Currently, many of the unit tests loop over tvm.testing.enabled_targets() in
order to run on all targets being tested. While the
@tvm.testing.parametrize_targets decorator does allow for test results for
each target, it silently hides disabled targets, which can hide failing tests.
I propose parametrizing the unit tests across both target and array size
parameters, to improve the accuracy of the test reports. An implementation of
this is shown in PR#8010, along
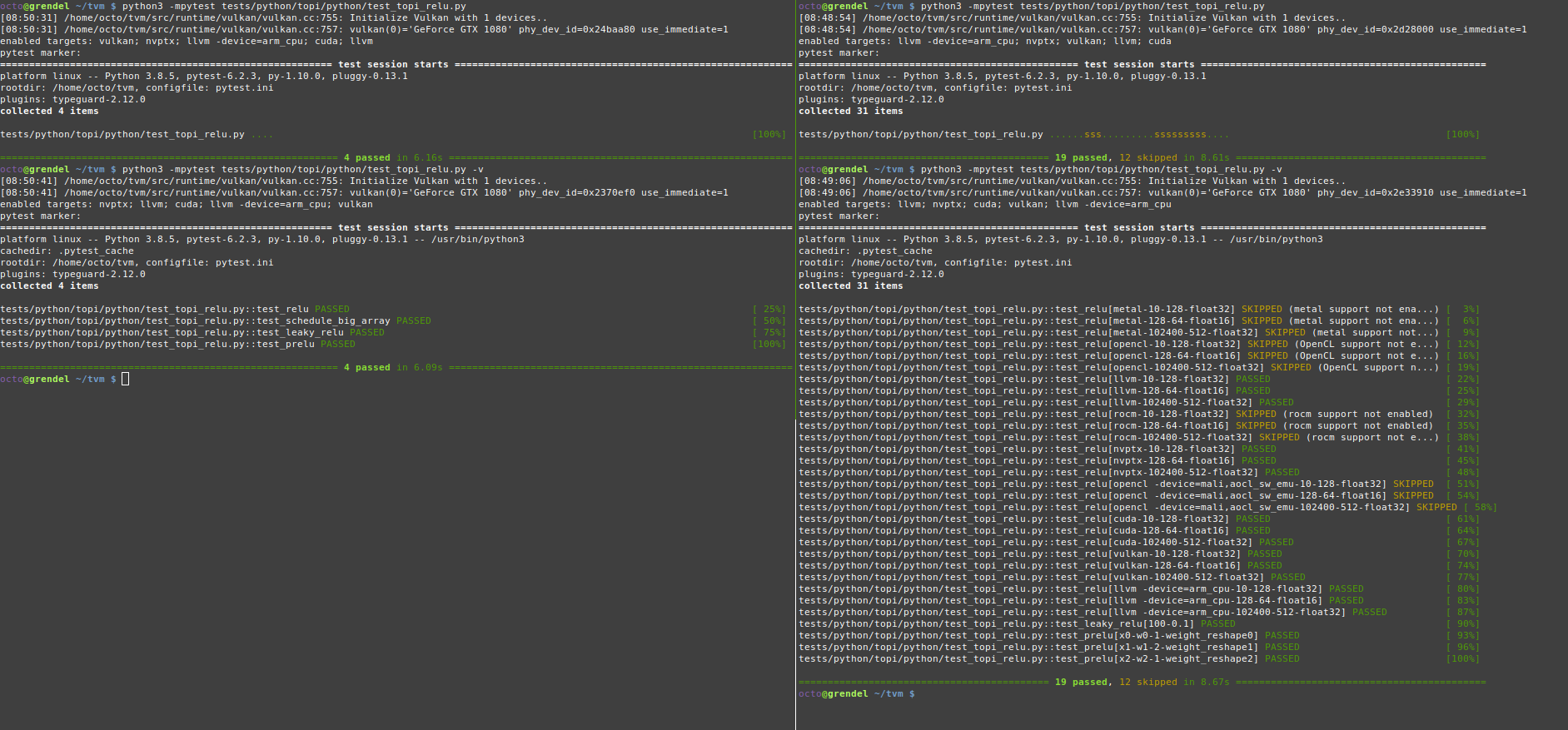
with a modified test_topi_relu.py that uses the new features. The pytest
output before (left) and after (right) are shown below.
# Frequently used in tests
def test_feature():
def verify_target(target, dev):
# do test code here
for target, dev in tvm.testing.enabled_targets():
verify_target(target,dev)
#Currently possible, but rarely used
@tvm.testing.parametrize_targets
def test_feature(target, dev):
# Do test code here
#Proposed standard
def test_feature(target, dev):
# Do test code here
If a test_* function accepts parameters target and dev, the test would
automatically be run on all enabled targets. Any targets that cannot be tested,
either because their compilation wasn’t enabled, or because no such physical
device exists, would be explicitly listed as skipped. This method also splits
up the single test_feature test into separate tests test_feature[llvm],
test_feature[cuda], and so on. Rather than indicating only a single
success/failure, splitting up the tests can indicate whether a bug lies within
the feature or within a specific runtime.
By making the default test behavior be to test on all targets specified in
TVM_TEST_TARGETS, it is harder for failing unit tests to be committed. For
example, currently several of the OpenCL unit tests fail. The current CI setup
runs tests with USE_OPENCL=OFF, and there is no indication printed that these
tests are being skipped.
If tests should run on all targets except some known subset (e.g. everything
except llvm), these exclusions can be specified with the new
tvm_excluded_targets variable. If this variable is specified in a test
module, either as a string or as a list or strings, then the targets listed will
be dropped entirely from those tests, and will not be displayed.
tvm_excluded_targets can also be specified in a conftest.py file to apply to
an entire directory, or applied to a single function with
@tvm.testing.exclude_targets. Alternatively the current behavior of
specifying explicit targets with
@tvm.testing.parametrize_targets('target1','target2') can be used.
It is expected both that enabling unit tests across additional targets may
uncover several unit tests failures, and that some unit tests may fail during
the early implementation of supporting a new runtime or hardware. In these
cases, the tvm_known_failing_targets variable or
@tvm.testing.known_failing_targets should be used instead of excluding the
targets altogether. These failing targets show up on the pytest report as being
skipped, whereas excluded targets do not show up at all. It is intended that
these act as a to-do list, either of newly exposed bugs to resolve, or of
features that a newly-implemented runtime does not yet implement.
Parametrization can be done for array size/shape parameters as well, with similar benefits to test visibility as for the target. The proposed test style below would indicate which of the three array sizes resulted in an error, rather than just a single success/failure for all three.
# Current test style
def verify_prelu(x, w, axis, weight_reshape):
# Perform tests here
assert(...)
def test_prelu():
verify_prelu((1, 3, 2, 2), (3,), 1, (3, 1, 1))
verify_prelu((1, 3, 2, 2), (2,), 2, (2, 1))
verify_prelu((1, 3), (3,), 1, (3,))
# Proposed test style
@pytest.mark.parametrize(
"x, w, axis, weight_reshape",
[
((1, 3, 2, 2), (3,), 1, (3, 1, 1)),
((1, 3, 2, 2), (2,), 2, (2, 1)),
((1, 3), (3,), 1, (3,)),
],
)
def test_prelu(x, w, axis, weight_reshape):
# Perform tests here
assert(...)
Once both the target and parameters are parametrized, this allows
target-specific tests to use pytest.skip. For example, the following check
for float16 support can be displayed as an explicitly skipped test.
# Current method
def verify_relu(m, n, dtype="float32"):
def check_target(target, dev):
if dtype == "float16" and target == "cuda" and not have_fp16(tvm.gpu(0).compute_version):
print("Skip because %s does not have fp16 support" % target)
return
# Run test
for target, dev in tvm.testing.enabled_targets():
check_target(target, dev)
@tvm.testing.uses_gpu
def test_relu():
verify_relu(10, 128, "float32")
verify_relu(128, 64, "float16")
# Proposed standard
@pytest.mark.parametrize(
"m, n, dtype",
[
(10, 128, "float32"),
(128, 64, "float16"),
],
)
def test_relu(target, dev, m, n, dtype):
if dtype == "float16" and target == "cuda" and not have_fp16(dev.compute_version):
pytest.skip("Skip because %s does not have fp16 support" % target)
# Run test
Though not part of the current proposed changes, this also opens the door for other improvements in the future.
- Using tests as benchmarks for cross-target comparisons, since each function call pertains to a single target.
- Fuzzing the parametrized values, potentially exposing edge cases.
- Profiling time required to run each test. If a small percentage of tests are taking the vast majority of time for the CI to run, these tests may be pulled out into nightly tests, allowing the per-pull-request CI to run faster.