Introduction
NVIDIA Turing tensor core has been enhanced for deep learning network inferencing.The Turing tensorcore adds new INT8 INT4, and INT1 precision modes for inferencing workloads that can tolerate quantization and don’t require FP16 precision while Volta tensor cores only support FP16/FP32 precisions.
Cutlass only supports INT4 matrix multiplication using tensor cores. There’s no existing libraries that fully support INT4 conv2d or INT4 end-to-end inference. In this RFC, we add new features in Relay and Topi to achieve this goal in TVM. We briefly describe the changes as follows. We will continue to post more performance numbers and associated PRs will be posted to keep track of the progress. All the experiments use Nvidia T4 GPU.
This is a joint work of our capstone project and Amazon AWS TVM team. The entire pipeline is to train the parameters in Pytorch and load them into the TVM for inference. Thanks @Laurawly, @GaryYuyjl @yidawang for the collaboration.
Topi
- One new direct tensorcore conv2d schedule (PR sent: 6121), and one im2col tensorcore conv2d schedule. We found that in most of the workloads, direct conv2d performs better than im2col conv2d; performance numbers shown below:
| workload | conv2d workload (batch_size, in_channels, in_size, out_channels, kernel_size, stride, padding) | im2col(ms) | direct(ms) |
|---|---|---|---|
| 0 | (8, 64, 56, 64, 3, 1, 1) | 0.21777 | 0,19015 |
| 1 | (8, 64, 56, 128, 3, 2, 1) | 0.15 | 0.12979 |
| 2 | (8, 64, 56, 128, 1, 2, 0) | 0.04909 | 0.04359 |
| 3 | (8, 128, 28, 128, 3, 1, 1) | 0.14178 | 0.15725 |
| 4 | (8, 128, 28, 256, 3, 2, 1) | 0.10795 | 0.0994 |
| 5 | (8, 128, 28, 256, 1, 2, 0) | 0.02941 | 0.04659 |
| 6 | (8, 256, 14, 256, 3, 1, 1) | 0.1376 | 0.12328 |
| 7 | (8, 256, 14, 512, 3, 2, 1) | 0.12329 | 0.11763 |
| 8 | (8, 256, 14, 512, 1, 2, 0) | 0.02827 | 0.04626 |
| 9 | (8, 512, 7, 512, 3, 1, 1) | 0.20317 | 0.11436 |
-
Since Tensor Core had various and tight shape constraints on different precision’s matrix multiplication, direct convolution inherit such constraints on workloads’ batch, in_channel and out_channel axises. But for im2col, such constraints are looser since multiple axes could be fused into one to meet the divisible requirement. Hence in our implementations, most of the workloads that fit into direct convolution’s shape constraints would be applied with direct convolution strategy, while the others (e.g., the first convolution layer in Resnet18/ Resnet50) should use im2col.
-
In terms of the scheduling, we found that with input pre-packing, vectorization and with data layout HWNC, we gets performance gain. And we need to first write the result into shared memory before writing into global memory in order to fuse correctly with other operations.
-
For 4-bit inference, there is huge impact if we can utilize UINT4 instead of INT4. To achieve this, we made changes in relay to support UINT4 and INT4 convolution. It is strange that CUDA wmma APIs don’t support “UINT4 x INT4” but PTX does so we hard-coded a function in CUDA code-gen to call PTX assembly code if there is an “UINT4 x INT4”.
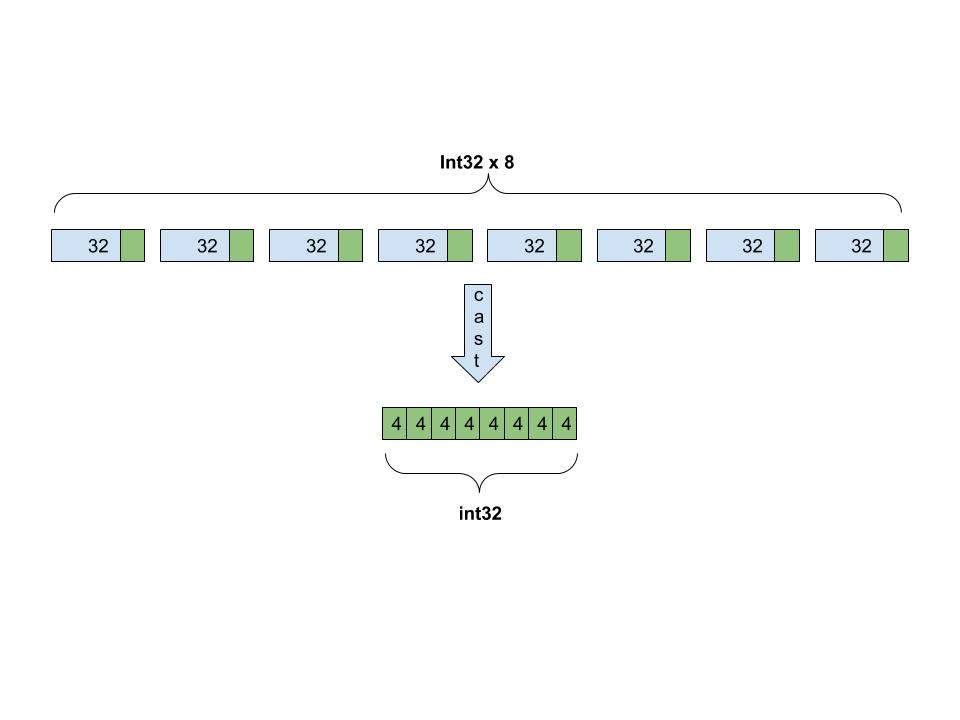
- Cast from INT32 to INT4
- We need to requantize from INT32 to INT4 as the input of the convolution in each layer since the result of convolution in previous layer is with full precision. We can’t directly cast to INT4 by using “(INT4)” (which could be done for INT8) and it has to be done by packing several 4-bit number into an existing datatype, for example, int8 or int32. We choose int32 to store 8 4-bit numbers to align with Alibaba’s Sub-byte PR. In the casting process, every 8 consecutive 32-bit numbers are packed into one int32 number. Their least significant four bits are left, bit shifted to the proper position and elementwise-ored with each other in the same group to formulate the new number. (diagram needed here for better clarificatfion)
Relay
- Support reading INT4 numpy array
- Numpy doesn’t natively support INT4 array so we need to store 4-bit weights into int32 numpy data type. When the model sees INT32 numpy array assigned to a INT4 variable, it will not trigger the data type and there will be data shape mismatch problem. And there are also some changes needed to make in order to do the constant folding 4-bit parameters.
- QNN Wrappers and quantized Resnet
- We also create the QNN wrappers to build the Neural Networks. The quantized Resnet is written as an example. We also wrote ease-of-use interfaces to specify each layers scaling and datatypes.
End-to-end performance preview
More results will be updated here, here’s an initial overview of the performance on Nvidia T4 GPU.
| Resnet 50 | int8 tensorcore (ms) | int4 tensorcore (ms) | int8 dp4a (ms) |
|---|---|---|---|
| Batch=8 | 8.12 | 6.7 | 9.72 |
| Batch=16 | 12.54 | 11.7 | 15.65 |
Summary
In this RFC we show the performance results and the changes in TVM. There is still a room to improve the speed and we are actively working on it.
