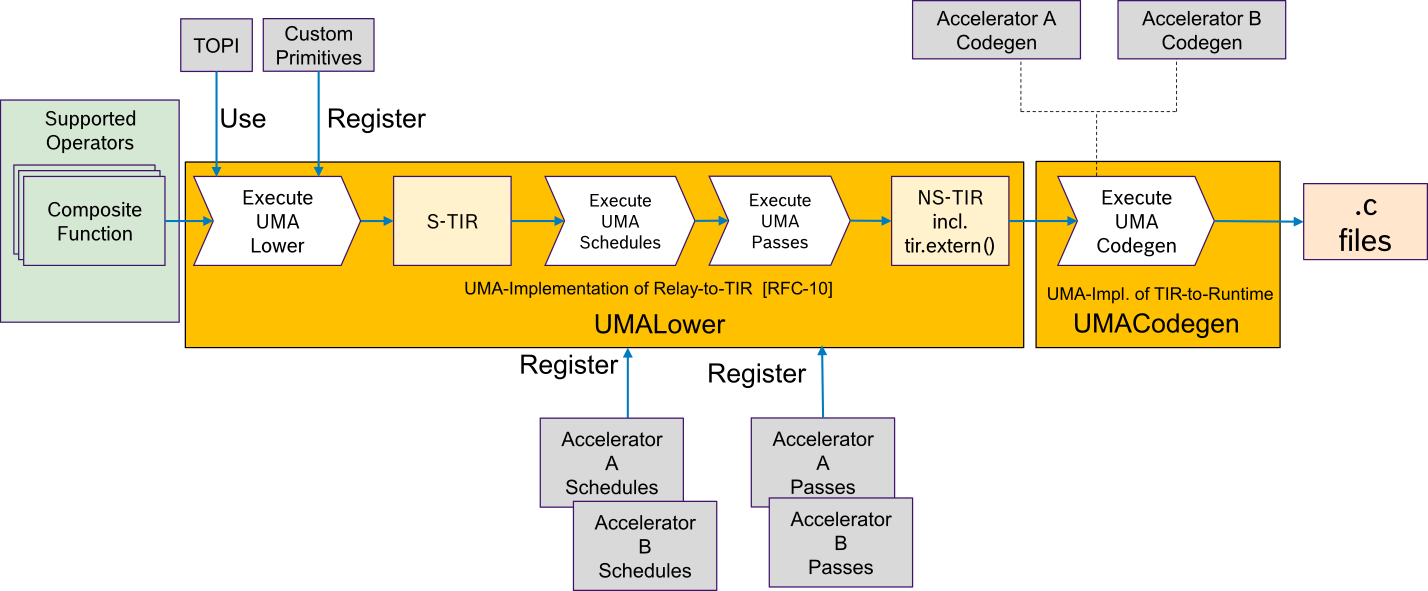
UMA Pipelining:
- Consists of UMALower and UMACogen, which implement the target hook Relay-to-TIR and TIR-to-Runtime (proposed in [TVM-RFC0010])
- UMALower
- Input: Partitioned composite functions
- Custom primitives can be registered
- Lowering from Relay to S-TIR, using TOPI or custom primitives
- Interface for registering accelerator-specific schedules and passes
- Execution of UMA schedules and passes on S-TIR
- Output: NS-TIR(including tir.extern calls)
- UMALower baseclass (Python only) has to be inherited by accelerator-specific Lower classes (e.g. Accelerator A Lower, etc)
- UMACodegen
- Input: NS-TIR(including tir.extern calls)
- Defaults to standard TVM codegen
- Intend is to provide a Python interface to insert/emit target code
- UMACodegen baseclass has to be inherited by accelerator-specific Codegen classes (e.g. Accelerator A Codegen, etc)
- Output: Target .c files
The intention is to use TensorIR and Relax with MetaScheduler for optimization.
Abbreviations: S-TIR: Schedulable TIR NS-TIR: Non-Schedulable TIR
File and class structure and Snippets as example for integration
UMA provides a mostly python-based API. On the C++ side, new targets are registered using target hooks (RFC #0010). A generic codegen.cc handles the calls to the python side.
.
├── codegen.cc
└── targets.cc
TVM_REGISTER_TARGET_KIND("accelerator_A", kDLCPU)
.set_attr<FTVMRelayToTIR>("RelayToTIR", relay::contrib::generic::RelayToTIR("accelerator_A"))
.set_attr<FTVMTIRToRuntime>("TIRToRuntime", relay::contrib::generic::accelerator_A::TIRToRuntime);
TVM_REGISTER_TARGET_KIND("accelerator_B", kDLCPU)
.set_attr<FTVMRelayToTIR>("RelayToTIR", relay::contrib::generic::RelayToTIR("accelerator_B"));
.set_attr<FTVMTIRToRuntime>("TIRToRuntime", relay::contrib::generic::accelerator_B::TIRToRuntime);
The python API is structured as shown below. Two base classes for relay graph partitioning and modification UMAPartitioner, and lowering from relay to TIR UMALower are building the core API. New custom accelerators are added in subdirectories by inheriting these two base classes.
.
├── partitioner.py
├── lower.py
├── utils.py
├── accelerator_A
│ ├── partitioner.py
│ ├── lower.py
│ ├── passes.py
│ ├── patterns.py
│ └── schedules.py
└── accelerator_B
└── ...
The UMAPartitioner base class performs a target specific relay graph partitioning. New custom accelerators can control this process by registering supported patterns and relay passes using the provided API.
class MyCustomAcceleratorPartitioner(UMAPartitioner):
@property
def target_name(self):
return "my_custom_accelerator"
def _register_patterns(self):
self._register_pattern("conv1d_relu", conv1d_relu_pattern())
def _register_relay_passes(self):
self._register_relay_pass(1, ConfigGenerator())
self._register_relay_pass(2, BufferScopeAnnotator())
The UMALower base class performs a lowering from relay to TIR. New custom accelerators can control this process by registering custom schedules and TIR passes using the provided API.
class MyCustomAcceleratorLower(UMALower):
def __init__(self):
super(MyCustomAcceleratorLower, self).__init__()
def _register_tir_schedules(self):
self._register_tir_schedule(insert_extern_calls)
def _register_tir_passes(self):
self._register_tir_pass(0, GenerateConstants())
CC: @areusch @aca88 @SebastianBoblestETAS @jroesch @manupa-arm @cgerum @philippvk @r.stahl @mjs @ramana-arm
 .
.