What is AMX?
AMX(Advanced Matrix Extensions) is a new 64-bit programming paradigm consisting of two components:
- A set of 2-dimensional registers (tiles) representing sub-arrays from a larger 2-dimensional memory image
- An accelerator that is able to operate on tiles; the first implementation of this accelerator is called TMUL (tile matrix multiply unit).
It introduces a new programming framework for working with matrices (rank-2 tensors) and a new matrix multiply instructions to enhance performance for a variety of deep learning workloads for both inference and training as we can do more matrix multiplies per clock cycle.
The extensions introduce two new components: a 2-dimensional register file with registers called ‘tiles’ and a set of accelerators that are able to operate on those tiles. The tiles represent a sub-array portion from a large 2-dimensional memory image. AMX instructions are synchronous in the instruction stream with memory load/store operations by tiles being coherent with the host’s memory accesses. AMX instructions may be freely interleaved with traditional x86 code and execute in parallel with other extensions (e.g., AVX512) with special tile loads and stores and accelerator commands being sent over to the accelerator for execution.
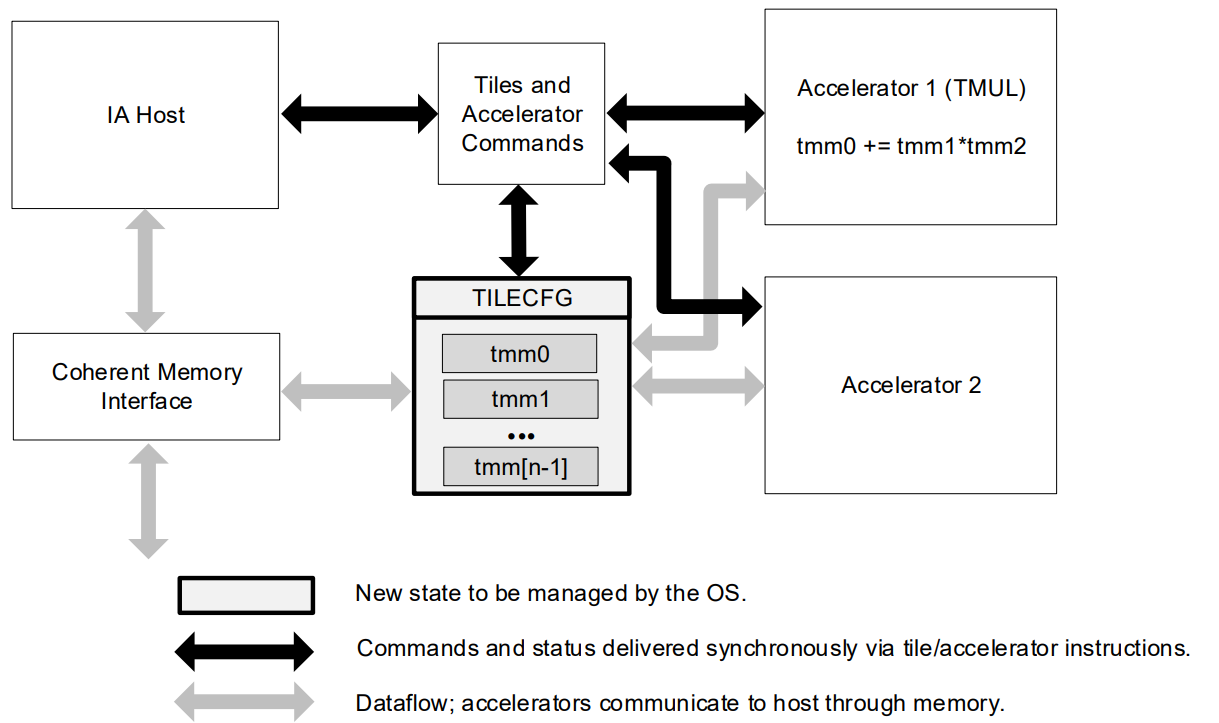
AMX Configuration in Linux:
Intel AMX was supported in linux kernel by version 5.16, it is able to control which processes are able to use the AMX instructions. for users:
The first step for a user-space process would be to use a new arch_prctl() command (ARCH_GET_XCOMP_SUPP) to get a list of supported features, if the appropriate bit is set in the result, AMX is available.
Then, another arch_prctl() command (ARCH_REQ_XCOMP_PERM) can be used to request permission to use AMX.
Some checks are made (one to be described shortly), and there is an opportunity for security modules to express an opinion as well. Normally, though, the request will be granted. Permissions apply to all threads in a process and are carried over a fork;
One potential problem has to do with the sigaltstack() system call, it allows a thread to establish a new stack for signal handling. That stack must be large enough to hold the FPU state if the process involved is using AMX.
Using AMX in linux seems little bit different from previous X86 SIMD instructions live AVX512 or AVX2, hence we regarded the AMX unit as a accelerator to integrated in TVM, user can open the AMX option to enable the AMX intrinsic in TVM according to their kernel/compiler/CPU version.
Integration.
Methodology
The Intel Advanced Matrix Extensions (AMX) provide a tile matrix multiply unit (TMUL), a tile control register (TILECFG), and eight tile registers TMM0~TMM7 (TILEDATA).
In TMUL, the row and col number could be configurated by instruction LDTILECFG , so the size of register could be up to 1KB which consisted by 16 rows and 64 bytes per row. so we can have different size GEMM kernel as a tensor intrinsic in TVM.
We registed the AMX init () and tileconfig() as two external functions in TVM and people who wanna use AMX should call these two function in python before.
Here we adopt AMX micro kernel mainly refers to TPP [Tensor Processing Primitives] proposed by Intel, and BRGEMM proposed in single building block to have a 32x128 gemm kernel as a tensor intrinsic in TVM. Use this intrinsic to perform a outter product based GEMM. What we need to do at low level is have an high efficient micro kernel which directly use these hardware instrctions, and let the outer loop schedule be formed by TVM schedule method according to different kinds of reduced kernel.
Minimizing Tile Loads :
Because LLVM intrinsic let user to assign register number, to efficiently utilized the register, here we assign 8 registers by hand craft to construct a 32x128x32 micro GEMM kernel.
in a micro GEMM kernel C=A x B. Like the diagram described below, we load cols from A to tile 4~5, and load rows from B to tile 6~7, leave the tile 0~3 to accumulate C in a outer product operation.
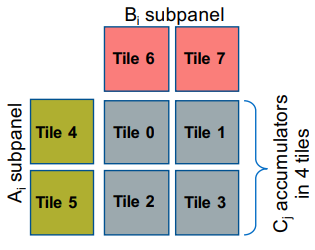
We chose to pre-loading the innermost loop tile for A and B. and have a 2-D array accumulated tile from C to minimize the tile loads. here is the pseudocode
Impl 1: basic 2x2x2 outer produce GEMM kernel, pre loading innermose loop tile.
for(k=0; k<2; k++){
for(n=0; n<2; n++){
tileload64(tmm_b, B)
}
for(m=0; m<2; m++){
tileload64(tmm_a, A)
for(n=0; n<2; n++){
tdpxxd(tmm_c, tmm_a, tmm_b)
}
}
}
Impl 2: optimal by interleaved with tdpxxd instructions.
for(k=0; k<2; k++){
for(n=0; n<2; n++){
tileload64(tmm_b, B)
for(m=0; m<2; m++){
if(n==0)
tileload64(tmm_a, A)
tdpxxd(tmm_c, tmm_a, tmm_b)
}
}
}
Here we interleave instructions(Impl 2) that use different resources so that they may be executed in parallel, and a bottleneck involving a certain resource might be avoided. Therefore, it is recommended to avoid sequential tileloads and tilestores like the ones in Impl 1
Implementations.
Init and config the amx tile size as 16x64Byte, so we can operate 16x64 int8 buffer or 16x32 bf16 buffer
We extracted micro compute kernel of matmul in 32x128x32 as a TVM intrinsic, it generated a instr. sequence to complete the computation as described. we first have TDPBUSD to have a u8s8s32 GEMM kernel integrated in.
Extracted accumulated tile store as another accumulation intrinsic. it stores the accumulation result of this 2x2 tile register after the total reduction on the axis k,
Let the layout transformation layer to transform matrix B to NC16n4c, so each block could be filled into 1 row in a tile register.
We test 1024x1024x1024 u8s8s32 matmul, the result shows the performance was at the equivalent level to intel oneDNN, which use xbbyak as the JIT compiler.
(To utilize AMX, the minimum building requirements should be at least LLVM 12 and clang/gcc 12 and kernel version 5.16)
we have a PR here: https://github.com/apache/tvm/pull/13642, which includes:
- Add building options and LLVM AMX intrinsic target detection ;
- Register a global AMX init and config function;
- LLVM AMX intrinsic integrated as Tensor intrinsic (1 for microkernel computation and 1 for accumulation tile store);
- Add test case on u8s8s32 matmul usding the AMX Tensor intrinsics;
- Integration of int8 dense kernel and its testcase;
Question remained.
there also 2 problem during the engineering,
-
How to tensorize a tile which was in tail of matrix, since use the tile/split schedule could cause an if likely in TIR, is there possible to split the tail from the main loop? so that we don’t have to padding the data to match the size of micro kernel.
the same issue seems also reported here:
-
How to generate a constant buffer when doing tensorize. since AMX tile size could be configurated by a 64byte buffer. if we wanna use different tile size to make it more flexible, we need to generated and fill this buffer during compile time to avoid overhead;