TVM has shown satisfactory performance on MLP models with CPU. However there are still some defects in the assembly code generated by LLVM which block AutoTVM/AutoScheduler from achieving optimal on GEMM.
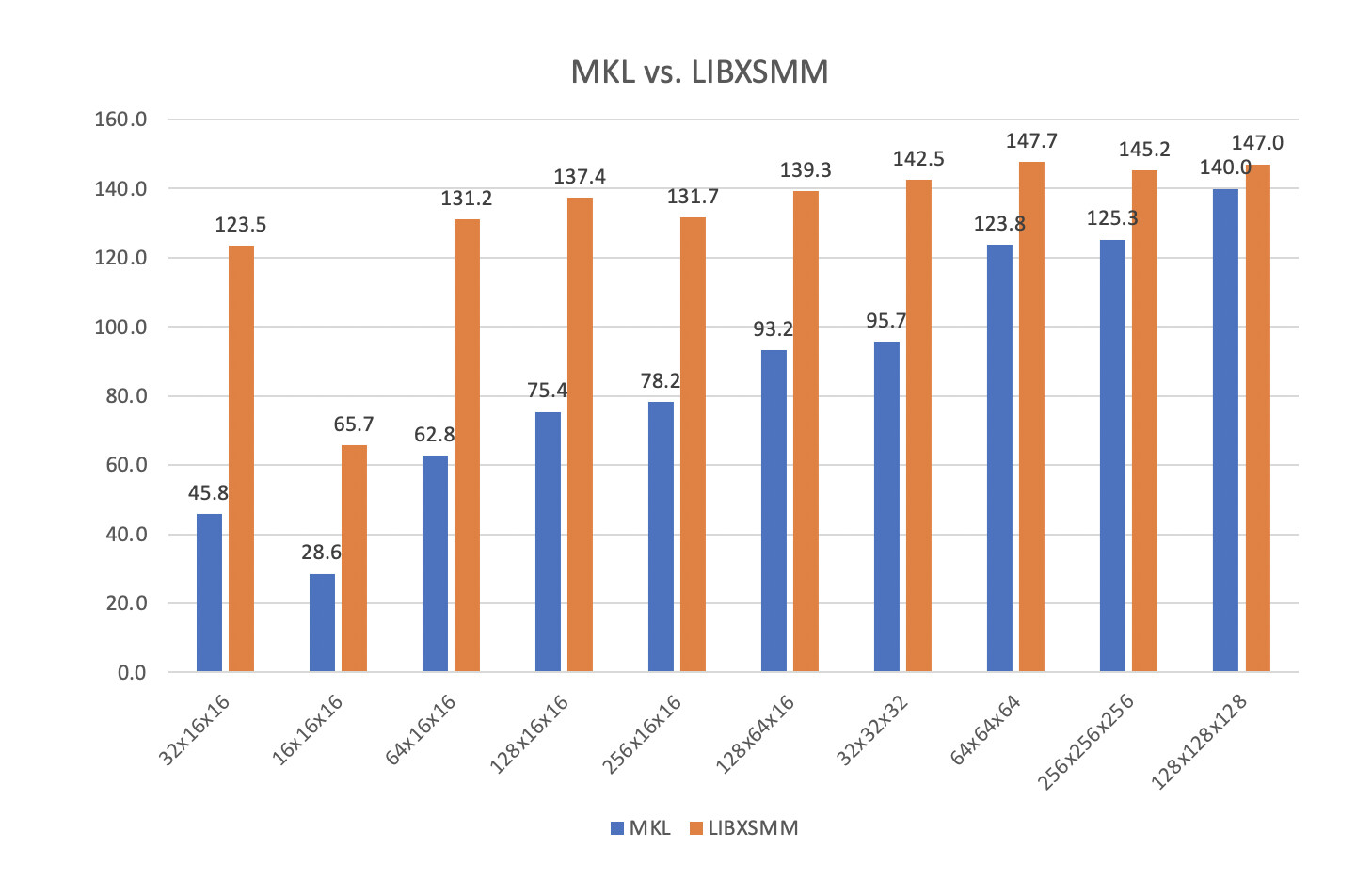
LIBXSMM is a open source library developed by Intel Lab for accelerating small matrix multiplication. It leverages the JIT code generator to generate high efficient GEMM kernels for x86 CPU, which could be very close to hardware rootline. According to our evaluation, in “small” GEMM (cube_root(m, n, k) <= 256) , LIBXSMM shows a superior performance over the well-known BLAS library Intel MKL:
This evaluation was run on Intel clx-8255c, which has a peak performance of 153 GFLOPS for single core. We can see LIBXSMM surpasses MKL in all shapes, and already very close to peak.
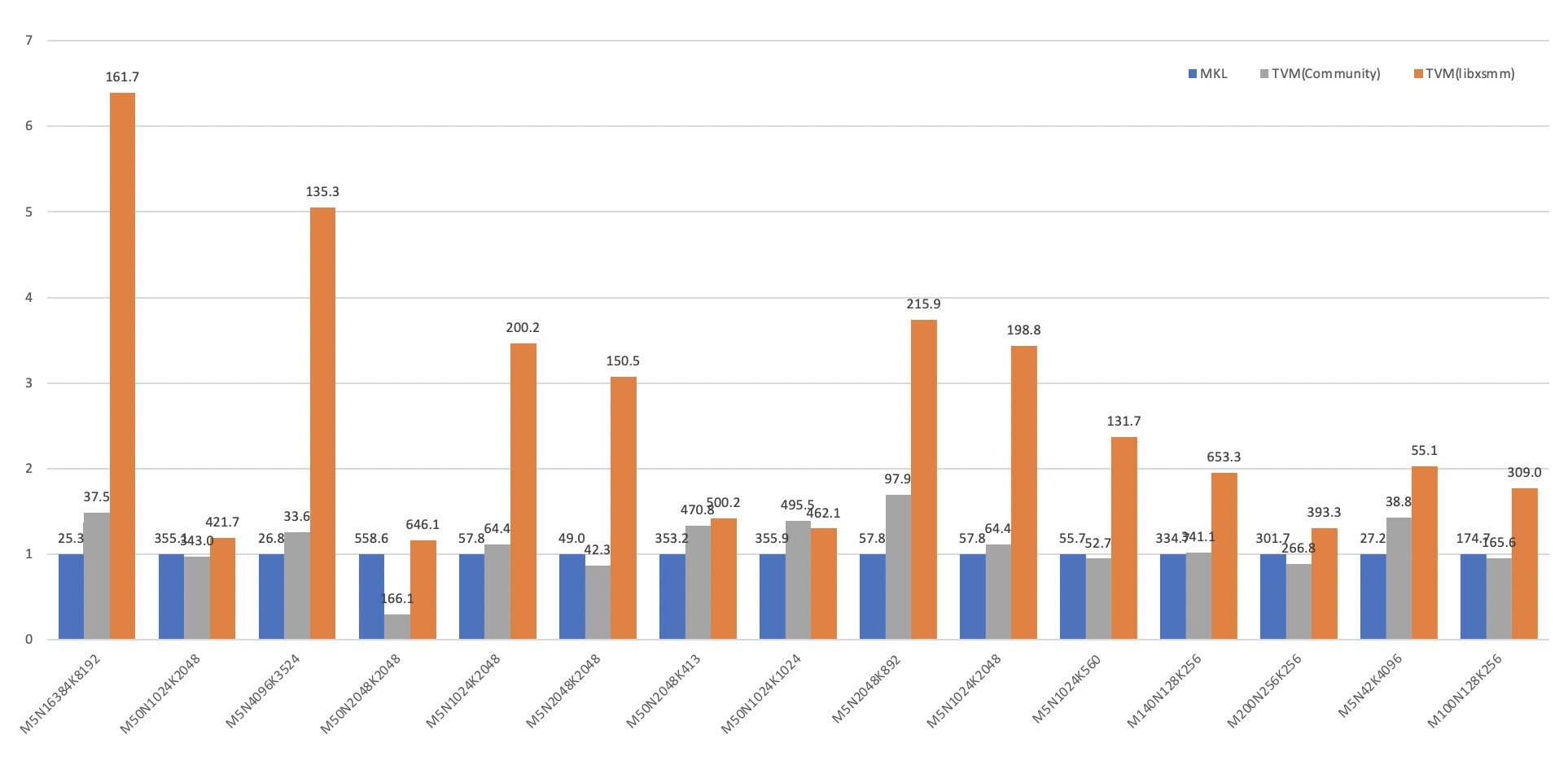
By the way, given that LIBXSMM can generate quite efficient GEMM kernel implementation, it is also an ideal substitution for inner-kernel of normal size GEMM. According our experiments, the AutoTVM templates we wrote with LIBXSMM as register-block generation, has a much higher performance comparing to MKL or existing TOPI implementation:
This result was collected on a real-world model, which runs on Intel clx-8255c. Every instance is assigned 6 core each, so the peak performance would be 153 GFLOP x 6 = 918 GFLOPS. We can see that the libxsmm implementation outperforms MKL or existing AutoTVM by roughly 2~3 times in almost all shapes. Finally the overall improvement for the model is 2.3X.
Proposal
This proposal aims to integrate LIBXSMM into TVM to accelerate small GEMM and serve as inner-kernel to accelerate normal size GEMM.
We propose to integrate LIBXSMM with TVM in following 3 components:
Add extern call “tvm.contrib.libxsmm.gemm” in “contrib” directory;
Use BYOC to accelerate small GEMM (cube_root(m, n, k ) <= 256);
Integrate our AutoTVM template into TOPI, as a GEMM implementation candidate.
Thanks for the proposal and it does useful. One question I have is whether LIBXSMM supports epilogue (e.g., ReLU, bias add) after GEMM, or it just focuses on single GEMM operator? If it just focuses on a single operator, then it seems not necessary to use BYOC but could just simply register them as another extern schedule such as CBLAS.
Yes, LIBXSMM does have epilogue support now, which includes bias, relu, softmax, tanh and gelu fusion. So I think BYOC would help. Thank you for the suggestion!
Thanks for the clarification. Yes in this case BYOC would be a more reasonable solution. Meanwhile, could you file an official RFC here for your proposal? It would definitely make your integration process much more smooth.
I am very interested! For those who don’t already know, I have experience working with LIBXSMM from my time at Intel, and some of this work landed in a SC21 paper which I coauthored.
The paper comes from Intel itself and has data/cites a lot of sources which prove that the LIBXSMM approach beats OneDNN in many cases. It’s exciting that the community is considering adding LIBXSMM as a BYOC target. I think it will bring great benefits to TVM’s Intel CPU performance!
LIBXSMM does have quantized kernels using VNNI, but I haven’t evaluate them against onednn’s int8 kernels. I think it’s a good idea to add quantized kernels as well, let’s put it in our future plan.
Thank you for the information, Denise!. I remeber you’ve mentioned that you already tried to integrate LIBXSMM into LLVM before, is that work going on well?