Motivation:
Auto-scheduler (Ansor) uses code sketch and optimization rules to generate a large search space. The search space defined by Ansor has shown great opportunities and therefore the search quality and the search efficiency are determined by how we search the space.
Ansor utilizes improved cost model and task scheduler to help explore the search space. The cost model analyzes and finds high-performance code transformations in the search space and the task scheduler allocates the time budget to different computation graphs. However, we find serval drawbacks to this approach:
-
The accuracy of the cost model determines the search quality, but Ansor uses monolithic cost model to predict different computation graphs (subgraphs), resulting in an accuracy loss during tuning.
-
The task scheduler allocates most of the time budget to subgraphs with most improving potential (i.e., those with the highest latency). This approach works well at the beginning of the autotuning. However, as the potential subgraph gradually reaches its peak performance with adequate time budget, other subgraphs have little time budget to reach its peak performance.
The search process will at the end take a dozen of hours. This motivates us to find better way to explore the search space.
Solution:
We implement FamilySeer. A new search method to improve the search process of Ansor.
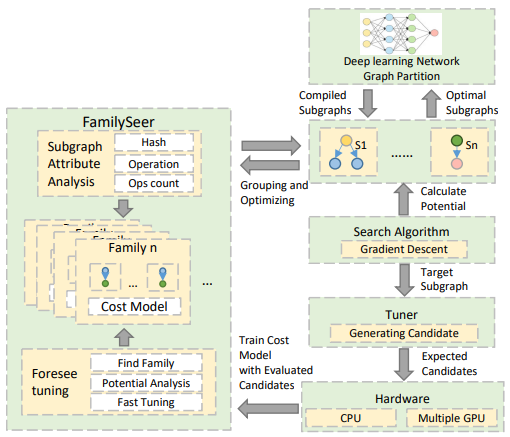
The overview of FamilySeer is shown above. FamilySeer has two key features:
- FamilySeer analyzes the similarity between subgraphs. The similarity can be described as the accuracy among subgraphs. Then we group these subgraphs into a subgraph family. The subgraph inside the family shares the same cost model to have better accuracy.
- When the cost model is updated during the search, we can foresee the subgraphs inside the same family using the highly accurate cost model. We use the cost model to find the exact high-performance code transformation instead of evaluate each code transformation, meaning no more costly tuning has to be done.
We evaluate our method and Ansor from both the search efficiency and the search quality.The search efficiency can be described as how much time has been used before reaching an optimal latency, and the search quality is directly related to the latency. We choose serval representative deep learning models like (Resnet, Mobilenet, Bert, Roberta, GPT2 and Vision Transformer) and evaluate them on Both CPU and GPU. We achieve an average speedup of 2.49x and 3.04x on search efficiency, respectively. We also achieve an improvement up to 1.14x on search quality.
More details and experiment results can be found in this paper.
How to use:
The code was based on TVM 0.8(Commit: 64𝑐1𝑏79) so we are trying to move the code to the master. We integrated our method inside Ansor so we can simply change the search_policy parameter to activate our approach.
tuner = auto_scheduler.TaskScheduler(
tasks, task_weights, load_log_file=log_file)
tune_option = auto_scheduler.TuningOptions(
num_measure_trials=900 \* (len(tasks) + 1), # change this to 20000 to achieve the best performance
runner=ctx_list[0].runner,
measure_callbacks=[auto_scheduler.RecordToFile(log_file)],
)
tuner.tune(tune_option,search_policy="sketch.xgb.family_op") # Changing the search_policy from “sketch.xgb” to “sketch.xgb.family_op”
Comments are appreciated.
