What is a rolling buffer?
A rolling buffer (at least for the purposes of this RFC) is a buffer where one of the dimensions should be addressed via modulo arithmetic. This gives it a ‘wrap-around’ behaviour which makes it self-overwriting. This means they are effectively just higher dimensional circular buffers (circular in only a single dimension).
Motivation
With the introduction of uTVM, optimizing for memory usage becomes just as important as optimizing for performance. Therefore, it’s valuable to have scheduling primitives at our disposal which can be used to develop schedules that are both high performance and low memory usage.
I wrote an RFC a while ago now as to how scheduling could be used to reduce memory usage which you can read here: [RFC] 'Cascade' Scheduling. The basic premise of this is that if we have two operators A and B that have intermediate tensors like this:
1MB → A → 10MB → B → 1MB (where we represent only the size of the tensors)
We can see if we compute A entirely and then B, in both cases we need to hold 11MB in memory (to store the input and output tensors in full). However, if A and B are operations with some degree of spatial locality (like convolutions for example), we can tile and interleave the computations (using split and compute_at) such that only part of the intermediate 10MB tensor is ever realized at once. If by tiling we can use an intermediate buffer of half the size, we then have a graph that looks like
1MB → A → 5MB → B → 1MB
and even though all tensors must now be simultaneously live that reduces our working memory from 11MB to 7MB. More aggressive tiling can reduce the intermediate buffer size even further.
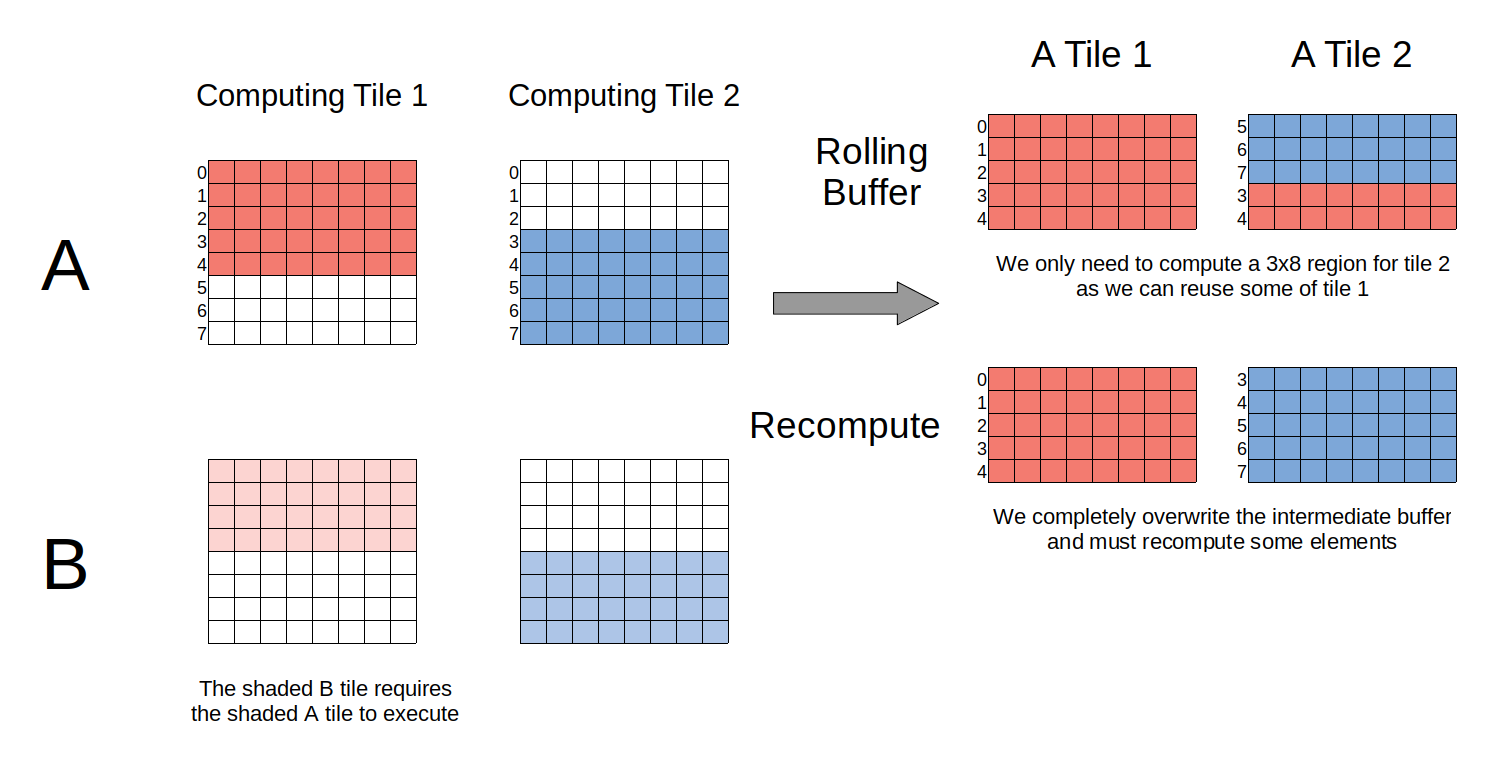
However, in TVM we currently pay a heavy penalty from doing this in terms of performance. This is because that intermediate buffer is overwritten for every tile but it may have contained some elements needed by the next tile. We therefore pay a ‘recompute’ penalty. This is where rolling buffers come in to play. By making the intermediate buffer rolling along a dimension we can support partial overwrite while retaining the overlapping region we’d otherwise need to recompute. I’ve attempted to demonstrate this with a diagram:
Implementation
The rolling buffer is implemented in two stages. The first is an analysis to perform the sliding window optimization (which removes the recompute) and the second is a storage folding transformation to circularize the buffer along the rolling dimension.
I have added the rolling_buffer primitive following a pretty much identical API to double_buffer which is a similar feature. The actual logic to lower a buffer so that it rolls is implemented as a TIR pass with the TE logic only tagging a buffer as ‘to-be-rolled’. Therefore, a new pass must be added to the TIR compilation pipeline, InjectRollingBuffer.
Here’s a quick example of using it:
A = te.placeholder((1, 12, 12, 16), name="A", dtype="int8")
pool_a = topi.nn.pool(A, (3, 3), (1, 1), (0, 0, 0, 0), "max", layout="NHWC")
pool_b = topi.nn.pool(pool_a, (3, 3), (1, 1), (0, 0, 0, 0), "max", layout="NHWC")
sch = tvm.te.create_schedule([pool_b.op])
n, h, w, c = pool_b.op.axis
oi, ii = sch[pool_b].split(w, 4)
sch[pool_a].compute_at(sch[pool_b], oi)
sch[pool_a].rolling_buffer()
You can find the PR (which includes more tests which demonstrate the intended usage) here: Add a 'rolling_buffer' scheduling primitive by mbaret · Pull Request #7925 · apache/tvm · GitHub.
Thanks for taking the time to read this, any thoughts/feedback are welcome!
 Regarding 1, this is a good point. Initially we were only intending to use rolling_buffer in our custom TIR lowering pipeline (doesn’t use driver_api.cc), but I agree it’d be much better to also include it in the standard flow. I’ll work on a patch to enable that.
Regarding 1, this is a good point. Initially we were only intending to use rolling_buffer in our custom TIR lowering pipeline (doesn’t use driver_api.cc), but I agree it’d be much better to also include it in the standard flow. I’ll work on a patch to enable that.