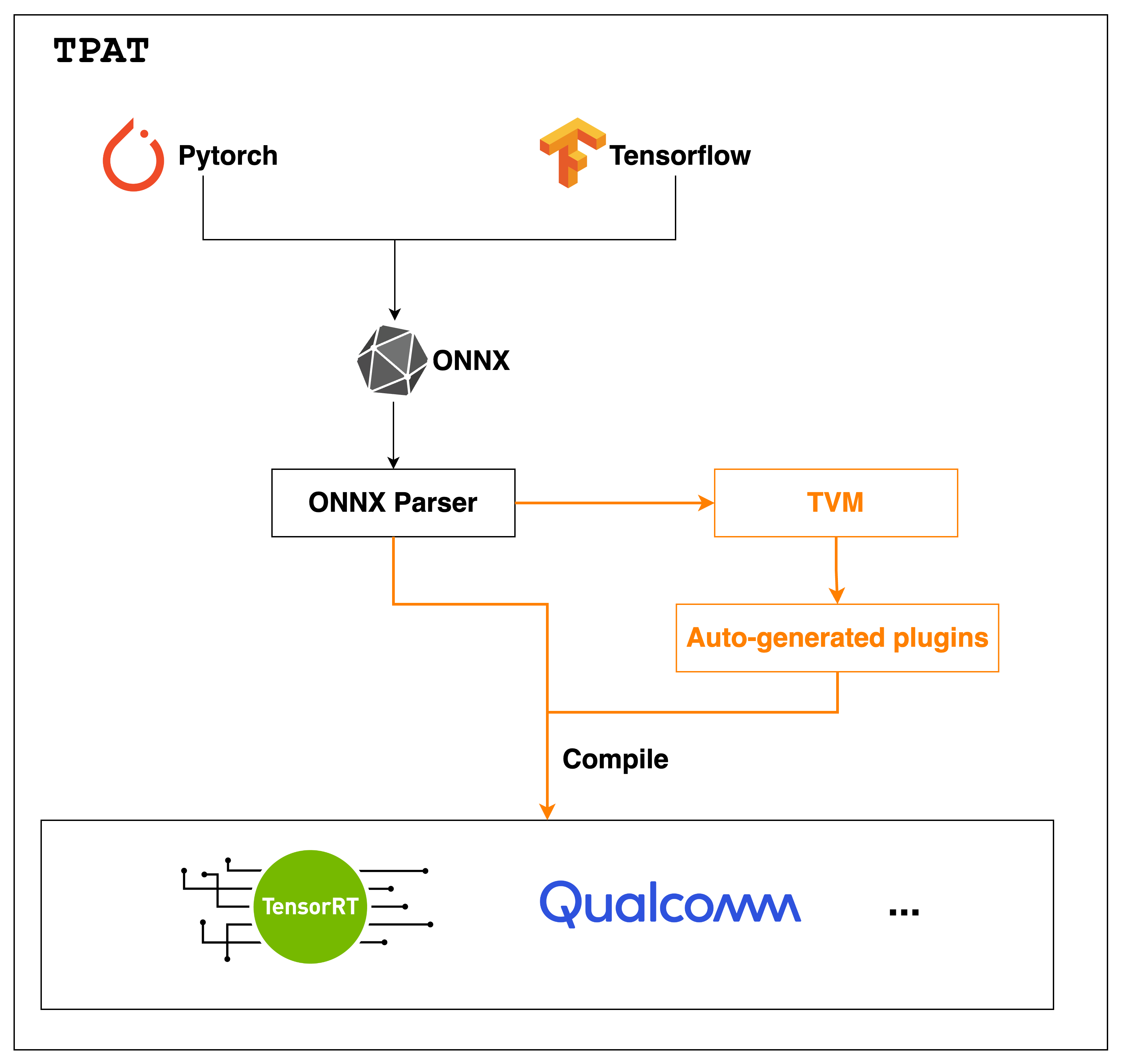
Summary
This RFC introduce TPAT, which stands for TVM Plugin Autogen Tool. It utilizes TVM to generate optimized plugins/extensions for vendor-specific acceleration library, in this way, we can effectively to combine the strengths of both TVM and vendor library to achieve optimal performance.
Motivation
Currently, the integration strategy between TVM and vendor library is to offload operators from Relay to vendor library. Ideally, this can provide a performance boost without the need to tune schedules. However, at practice, the partition strategy is not perfect now, I’ve noticed that as the number of subgraphs increases, the performance gap between this method and purely vendor library increases (I think one of the reasons is that an excessive number of subgraphs cannot fully utilize the L1/L2 cache, see issue). After some research, I find TPAT, which developed by Tencent and Nvidia, they also have a talk at TVMCon 2021, though they haven’t synchronized it with the upstream for a long time, but it’s an awesome idea, and it is here again!
Vendor-specific acceleration libraries like TensorRT, QNN often represent the state-of-the-art (SOTA) capabilities of their respective platforms. Additionally, both TensorRT and QNN provide the capability to incorporate user-defined operator implementations through plugins. Natuarally, By leveraging TVM to optimize specific operators and dynamically inserting them into the vendor’s acceleration library, it is believed that this approach can effectively combine the strengths of both TVM and the vendor-specific acceleration library to achieve optimal performance levels.
And you can see full RFC here: [RFC] Introduce TPAT (TVM Plugin Autogen Tool) by Civitasv · Pull Request #103 · apache/tvm-rfcs · GitHub.