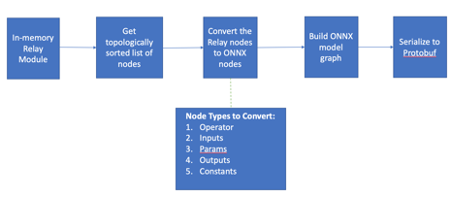
We want to port the DL models in Relay IR. For that, we want to serialize the Relay IR to disk. Once serialized third-party frameworks, compilers should be able to import those. We want the serialization format to be compact, portable, widely adopted and having well-documented specifications.
We may want to export the optimized Relay after running optimization passes on it. We see a few challenges there which we will talk later in this RFC.
Why ONNX?
Serialization format should meet below criteria:
Widely adopted
Well documented specification
Import and export support in source and target system
ONNX is the best fit based on the criteria and hence it is chosen.
What is ONNX?
ONNX provides an open-source format for DL models. It defines an extensible computation graph model, as well as definitions of built-in operators and standard data types having support for inferencing majorly. The ONNX is widely supported and can be found in different frameworks, hardware.
ONNX does not have support for adding functions. ONNX does have some predefined functions though. So, we will not be able to map higher-order functions from Relay to ONNX.
Proposal to add support for functions was not accepted. ONNX design/larger feature process · Issue #48 · onnx/onnx · GitHub
Support for Operator Fusion pass
We may want to optimize the model using optimization passes before exporting it to ONNX. When we run a Fuse Op pass on Relay, the subgraph of nodes which can be fused together gets wrapped into an inline function. It will be difficult to add support for such inline functions for the reasons listed in the point above. Also, the target runtime should have required support to run fused ops.
@jroesch, @tqchen, Regarding the naming convention discussion on the PR, I agree the converter does not seem to be the correct word. The suggested words by you are either ‘export’ or ‘target’. I think ‘export’ should be used as it is more in line with other DL frameworks. Please let me know your thoughts.
Thanks for the proposal. It would be great to list alternatives with labels (see example Target and Attributes), discuss pros and cons, so others can share their opinions easily.
Given that onnx is not rich enough to cover all the operators, such conversion might be limited to a subset. It would be great to document a potential usage cases.
Here are some high level thoughts:
It seems does not make sense to use onnx as a serialization format, as we can always store the functions in the native format (with complete coverage)
If we have a target runtime with onnx format in mind, then we should list those runtimes and discuss the scope of the coverage needed.
Thanks @tqchen for comments.
To elaborate more here, the support for Relay to ONNX serialization will help us to take advantage of hardware-specific optimizations supported by different compilers. The ONNX format is mostly adopted. If a particular compiler supports a specific format, support for it can also be added. Examples of other formats can be NNEF, PFA, TFLite etc.
Yes, there will be some use cases that will not be supported by ONNX and this will be true for other portable formats as well. But we can take advantage of Bring Your Own Codegen and Graph Partitioning feature. The model graph can be annotated and partitioned based on ops supported by ONNX runtime. For subgraphs annotated for ONNX, we serialize it to ONNX and then ONNX runtime should be able to run it. For the rest of the graph, we fallback to TVM runtime.
This feature will add generic support for serializing the Relay graph to ONNX and can be used by the external codegen and runtimes.
OK, I think the goal of lowering to onnx to target related runtimes makes sense. That does mean we should treat onnx more as a target, instead of a serialization format(where the name export makes more sense)
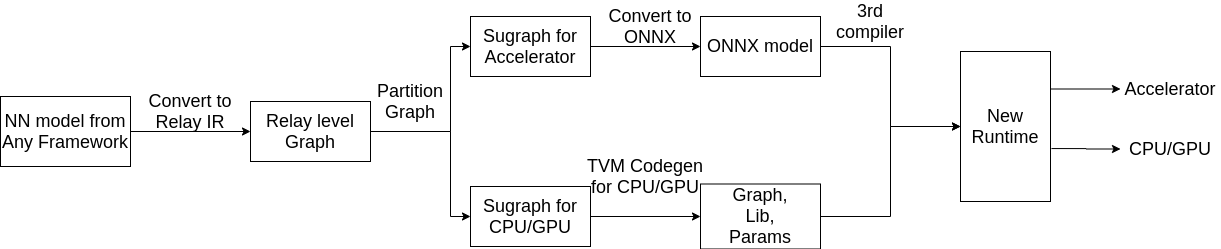
@tqchen Here is a usage scenario that we are thinking about with Relay to ONNX serialization. Let us say that there is a HW chip vendor, whose model compiler toolchain already supports ONNX as an input format. Since ONNX is quite limited in its scope, there is only a small set of models that can be supported by this HW out of the box. Since there already exists a graph annotation, graph partitioning support within Relay, our intention is to create a pass, which could split a model graph into ONNX compatible sub-graph and the other part which could be compiled using TVM. The HW vendor could develop support for Codegen and Runtime for their HW using the BYOCG methodology. Once they have done that, they could use Relay-to-ONNX serialization (this RFC), to export the ONNX compatible sub-graph to ONNX. Their compiler could convert the ONNX sub-graph into something that can be executed on their HW, while TVM would compile the remaining part of the graph. Since the HW vendor would have also implemented support in the Runtime based on BYOCG, the resulting sub-graphs can be executed on the target HW, with the TVM compiled part to execute on the CPU and the ONNX compatible sub-graph on the HW accelerator. This way, we are helping the HW vendors to expand the range of models that they can support on their HW.
These suggestion all makes sense. I think we should bring relay to ONNX support. The only choices we need to discuss so far are:
C0: put the onnx under the export namespace, which could imply that it is a serialization format(and all of relay can serialize to it).
C1: put the onnx under target/onxx, which indicate that ONNX is a target that some relay function can lower to, but may not cover all the ops
Given that the main purpose of the support is for specific compatible runtime support suggested by most folks in this thread, I would recommend we take C1. Would be great to hear from others as well.
The original intention was to use Relay to ONNX as serialization format only.
Option C1:
It seems interesting and can fit naturally in TVM. But wanted to discuss a few of the points below.
First, let me put down the different properties or attributes of a target in general.
Ability to annotate Relay graph for specific op support
Ability of Relay Lowering which is Codegen
Runtime Module
When we treat ONNX as a target, we will be able to annotate the graph for specific ops support. Also, we will be able to lower Relay to ONNX.
But since ONNX is an IR, there are multiple runtimes such as onnxruntime, TensorRT etc which support it. So there can be multiple runtime modules. We will have to think about how we are going to support these runtimes. The options I can see are.
R0: Implement a generic ONNX runtime and allow vendors to extend it for their specific runtime.
R1: Add composite Targets like “ONNX-TensorRT”., “ONNX-ONNXRuntime”.
Let me know your thought around it.I would love to hear other’s opinions as well regarding C0, C1 and R0, R1.
@smallcosca, Thanks for sharing the link for your work on Relay to ONNX. It’s great work and will definitely help. I also have a PR against Apache TVM repo. I will refer to your implementation and so that we can take the best of both the worlds.
Note that we do not need a runnable runtime for to put the onnx as a target. Currently we have outputs like CSourceModule that does not have a runnable runtime.
Regardless of the ways to use the onnx target feature. The final presentation of the result can always be a variant of runtime module api to hold the generated results with an overloaded SaveToFile method that saves the module into the onnx’s proto format.
So we will be adding support for ONNX codegen only.
I will work on adding a codegen for ONNX and then will work on an example ONNX runtime to demonstrate end to end functionality. I will also be improving operator coverage for ONNX.
Given that there are other folks that are interested in the topic, e.g. @smallcoscat perhaps it makes sense to land a version with reasonable coverage, then invite others to contribute and collaborate
We try to partition Relay graph into two group of subgraphs, one is for accelerator which supports ONNX model, and the other is for CPU/GPU. The ONNX model is compiled by the 3rd compiler. And the group of sugraphs for CPU/GPU follows the original TVM codegen. Finally, we intend to create a new runtime integrate these codes.
@maheshambule I am very glad we can make some positive contributions to TVM. I updated the source code depending on the final version at April 12, 2020 of TVM, and create some new operators. If you require any further information, feel free to contact me.
@smallcoscat, Thanks. Looking forward to collaborate with you.
I will get my PR with basic coverage in TVM repo and then you can send in your PR as well. So that we increase the overall coverage in terms of ops and models. Sounds good?
I will need some time to work on codegen part to implement option C1. I will keep you posted.
@maheshambule Ok, no problem. I will keep creating new operators.
By the way, the previous hyperlink is changed. This is the new hyperlink to source code and example code .
@maheshambule seems we have reached concensus, please feel free to update the PR to reflect the discussion, we only need to support the conversion but not the runtime part
@tqchen, I tried to add ONNX as target, but since target codegen receives lowered IRModule with PrimFunc nodes, I am not able to convert those to ONNX. However, as in the case of external codegen lowering is deferred to external codegens, I am receiving IRModule without PrimFunc nodes and I am able to convert those. Please let me know if I am missing something here. Is there a way to avoid lowering for the target codegen?