A new quantization framework in TVM: Initial RFC
In this and subsequent RFCs, we will present a new framework for doing static, data-aware quantization on relay graphs.
Previously, I put up an RFC to discuss the new quantization framework in TVM. After that RFC, I got some feedback from the community on the design, and also heard that community members would like to see the design split up into multiple RFCs. This RFC addresses that feedback, but still aims to stand alone from the previous RFC.
Since this is an introductory RFC, it will go over the conceptual structure of the project, but will not go into class definitions or implementation details. Those details will be provided in three future RFCs: one on pattern-based rewriting, one on choosing quantization parameters and one on creating the final quantized graph for inference. The future RFCs will correspond directly to the subsections of the “Outline of this Work” section of this RFC.
Motivation for a new quantization framework in TVM
The current quantization framework has proved difficult to extend and modify: adding new features requires changing many different files and passes. As a result, supporting quantization of complex graph structures, supporting many calibration methods, and adding multi-precision quantization is difficult.
In this work, we aim to create a modular and extensible framework that can be easily modified and maintained.
Background and Prior Work
This work relies on concepts developed in relay’s QNN (quantized neural network) ops, and even uses some QNN ops. If you are not familiar with QNN, it may be helpful for you to read about QNN before continuing. The code is here. QNN uses quantization parameters to quantize data to a target datatype. For example, qnn.quantize takes in data in FP32, a scale, a zero point and an output dtype, and returns a quantized value that has been appropriately scaled, shifted, clipped and cast to the target datatype.
We use the Relay pattern matcher to do a lot of our rewrites, and we assume some level of familiarity with it throughout this document.
Flavors of quantization and a few definitions
There are many different ways to approach quantization. For the purposes of this RFC we focus on affine quantization:
Q = clip(s * (A - z), dtype)
where A is the value we are quantizing, s is the scale, z is the zero point and Q is the clipped value. In this scheme, the scale is always a float and the zero point is an integer. We’ll refer to the scale, zero point, and output datatype as the quantization parameters.
After data has been scaled, shifted and clipped using quantization parameters, we say that that data is in affine space. If we reverse the scaling and shifting, the data has been moved back into real space. Affine spaces are defined by quantization parameters (e.g. scale and zero points) which map values back to the real numbers.
We say that we are changing from one affine space to another (e.g. “requantizing”) if we change data expressed with one set of quantization parameters into an approximation expressed with a different set of quantization parameters.
There are also many different ways to quantize models. These include quantization aware training, data-aware quantization, dynamic quantization, and multi-precision quantization.
Quantization aware training involves training the network while simulating the effects of quantization, so the network learns how to deal with data loss. Often, quantization aware training is the most accurate approach. However, it requires training the network, which TVM does not currently support.
Multi-precision quantization involves quantizing different parts of the graph as different datatypes.
Dynamic quantization inserts code into the original graph to calculate appropriate quantization parameters at runtime. The advantage of dynamic quantization is that we don’t need access to a representative dataset to calculate the scale and zero points. Additionally, it is usually more accurate than data aware quantization since we can pick optimal quantization parameters for one particular set of inputs. For memory-bound models (e.g. ones with lots of parameters) dynamic quantization can still see major savings in latency and power. As a result, it is popular to use dynamic quantization on NLP models. However, calculating quantization parameters at runtime introduces runtime overhead that will affect the performance of the final graph.
Static data aware quantization uses a representative dataset and intermediate values from the inference graph and/or an approximation of the quantized graph to pick appropriate scales and zero points. This representative dataset only requires the data which is fed into the model and does not require ground-truth labels. It involves inserting relay operations to simulate the effects of quantization while examining intermediate operations to determine the optimal quantization parameters.
In static data aware quantization, we may want to pick our quantization parameters using intermediate values from an approximation of the quantized graph. There are two common methods to do this: simulated quantization and fake quantization.
Simulated quantization transforms data into affine space using quantization parameters, but does not cast to the target datatype-- instead, the output of simulated quantize is in FP32. Note however, that the values of a tensor are still integral. FP32 should be able to express integral values in the range of 24 bit integral types which we believe will be more than enough for almost all applications. Simulated quantization functions are already written and were introduced in this PR.
Fake quantization simulates the data loss that would occur during quantization, but does not return a tensor in affine space. Fake quantization is the method used in TensorFlow’s QAT (quantization aware training).
Goals and scope of this work
The main goal of this work is to implement an extensible framework for static data-aware quantization. We’ll use simulated quantization to provide intermediate values we can use to choose quantization parameters.
In this initial work, we’ll support quantization to int8 and also fall through to fp32 (i.e., if quantization of part of the graph results in a particularly large accuracy loss, we can revert that part of the graph to fp32). Additionally, the algorithm to choose scales and zero points will be implemented in Python instead of Relay. This will allow us to support many different methods of choosing scales and zero points, and allow us to add more methods easily. We aim to make the graph rewriting process robust enough to support quantization of complex graph structures.
Additionally, we would like to lay the groundwork to support dynamic quantization and multi-precision quantization. Dynamic quantization is implementable under this suggested framework, and multi-precision quantization could also be supported. However, this is future work, and we won’t go into too much detail here.
We’ve chosen to focus on static data aware quantization because TVM does not have training yet, so we cannot attempt to support quantization aware training. Additionally, the runtime overhead in dynamic quantization can be significant.
We’ve chosen to use simulated quantization instead of fake quantization because simulated quantization allows us to examine the effects of lower-precision accumulation datatypes, and specifically avoid quantization parameters that cause integer overflow. Since int8 quantization uses int32 accumulation, we don’t need to worry about integer overflow in this initial work. However, some hardware accelerators use lower-precision accumulation datatypes-- for example, an FPGA may multiply two int8 values and accumulate them into an int14 datatype. In those cases, simulating integer overflow will be useful.
Outline of the work
For this and future RFCs, I have split the work into three conceptual chunks: pattern-based rewriting of the graph, choosing quantization parameters, and then creating the final graph by combining different affine regions. Each of the subsections below will correspond to a future RFC. Because there will be future RFCs, in this section, I aim to present a conceptual overview of the approach, but I will not provide too many implementation details here. If you have any questions or if there is anything I can clarify at this point, though, please feel free to ask.
Pattern-based rewriting
We use the pattern matcher to identify subgraphs that we would like to quantizeand pick scales and zero points for. Initially, we’ll support quantizing these patterns using the pattern-based rewrite: nn.conv2d, nn.conv2d → nn.bias_add, nn.conv2d → add, nn.dense, add, subtract, and multiply, however, adding new patterns is not difficult.
For each pattern we’d like to rewrite, we provide two rewrite callbacks which transform the pattern into affine space.
One rewrite callback rewrites the graph to a simulated quantized version of the pattern, using the qnn.simulated_quantize and qnn.simulated_dequantize ops to transition into and out of affine space. We insert Relay variables as the scale and zero points. The simulated quantization graph is then used to calibrate the quantization parameters of the graph.
The second rewrite callback rewrites the graph to the quantized inference graph. (This rewrite will be done after we pick the scales, zero point and the datatype we want to quantize the pattern with). In this rewrite, we use qnn.quantize and qnn.dequantize to move in and out of affine space. This is the graph that will be used for running the final graph.
We are committed to using qnn.quantize, qnn.dequantize, qnn.requantize, qnn.simulated_quantize and qnn.simulated_quantize. However, it’s not clear what the best way to handle the quantized versions of more complex operators, like nn.conv2d and nn.dense. (Doing a convolution or dense operation in affine space adds extra terms created by the zero points, so we then have to subtract these terms off to be consistent with the result of the original operator. See https://github.com/apache/tvm/blob/main/src/relay/qnn/op/convolution.cc#L636 for an example of how current QNN ops deal with this problem.)
We have a few options:
- Handwrite the affine versions of nn.conv2d and nn.dense directly in the rewrite callbacks, in Python. We would make utility functions that create the affine-space AST given input datatypes and accumulation datatypes.
This option is the most flexible, and least invasive to existing code in QNN. If we want to support more operators using this pattern-based rewrite, it’s easy to write them directly. We don’t have to worry about writing new Relay ops.
However, this option does duplicate some of the functionality of QNN, and creates a split between the infrastructure used for automatic quantization and importing pre-quantized graphs. Additionally, hardware companies find the symbolic nature of QNN useful, since they like to offload qnn.conv2d → qnn.requantize onto accelerators. If we don’t use QNN, they will have to match larger relay patterns to offload, and additionally will need to support both QNN and this new method.
- Extend qnn.conv2d, qnn.dense, etc. to be used with more datatypes, including fp32. We would also have to add an attribute to QNN specify the accumulation datatype used.
In this option, qnn.quantize, qnn.dequantize, and qnn.requantize will only ever be used for inference graphs, and qnn.simulated_quantize, qnn.simulated_dequantize will only be used in calibration graphs. However, all other QNN ops (qnn.dense, qnn.conv2d, etc.) can be used in both the final inference graph and in the calibration graph.
These QNN ops would be used in both the simulated quantized graph for calibration and the inference graph, but with different datatypes.
The advantage of this option is that it uses the same infrastructure as the importer that imports quantized graphs.
However, it will require a significant rewrite of the backend of QNN. And, it is slightly less flexible–if we want to support quantization of more quantized operators, we will have to implement them in QNN before using them with the pattern matching system.
We prefer the second option presented here because it unifies auto quantization with the existing quantization importers. We also considered introducing qnn.simulated_conv2d, qnn.simulated_dense, etc. However, we don’t think that this is necessary since these ops would be purely symbolic. Graphs that are simulated will have qnn.simluated_quantize and qnn.simulated_dequantize in them, so it will be easy for users to tell calibration graphs from inference graphs. It would be great if we could get some feedback from the community about these options, and about the direction to take QNN in.
Let’s take a look at an example using the second option.
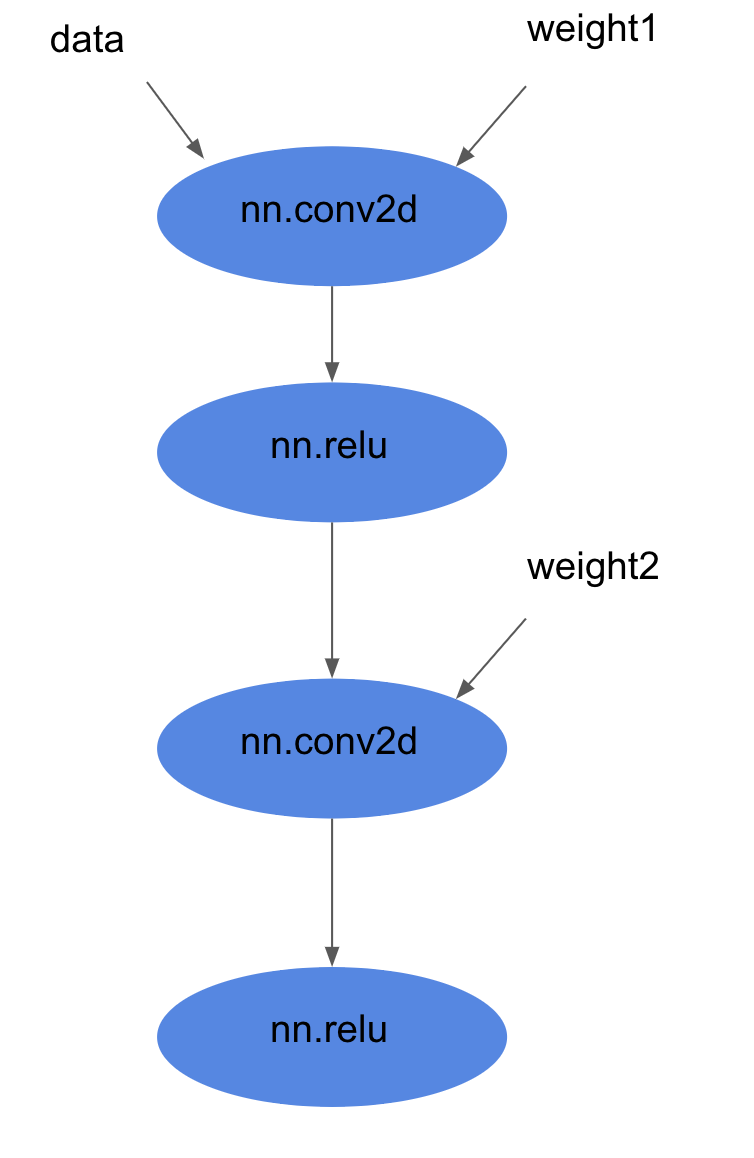
Let’s consider this graph. When we do our pattern-based rewrite, we end up with a graph that looks like this:

We’ve inserted Relay variables in place of all the scales and zero points, and do the convolution calculations in affine space, though the accumulation datatype of the qnn.conv2d ops is fp32, not int32. Additionally, we’ve left nn.relu in real space for now.
Choosing quantization parameters
After rewriting the original graph to simulate quantization, we run a calibration loop in python to pick the quantization parameters. It will run the simulated graph many times, and choose the quantization parameters in topographical order (i.e., it will pick the first scale and zero point, then the next scale and zero point, etc). We will use intermediate values from running E1 to choose the quantization parameters. We will support per-channel scales.
There are many different methods for picking scales and zero points, including KL-divergence, 99% of the maximum value of the input tensor, averaging the maximums seen in input tensors. Because of this, we want to make it easy to change the method of picking scales and zero points. So, the actual method used to calculate scales and zero points from data will be a python callback that is passed into the calibration loop.
This will make it easy to add more methods of picking scales and zero points without refactoring the rest of the code. There will be an additional RFC on the details of how this will work.
Creating the quantized graph for inference
We create the quantized inference graph in two steps. First, we do a pattern-based rewrite on the original graph to transform each pattern to the quantized inference version of that pattern. To do this rewrite, we need to have determined the values of scales and zero points.
The output of this rewrite will look very similar to the simulated quantized rewrite, however, the accumulation datatypes will be int32 instead of fp32, and we will insert qnn.quantize and qnn.dequantize instead of qnn.simulated_quantize and qnn.simulated_dequantize. After this transformation, the graph will look something like this:

Note that after the pattern-based rewrite, there will be portions of the graph that remain in real space. For example, all of the nn.relu ops in the graph pictured above are in real space and still operate on FP32 datatypes. However, to get the most speedup, we want to avoid operating in FP32 as much as possible.
To solve this problem, we’ll expand the regions of the graph that are in affine space by pushing qnn.quantize and qnn.dequantize through the surrounding ops. When we push qnn.quantize and qnn.dequantize through other ops, we will transform the other ops to be in affine space, if possible. To do this, we’ll have an allow_list, which is a mapping between a Relay op and how to transform it into affine space. If an op is not on the allow_list, we will not push a qnn.quantize or qnn.dequantize past it.
For example, consider moving qnn.quantize up past the first nn.relu in the graph above. This qnn.quantize has a scale s2 and zero point z2. To maintain correctness of the graph, we need nn.relu to take the shift by z2 into account. Therefore, we transform the nn.relu into max(z2, input).
Finally, we consolidate adjacent qnn.quantize and qnn.dequantize ops into qnn.requantize ops. Because we’ve moved the qnn.quantize ops and qnn.dequantize ops around, most of them should be adjacent. The only ops between qnn.quantize and qnn.dequantize should be ones not on the allowed_list, which cannot operate in affine space anyways.
The final graph will look like this:
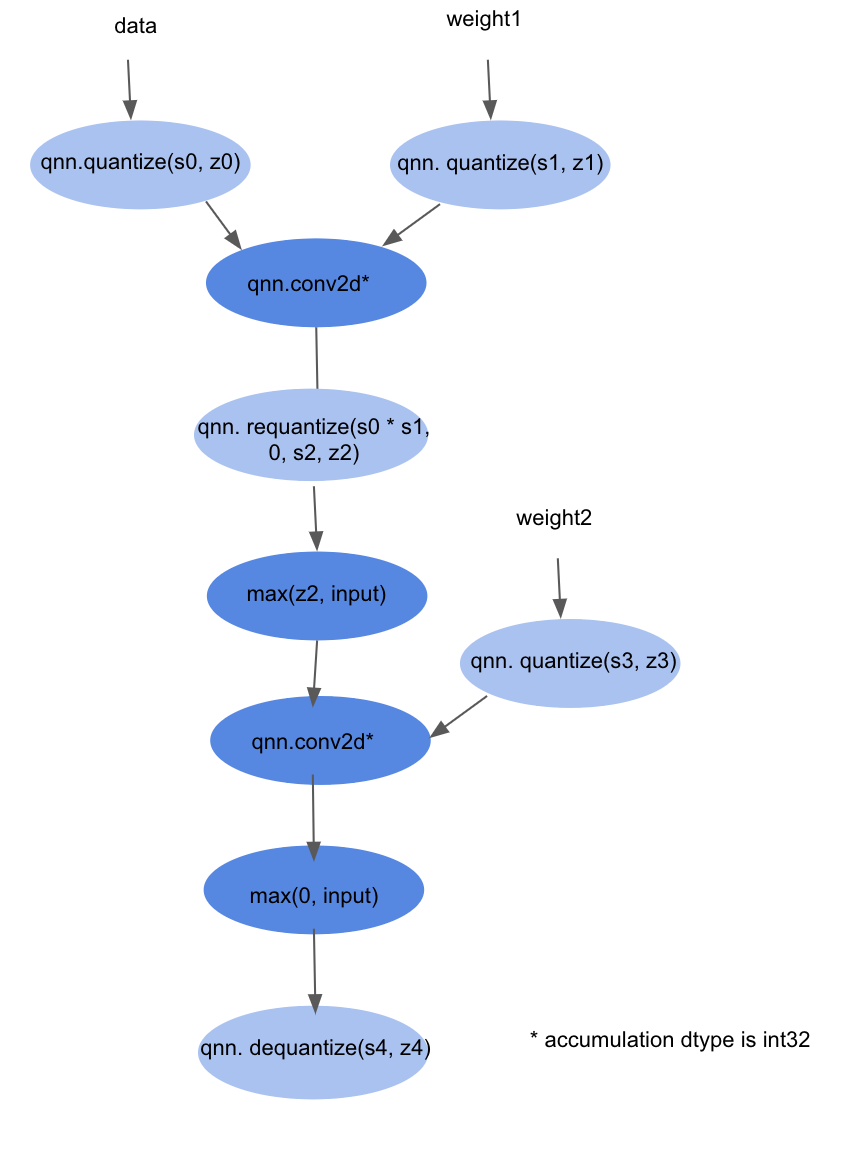
Please note that this rewrite is very complicated, and we have only provided a very brief overview of it here. There will be another RFC on this specifically to break down the steps involved.
Bottom-up approach versus top-down approach
The method we presented for quantizing graphs is a “bottom-up” approach. We do the local rewrites before doing the graph-level rewrites. Specifically, we decouple inserting qnn.requantize ops from the pattern-based rewrites.
Most existing quantization frameworks use a “top-down” approach-- they start with the global, graph level rewrite and do more local rewrites as they go.
There are benefits and drawbacks to both approaches.
A big benefit to the bottom-up approach is that it is more generic. We can easily add new patterns without changing the calibration methods and without changing the final rewrite that inserts qnn.requantize ops. In the top-down approach, we would need to embed the lower-level rewrite of patterns into the more global, graph based rewrite. This makes the top-down approach more ad-hoc less modular than the bottom-up approach.
One downside to the bottom-up approach is that we get slightly less control over the placement of qnn.requantize ops with respect to other QNN ops. Let’s consider an example: a hardware vendor wants to offload qnn.conv2d → qnn.requantize to an accelerator. Because we do not explicitly place the qnn.requantize op after the qnn.conv2d op, we have to rely on a separate pass to combine qnn.quantize and qnn.dequantize correctly, and to transform all ops in between them into affine space. Additionally, that pass has to put qnn.requantize in the correct spot relative to qnn.conv2d so that the pair of ops can be offloaded correctly.
We acknowledge that this logic is complex. However, in the top-down approach, we would have to implement similar logic that is similarly complex. Inserting qnn.requantize directly after patterns requires knowing the quantization parameters of the output tensor. In cases where the graph does not branch, this is not too difficult, but does force our rewrite to be less modular. However, if the graph branches, we have to figure out what the input quantization parameters are to all the branches, which requires global reasoning about the graph and its structure.
There are similar technical challenges in both approaches, and a top-down implementation would probably work just as well as a bottom-up implementation. We favor the bottom-up approach because it is more generic, modular and extensible.
Future RFCs
Each of the steps outlined above is complex, and we did not go into very much detail in this RFC. For readability and ease of communication there will be three more RFCs that go into more detail. One will correspond to each of the subsections of the “Outline of this Work” section, as these are the most complex parts of the framework:
- The pattern-based rewrites and updates to QNN
- Picking quantization parameters
- Creating the quantized inference graph and expanding affine spaces
Future work
In the future, we would like to support multi-precision quantization. We are specifically interested in allowing fallback to fp32 if quantizing a portion of the graph in int8 causes a large degradation in accuracy. And, we would like to add support for int4 quantization. Additionally, we would like to support dynamic quantization, as defined earlier in this RFC.
We have designed this framework with implementing multi-precision quantization and dynamic quantization in mind, so we will not have to do any major rework of the work presented here to support these features. However, we view these features as extensions of the work presented here, so a discussion of these features will not be included in the initial set of RFCs.
Thanks to @AndrewZhaoLuo, @mbrookhart and @masahi for helping edit this RFC