This RFC discusses post-training quantization of FP32 models to an FP16 form. We do not focus on specific codegen but rather the relay representation of the models.
Doing this transformation is useful for reducing model size as it halves the expected size of the weights. In addition to potential improvements in memory bandwidth, many hardware platforms which support FP16 have theoretically higher throughput for FP16 operations compared to FP32. However, using FP16 operations often requires casting from FP32 → FP16 or vice versa which introduces some overhead. Therefore, we must have some care about when and where we insert casts.
Design Overview
The main aspect of the design is lifted from TensorFlow’s automatic mixed precision training. A relevant slidedeck is here (NVIDIA On-Demand) with a focus on slides 12 - 20.
The main idea is to have a “Green List” and “Gray List” of operations which might benefit from FP16 versions of the operations.
- Green List operations are much faster in an FP16 form such that it is almost always preferable to transform the operation, even if we must cast the inputs.
- Gray List operations either have no speedup from FP16 or have speedups too small to justify overhead from casting.
Operations not in either list are assumed to either not support FP16 or have good reasons not to use their FP16 versions. For example, some operations like exp need FP32 to maintain numerical stability. From these lists we can determine which parts of our computational graph are in the FP16 domain and which are in the FP32 domain. From here, it becomes clear which parts of the graph need casting operations.
Finally, there needs to be some control over the output data types for converted operations. Some FP16 operations might accumulate results into FP32 for numerical reasons and some might produce an FP16 number. In the rewrite of the graph, we will provide some control over this variable.
Pass Example
The main meat of this RFC is the creation of a new pass which, given the ability to map operations into the aforementioned green and gray lists, can insert the proper casts and operation transformations. An example of this can be seen in the linked slide deck. In this example, all quantized functions return FP16. Green and gray colors correspond to our lists:

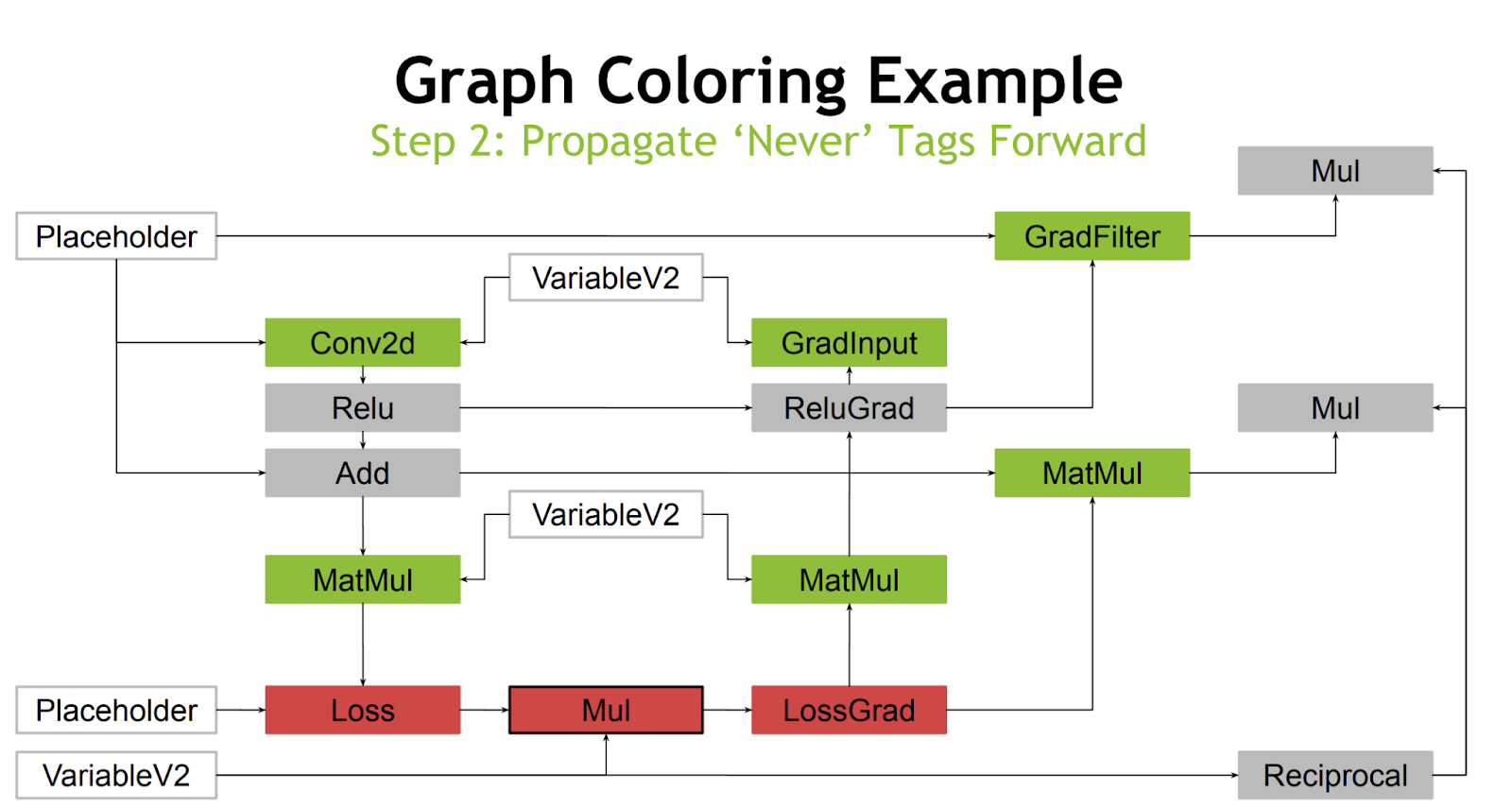
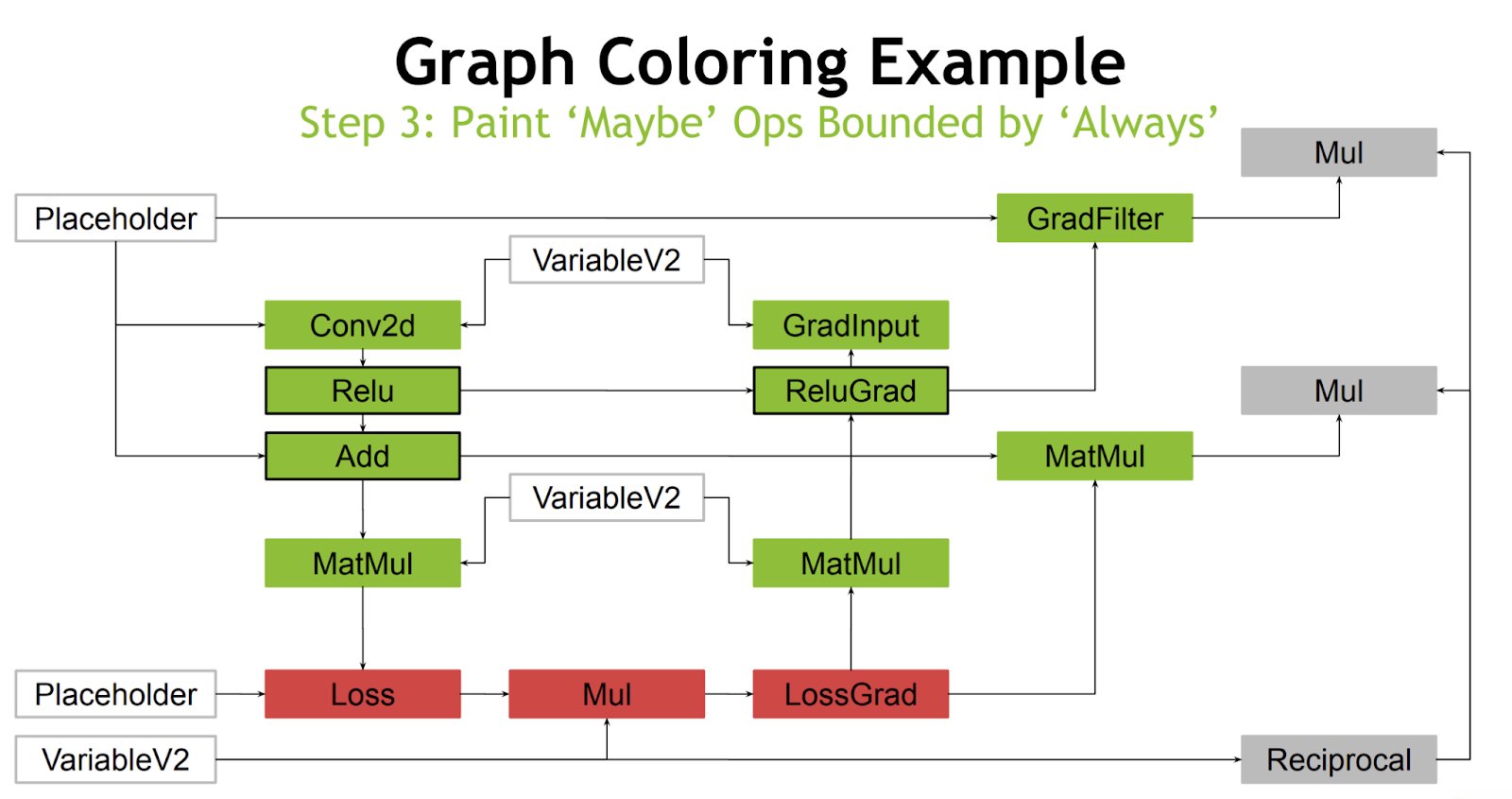
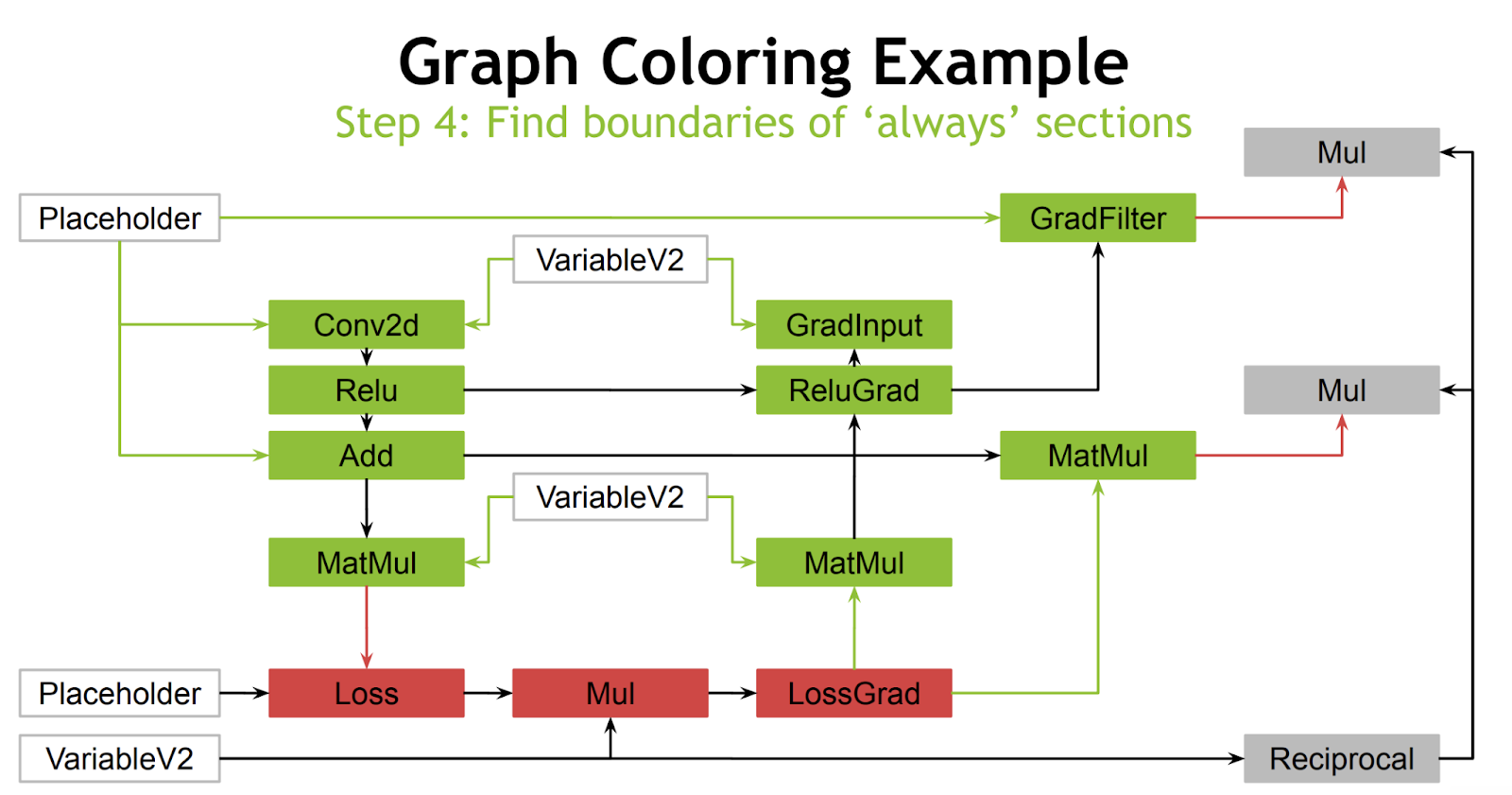
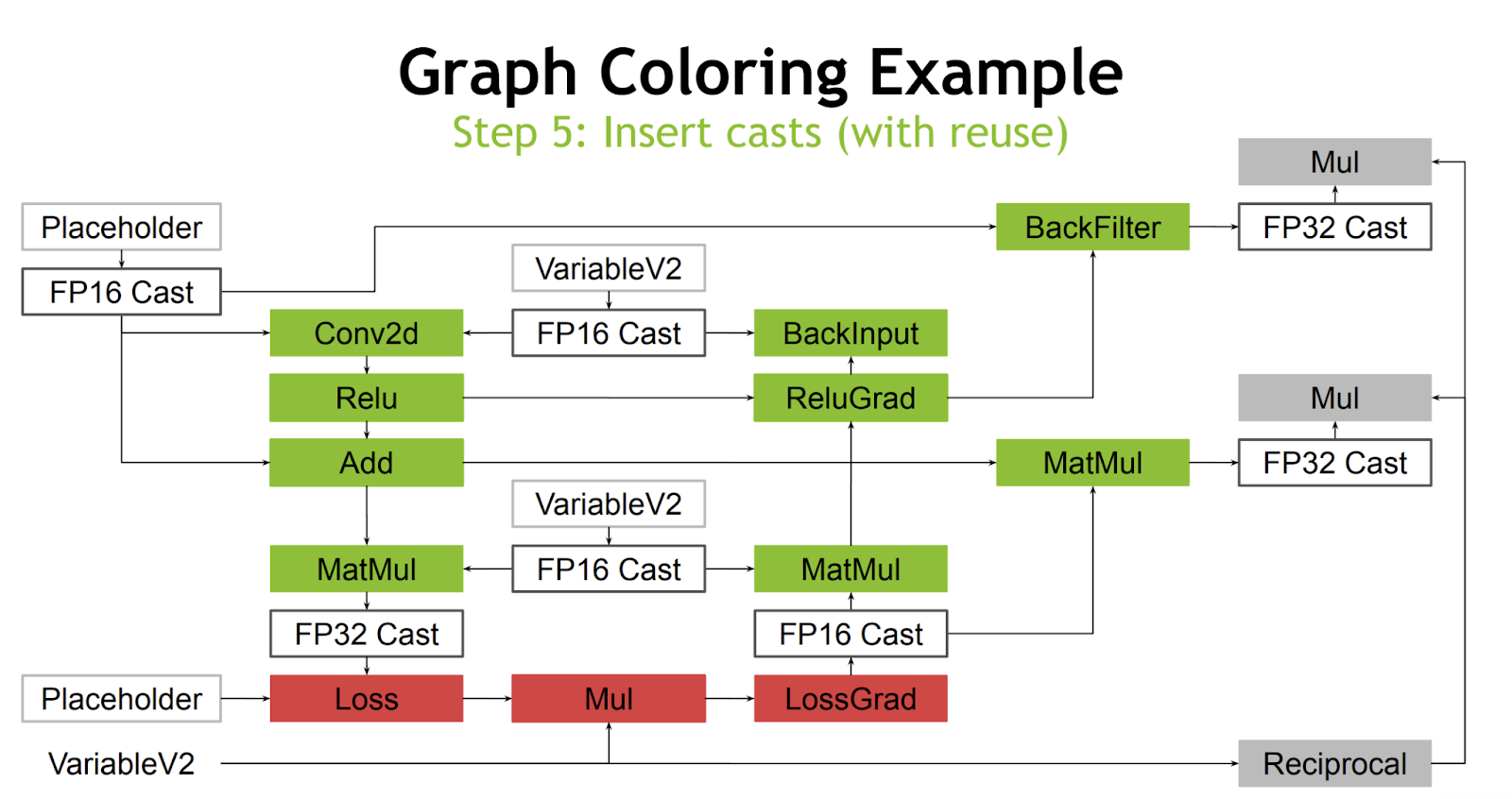
The final step is to replace all green colored operations with FP16 versions.
What Should be Extensible?
We want this pass to be generally usable.
To accomplish this goal, we want to expose the ability to modify the green and gray lists for operations. Furthermore, we want to be able to have granular control over what we put in a particular list. For example, it might make sense for a hardware platform to place a convolution into the green list only when the input tensors and weights are of sufficient size. For the purposes of the initial implementation however, we will do something simpler with classifying Relay nodes.
Finally, we will want the user to have a little control over how an operation can be rewritten into an FP16 graph. Here, we assume a 1-1 mapping between operations. E.g. an FP32 conv. in Relay is just the exact same conv. Node but with FP16 inputs. The one knob we will expose for certain operations is controlling the accumulation datatype. E.g. we might have an FP16 conv. which accumulates the solution into an FP32 buffer and one which accumulates into an FP16 buffer. Note this information is needed in the pass when propagating colors through our graph.
Future Work
Write code
Flesh out interface into pass
Test codegen works as expected for CUDA and x86 at the least.
Support for bfloat16
