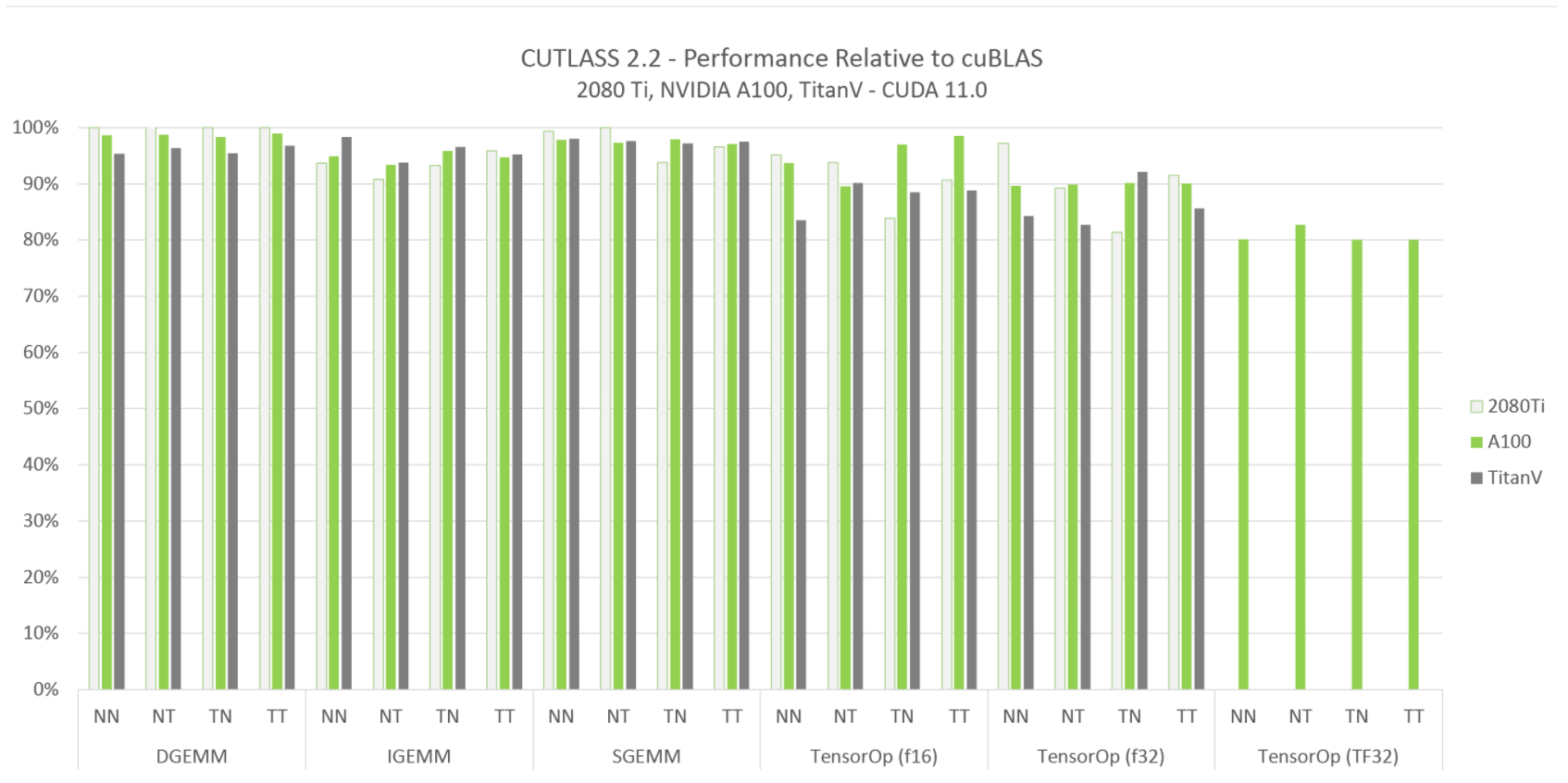
Currently, the GEMM schedules searched by TVM auto scheduler on NVIDIA GPUs have some big performance gaps compared with NVIDIA CUTLASS library (benchmark table shown below). For each new shape, TVM needs to tune for some time for the best schedule which is very insufficient for dynamic shape models. Another drawback of current solution in TVM auto scheduler is that it doesn’t have good support for NVIDIA Tensor Core instructions on different data types. To bridge the gaps between the GEMM performance of TVM and SOTA library cuBLAS, and Convolution performance of TVM and CUDNN, I propose to bring CUTLASS to TVM codegen and take the advantage of its ability to do operation fusion to potentially match/outperform the performance of models using cuBLAS. NVIDIA CUTLASS is an open source project and is a collection of CUDA C++ template abstractions for implementing high-performance matrix-multiplication (GEMM), and Convolution at all levels and scales within CUDA. It incorporates strategies for hierarchical decomposition and data movement similar to those used to implement cuBLAS. Based on NVIDIA’s official performance benchmark, CUTLASS can reach above 80% of CUBLAS performance on all workloads and can outperform cuBLAS on some workloads (figure from CUTLASS github shown below). By integrating CUTLASS into TVM, we get the following benefits:
For GEMM/Convolution kernels alone, we will speed up the current best TVM schedule tuned by auto-scheduler to above 80% of CUBLAS performance.
We have the potential to match TensorRT performance because we support op fusion by integrating CUTLASS in TVM while CUBLAS doesn’t.
We will support Tensor Core instructions for various data types.
Currently TVM needs a tophub database to store tuned schedules for all kinds of shapes. And when given a shape which hasn’t been searched before, it will take several hours to search or offloaded to the default schedule which is super slow. While using CUTLASS, we have a compiled 7G lib ready, which supports all kinds of shapes & data types with stable optimal performance. This will solve the dynamic shape issue of TVM.
Thanks @Laurawly for the proposal. I agree this is something that is good to have as they brings the best of all worlds.
Looking at the MNK=2048 benchmark. It seems to suggest a limitation in the auto-scheduler’s search space construction (the hand written topi recipie gets to closer to peak about 80-90% of cublas on titan X).
In complementary to this effort, we will also explore the possibility to utilize the primitives in cutlass, including those for the FMA computation and memory move via tensorization. So see if we can leverage these sub-functions in different finer-grained levels, eventually bringing the insights from cutlass to auto-scheduling.
Glad to hear the plans to bring the insights of cutlass to auto-scheduling/TIR and look forward for the performance of the strategies applied on other hardware. For this proposal, I think the advantage reflects in Nvidia GPUs. Compared with the auto plan, this method can eliminate the overhead of tuning since cutlass already contains implementations for various SMs of NV GPUs, tensor core wmma instructions sets and all kinds of shapes for the computation.
Thanks for the RFC! I love the performance benefits that BYOC + CUTLASS brings!
The matmul numbers look really cool! Just curious, since I believe these are workloads well supported by cuBLAS, what are the cuBLAS numbers? Do they work better than cutlass?
Yeah the 7GB library looks acceptable if we are running on a server class machine…Is that a library of N * M * K matmul of all the shapes (with an uplimit), types, SMs, etc?
Thanks for this proposal and the number looks promising. I’m curious about the performance comparison between this solution VS TVM + TensorRT. What are the pros and cons?
First off, thanks for the RFC and the initial numbers!
Apologies if this question is naive but my understanding of BYOC means that a user needs to then decide to globally use CUTLASS or TVM codegen for their entire workload. On the other hand, if CUTLASS was integrated as another GEMM strategy instead (how I think cuDNN, and other BLAS libraries are integrated today), wouldn’t TVM compilation be able to choose between CUTLASS and other strategies per op instead of globally? Resulting in more potentially more flexibility and performance?
We should admit that TVM never gives the best performance on large GEMM.
But we could typically achieve around 80% of the cuBLAS performance. I did some benchmarks on AWS p3.2xlarge instance (v100) and AWS g4 instance(T4) with Deep Learning AMI.
Spec: fp32, MNK = 2048, no tensor core
library
V100
T4
cuBLAS
13.96 TFLOPS
3.58 TFLOPS
Ansor
11.96 TFLOPS
3.24 TFLOPS
From the table, we can see Ansor achieves 85% and 90% of cuBLAS performance on Volta gpus. Do you know why the gap is much larger on Ampere gpus? Do you have scripts to reproduce your results so I can help to verify and debug ansor?
In regards to this RFC, this is a great step. We should definitely integrate this library to fix the current limitation of TVM.
Here are the steps to verify the benchmark
clone and build this branch GitHub - merrymercy/tvm at bench_cublas with cuBLAS enabled in config.cmake. The change in src/runtime/contrib/cublas/cublas.cc is required to disable tensor core.
run tvm/tutorials/auto_scheduler/bench_cublas.py and tvm/tutorials/auto_scheduler/bench_ansor.py. No tuning is required. The tuning log is also uploaded into the repo.
Thanks for the RFC. It looks really interesting. Are we only targeting convolution and GEMM operators? If so, can we add them to the op strategy as @jknight mentioned instead of adding it as a backend of BYOC? That would be easier. What is the fusion strategy here? Are we targeting merge a sequence of operations (i.e. conv+add+relu) to a single API? Thanks.
Thanks for your questions. I’ll update more numbers with cublas later. Cutlass doesn’t have dependent on shapes, it has stable optimal performance for all kinds of shapes for both GEMM and conv. And its template has slight difference for different SMs or instructions which you can reference its open source code for better details: GitHub - NVIDIA/cutlass: CUDA Templates for Linear Algebra Subroutines
Thanks for your suggestions. I’ll do some benchmark with BYOC TRT once we have some initial results. I would expect the acceleration coming from more fusion compared with BYOC TRT since cutlass can support epilogue code generation for TVM to fuse.
Thanks a lot for your question! I believe that BYOC supports annotating different ops using different codegen cutlass/cublas/cudnn instead of globally using the same one(@zhiics plz correct me if I’m wrong). Regarding performance, because the libraries you mentioned are all managed by Nvidia which they actively update, I believe for singe kernel performance, they won’t vary much. Bringing cutlass codegen is aim to introduce more graph-level optimization, in this case more fusion which TVM is good at.
Glad to see the RFC! TVM performance on large gemm has troubled me for a long time. Looking forward to further benchmark on cutlass+fusion against cublas+nofusion.
One potential issue: autotvm selects the best implement from autotuned-gemm and cublas-gemm based on performance, then do the fusion. If cutlass is integrated, we need to select sub-graph level autotuning and then select the best.
Like others already mentioned, integrating Cutlass via BYOC makes it at a graph level instead of tensor level. As a result, Relay op strategy and AutoTVM, Ansor won’t be able to consider this implementation along with others such as CUDA or CuBLAS. However, as @Laurawly pointed out, introducing Cutlass is mainly for graph-level optimization (i.e., fusion), and this cannot be done at the TE level at this moment, so the motivation is similar to the TensorRT integration.
Given the above summary, it seems to me that we could have several stages of bringing Cutlass in general:
Integrate Cutlass via BYOC for now. Users have to decide if they want to offload as many ops as possible to Cutlass. As a result, the flow becomes:
Relay: For a whole graph, choose between Cutlass or others.
TE/TIR: For the rest graph (a.k.a. others), choose between CUDA, CuBLAS, CuDNN, etc.
When TensorIR is landed, we should be able to leverage its tensorization rules to make use of Cutlass microkernels in codegen. In this way, we could have more possibilities to boost the performance, because Cutlass becomes transoized intrainsics in the generated kernels. cc @vinx13
Once (2) is available, the corresponding auto-scheduler, AutoTIR, should be able to tune the schedule with Cutlass kernels. cc @junrushao
Stage (2) and (3) enable more interesting research opportunities in TVM fusion strategies. As for now, we only fuse simple patterns (e.g., a reduction op with following injective ops). We can explore how Cutlass could make more fusion patterns useful.
Since stage 2-4 need more tiem to land, making stage 1 available soon is a pretty good idea to me.
Thanks for your great summary! Just one thing to point out is that cutlass is not composed of microkernels, but instead a collection of CUDA C++ template abstractions. I also look forward for the outcome of bringing the core insight of cutlass to TIR
As requested, I just tested square GEMM as well as Bert workloads with batch size 64, sequence length 128 on RTX3090 between cublas and cutlass, and here’s the result (note that cutlass’s output is in fp16 because by default, it generates the same data type with the input):
This is exciting stuff!! CUTLASS team will be happy to answer any questions here.
The output datatype doesn’t match so this is not a fair comparison. I think might have only looked into CUTLASS device-level unit tests. You should use CUTLASS generator to procedurally generate GEMMs or convolutions for datatypes you are interested in.
A few bullets to help you run this analysis better:
Use CUTLASS generator and profiler to generate and profile CUTLASS GEMM kernels of interest: