
Motivation
In the current state, TVM float32 performance for armv8 architectures are comparable to frameworks like TFlite (that we will use as a reference through this RFC). However, our analysis shows that pre-quantized networks (i.e., when data and/or weights are transformed from float32 to int8 or uint8) are significantly slower than TFlite. The table below shows a summary for inception_v3:
| tuning | Threads | tflite/tvm | tvm/tflite |
|---|---|---|---|
| un-tuned | 1 | 0.3663 | 2.77 |
| tuned (x86 schedules)* | 1 | 0.4730 | 2.11 |
| tuned (x86 schedules)* | 4 | 0.6176 | 1.6 |
- Note that the x86 schedules are faster than native ARM ones
You can observe TVM is about 2x slower than TFlite in the single-thread case, and 60% slower than Tflite when multi-threading. We found that the main bottleneck is the convolution algorithm used: indeed, analyzing the heaviest convolution in isolation, we observed the same order of performance degradation.
The main goal of this RFC is to address this issue and provide a better convolution algorithm for pre-quantized networks.
Background
Let’s consider the convolution strategy that is currently used in topi.arm_cpu.conv2d_spatial_pack_nchw. The x86 schedule is similar, but it also packs the channels in batches to be more cache efficient (and indeed performance are slightly better). This is a NCHW convolution, which means that in order to run we need to alter the native NHWC layout of TFlite to NCHW.
The convolution is composed of three parts:
- Transform data and weights from
int8/uint8toint16. - Transform the input tensor (assuming that the weights have already been transformed by the alter_op pass). This is basically an Im2Col transformation, i.e., the output.
data_vecis transformed fromNCHWtoNCHW-KW-KH, whereKHandKWare(3,3)in this case. - The second is the actual compute. From a high level standpoint this algorithm executes the convolution by accumulating outer product of
1x16by16x1tile. Every element of the1x16data tile is replicated into a vector of 16 elements, element-wise multiplied by the16x1weight’s tile and accumulated. Since we transformed the data toint16we can safely use asmlainstruction (signed multiply accumulate) to implement this sort of multiplication/accumulation.
Proposal
The main question is: is this the best we can do without the dot-product instruction ?
Even if we don’t have the dot-product instruction in the base ISA, we still have integer specific instructions available in the AArch64 SIMD ISA:
- SADALP/UADALP: Signed/Unsigned add and accumulate long pairwise
- SMULL/UMULL: Signed/Unsigned Long Multiply
- SMULL2/UMULL2: Upper-half signed/unsigned Long Multiply
Those instructions (with the addition of ADDP - add pair) are sufficient to emulate a dot-product. Why this is important?
Because it gives us the possibility to remain in 8bit. We don’t need to convert the data to int16 before-hand. In turn, this means:
- Loading less data each time
- Doing more operation per data loaded (i.e., increasing the arithmetic computation of the convolution).
Convolution implementation strategy
As previously pointed out, in the original schedule in topi.arm_cpu.conv2d_spatial_pack_nchw, there is a data transformation very similar to Im2col. The core computation, instead, is very similar to a GEMM computation even though it seems coupled with some of the transformations to interleave the data (and the weights).
That stated, we made the following design choices:
-
We decided to explicitly use Im2Col + GEMM in our implementation (instead of implicitly using them as previously done). This is because a GEMM convolution is more modular. We can separately worry about computation and memory layout .
-
We picked a NHWC layout. This is because in NHWC we don’t need to col2im-transform the output (i.e., the output transform is mostly a reshape and can be in-lined). NHWC gives us also the option to avoid a
ConvertLayoutpass from TFlite. -
For now, we don’t introduce any tuning knobs. The idea is for now to provide a good-enough general gemm-convolution schedule. Later on, we will make the algorithm to adapt to different convolutions by adding the appropriate knobs.
-
We made the GEMM convolution structure very similar to Winograd (as opposed to Winograd, though, the number of operations is exactly the same of a direct convolution):
- Transform the Input (i.e., Im2Col + padding + interleave )
- Transform the weights (i.e., Reshape + padding + interleave + block_transpose)
- Execute GEMM
- Transform the output back (i.e., un-interleave + reshape)
The remaining part of this section is split in the following way:
- Core algorithm (whose implementation is done in assembly and exposed through tensorization)
- Input Transform
- Weight transform
- Output transform
Convolution core algorithm
Input: { a: 4xK slice of 8-bit elements of A, b': 4xK slice of 8-bit elements of B}
Output: c: a 4x4 block of 32-bit elements, such that c = a * b
Notes:
- This is GEMM, we don’t care about strides, dilation, layout, etc… They are addressed in the Im2Col transformation.
- the
4xKofb'is aKx4slice transposed (more about this later) - We assume that
Kis a multiple of 16 (if not, we need to pad the matrixAandB)
Let’s go through the pseudo-code steps to compute the first row of c, c[0, 0:4]. Remember that c[j,i] = sum(a[j, 0:K].*b[i,0:K])
for k = 0:16:K
v0 = a[0, k:k+16] // a0
v4 = b[0, k:k+16] // b0
v5 = b[1, k:k+16] // b1
v6 = b[2, k:k+16] // b2
v7 = b[3, k:k+16] // b3
// Lower-part mul
v8.8h = umull(v0.8h, v4.8h) // v8 = a0[8:16].*b0[8:16]
v9.8h = umull(v0.8b, v5.8b) // v9 = a0[8:16].*b1[8:16]
v10.8h = umull(v0.8b, v6.8b) // v10 = a0[8:16].*b3[8:16]
v11.8h = umull(v0.8b, v7.8b) // v10 = a0[8:16].*b4[8:16]
// Accumulate
v16.4s = uadalp(v8.8h) // v16[0:4] = [v8[0:2]+v8[2:4],
// v8[4:6] + v8[6:8],
// v8[8:10] + v8[10:12],
// v8[12:14] + v8[14:16]
v17.4s = uadalp(v9.8h) // same as above with v9
v18.4s = uadalp(v10.8h) // same as above with v10
v11.4s = uadalp(v11.8h) // same as above with v11
// Higher-part mul
v8.8h = umull2(v0.8h, v4.8h) // v8 = a0[0:8].*b0[0:8]
v9.8h = umull2(v0.8b, v5.8b) // v9 = a0[0:8].*b1[0:8]
v10.8h = umull2(v0.8b, v6.8b) // v10 = a0[0:8].*b3[0:8]
v11.8h = umull2(v0.8b, v7.8b) // v10 = a0[0:8].*b4[0:8]
// Accumulate again
v16.4s = uadalp(v8.8h)
v17.4s = uadalp(v9.8h)
v18.4s = uadalp(v10.8h)
v11.4s = uadalp(v11.8h)
end
// At this point:
// v16 contains the four partial sums of a[0, 0:K].*b[0,0:K], let's call them (a,b,c,d)
// v17 contains the four partial sums of a[0, 0:K].*b[1,0:K], let's call them (e,f,g,h)
// v18 contains the four partial sums of a[0, 0:K].*b[2,0:K], let's call them (i,j,k,l)
// v19 contains the four partial sums of a[0, 0:K].*b[3,0:K], let's call them (m,n,o,p)
// Let's try to accumulate everything in v16
v16.4s = addp(v16.4s, v17.4s) // v16 = (a+b, c+d, e+f, g+h)
v17.4s = addp(v18.4s, v19.4s) // v17 = (i+j, k+l, m+n, o+p)
v16.4s = addp(v16.4s, v17.4s) // v16 = (a+b+c+d, e+f+g+h, i+j+k+l, m+n+o+p)
// Now v16 contains the sum(a[0, 0:K].*b[i,0:K]) for i =0, 1, 2, 3
c[0:4] = v16
The same algorithm can be repeated for the other rows of the c buffer.
Some points worth noticing:
- The block we choose
(4,4)is forced by the number of registers we have (32). - Optimizing the register allocations is not trivial. We first need to compute
c[0, 0:4]andc[1,0:4](first half) and thenc[2,0:4],c[3,0:4](second half) in order to not run out of registers. - If we are sure that
255*255+255*255never appears as accumulation (e.g., if the weights are quantized over 0:254) we can save the intermediateuadalp(i.e., the accumulation). We can doumull→umlal2→uadalp. TFlite uses this assumption, but converts before-hand to int8 (which means that-128*-128 + (-128*-128)never appears), thus using a sequence ofsmull→smal2→sadalp. We might use this as a--fast-mathoption. - The dot-product would simply ease the register pressure. Basically, instead of doing a
4x4block, we can do a12x4block because we don’t need intermediate registers to save the accumulations. - We implement this algorithm through inline assembly that we inject directly in TVM through
tensorize.
Input transform
Remember the input shape is of the form : (batches, IH, IW, IC), the output shape is (batches, OH, OW, OC), while the weight shape is: (KH, KW, KI, KO). The relation between input/weights/output shapes can be found here
Input transform means getting the data ready for GEMM. The input is transformed in two stages: Im2Col + Interleaving
Im2Col
I won’t delve into this, as this is a very known transformation (for instance, see here). It’s important to notice that padding, dilation and strides are all considered by this transformation. The result is A, an (M,K) matrix where M=OH*OW, N = KH*KW*IC.
Interleaving (or array packing)
Interleaving is the common process of placing elements accessed by gemm close to each other (instead that strides away). The following picture shows how we interleave the matrix A.
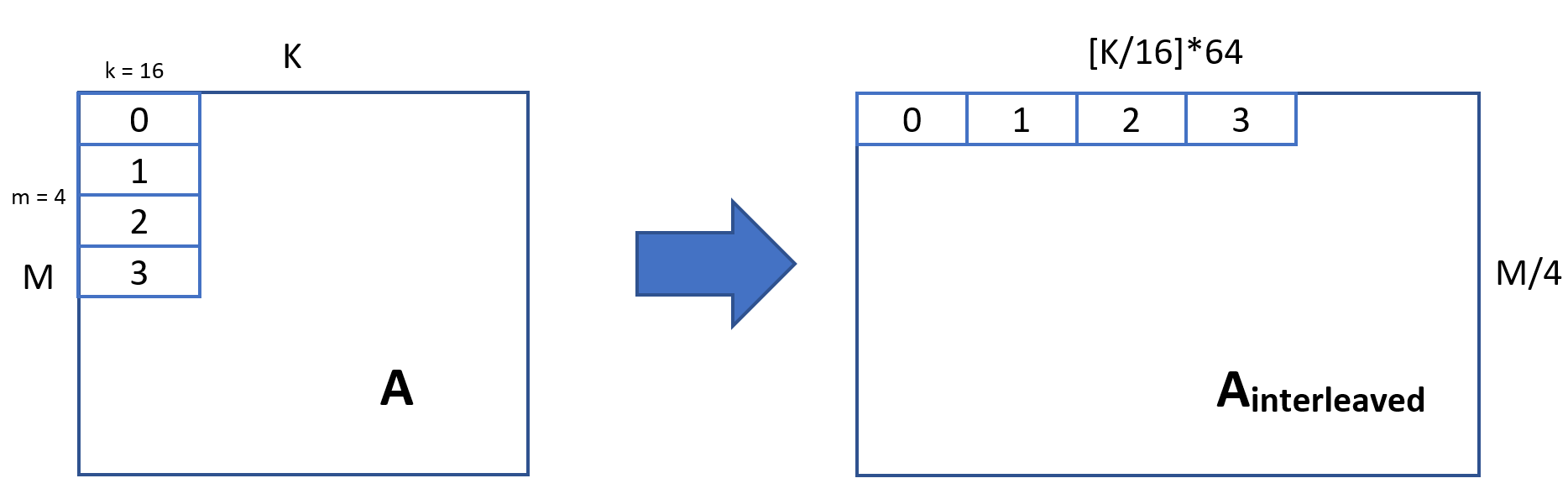
Note that we need to be sure that the input dimensions (M,N) are multiple of 4 and 16, respectively. We achieve that by padding the image.
The compute node that we use to achieve this sort of transformation is the following:
A_interleaved = te.compute((batches, M_padded // 4, K_padded // 16, 4, 16), lambda b, x, y, z, w: A[b, z + 4 * x, w + 16 * y], name='A_interleaved')
So now A_interleaved is a [M//4, K//16, 4, 16] tensor where A[0, 0, :, :] represents the 0,0 block A[0,1,:,:] represents the (0,1) block and so on. This is very similar to the one described in the GEMM tutorial.
Weight transform
Weight transform means getting the weights ready for GEMM. The weights are transformed in multiple stages: Flattening + Interleave_transpose
Flattening
In the case of the weights, we don’t need any im2col. We only need to flatten a [KH,KW,KI,KO] tensor into a [KH*KW*KI,KO]. This requires a very simple compute node, which can be easily in-lined.
Interleaving and block-transposing
The weight transform is slightly different from the Input transform (and from the traditional array packing) since we want to transpose the blocks in order to execute the pseudo-dot-product algorithm described above.
The idea of the transformation is described in the following image:

As you can see, we move from a [K,N] matrix to a [N/4, K/16, 4, 16] matrix, de facto transposing each block of the input image. Also in this case, if K or N are not multiple of 16 and 4, we need to pad B.
The compute node we use to implement this transformation is the following:
B_interleaved_t = te.compute((N_padded // 4, K_padded // 16, 4, 16), lambda x, y, z, w: kernel_flat[w + 16 * y, z + 4 * x], name='weight_block_reshape')
As well as the Input Transform case, B_interleaved_t is a [N/4,K/16,4,16] tensor, but in this case the block B_interleaved_t[0,0,:,:] is the first 4x16 block of B' (i.e., B transposed).
One last thing to note is that we can offload the weight transformation, since the weights are known at compile time. So all the flattening, interleaving and reshaping will happen before the graph is executed.
Output transform
Lastly, we need to transform our GEMM output. Those transformations are a bit simpler than the ones on the inputs and the weights.
The output from gemm is a [batches, M//4,N//4, 4, 4] tensor and there are two separate transforms that need to happen: Unpacking + Unflattening
Unpacking
We need to reshape the output back to a plain matrix [batches, M, N]. This is achieved by the following intuitive compute node:
C = te.compute((batches, M, N), lambda b, x, y: C_interleaved[b, x // 4, y // 4, idxm(x, 4), idxm(y, 4)], name=“C”, tag=‘injective’)
One nice thing to note is that we can declare the node as ‘injective’. This means that other injective-transformations can be attached to this one. Those other transformations can be for instance the requantize steps (shift, add, sum, mul, etc…).
Unflattening
Remember that our output C is now a [batches, M, N] = [batches, OH*OW, OC] matrix. Since we are working in NHWC we only need to unflatten the shape. This transformation will be later computed_at the unpacking transformation showed above. The simple node to do the unpacking is the following:
C = te.compute((batches, M, N), lambda b, x, y: C_interleaved[b, x // 4, y // 4, idxm(x, 4), idxm(y, 4)], name="C", tag='injective')
Results
We added a row to the original table that shows the improvements we obtained by using the GEMM schedules for inception_v3:
| tuning | Threads | tflite/tvm | tvm/tflite | Improvement |
|---|---|---|---|---|
| un-tuned | 1 | 0.3663 | 2.77 | |
| tuned (x86 schedules) | 1 | 0.4730 | 2.11 | |
| tuned (x86 schedules) | 4 | 0.6176 | 1.6 | |
| untuned( GEMM schedules) | 1 | 0.9541 | 1.05 | ~2x |
| untuned( GEMM schedules) | 4 | 0.93 | 1.07 | ~1.55 |
As you can see from the table, by using the new GEMM schedule we are comparable to TFlite performance and gained a 2x and 50% speed-up for the single thread and the multi-thread case, respectively.
PR
The PR for this RFC is here. The PR also contains an high level description of how the code is structured.
CC: @ramana-arm, @anijain2305, @janimesh